
...making Linux just a little more fun!
Ben Okopnik [ben at linuxgazette.net]
I've always been curious about the huge disparity in file sizes between certain images, especially when they have - oh, more or less similar content (to my perhaps uneducated eye.) E.g., I've got a large list of files on a client's site where I have to find some path between a good average image size (the pic that pops up when you click the thumbnail) and a reasonable file size (something that won't crash PHP/GD - a 2MB file brings things right to a halt.)
Here's the annoying thing, though:
ben at Jotunheim:/tmp$ ls -l allegro90_1_1.jpg bahama20__1.jpg; identify allegro90_1_1.jpg bahama20__1.jpg -rwxr-xr-x 1 ben ben 43004 2010-09-28 19:43 allegro90_1_1.jpg -rwxr-xr-x 1 ben ben 1725638 2010-09-28 14:37 bahama20__1.jpg allegro90_1_1.jpg JPEG 784x1702 784x1702+0+0 8-bit DirectClass 42kb bahama20__1.jpg[1] JPEG 2240x1680 2240x1680+0+0 8-bit DirectClass 1.646mb
The first image, which is nearly big enough to cover my entire screen, is 42k; the second one, while admittedly about 3X bigger in one dimension, is 1.6MB+, over 40 times the file size. Say *what*?
And it's not like the complexity of the content is all that different; in fact, visually, the first one is more complex than the second (although I'm sure I'm judging it by the wrong parameters. Obviously.) Take a look at them, if you want:
http://okopnik.com/images/allegro90_1_1.jpg http://okopnik.com/images/bahama20__1.jpg
So... what makes an image - seemingly of the same type, according to what "identify" is reporting - that much bigger? Does anybody here know? And is there any way to make the file sizes closer without losing a significant amount of visual content?
-- * Ben Okopnik * Editor-in-Chief, Linux Gazette * http://LinuxGazette.NET *
[ Thread continues here (22 messages/37.41kB) ]
Jimmy O'Regan [joregan at gmail.com]
Tesseract, the Open Source OCR engine originally created at Hewlett-Packard and now developed at Google, has released a new version.
Tesseract release notes Sep 30 2010 - V3.00 ?* Preparations for thread safety: ? ? * Changed TessBaseAPI methods to be non-static ? ? * Created a class hierarchy for the directories to hold instance data, ? ? ? and began moving code into the classes. ? ? * Moved thresholding code to a separate class. ?* Added major new page layout analysis module. ?* Added HOCR output. ?* Added Leptonica as main image I/O and handling. Currently optional, ? ?but in future releases linking with Leptonica will be mandatory. ?* Ambiguity table rewritten to allow definite replacements in place ? ?of fix_quotes. ?* Added TessdataManager to combine data files into a single file. ?* Some dead code deleted. ?* VC++6 no longer supported. It can't cope with the use of templates. ?* Many more languages added. ?* Doxygenation of most of the function header comments.
As well as a number of new languages, bugfixes, and man pages.
Languages supported are: Bulgarian, Catalan, Czech, Chinese Simplified, Chinese Traditional, Danish, Danish (Fraktur), German, Greek, English, Finnish, French, Hungarian, Indonesian, Italian, Japanese, Korean, Latvian, Lithuanian, Dutch, Norwegian, Polish, Portuguese, Romanian, Russian, Slovakian, Slovenian, Spanish, Serbian, Swedish, Tagalog, Thai, Turkish, Ukrainian, Vietnamese
-- <Leftmost> jimregan, that's because deep inside you, you are evil. <Leftmost> Also not-so-deep inside you.
Ben Okopnik [ben at linuxgazette.net]
Hello, Gang -
After a number of years of providing hosting services for LG (and a number of others), our old friend T. R. is, sadly, shutting down his servers. Whatever his plans for the future may be, he has my best wishes and the utmost in gratitude for all those great years; if there was such a thing as a "Best Friends and Supporters of LG" list, he'd be right at the top.
(T.R. - if we happen to be in the same proximity, the beer's on me. Yes, even the realy good stuff.)
I've arranged for space on another host, moved the site over to it, and have just finished all the configuration and alpha testing. Please check out LG in its new digs (at the same URL, obviously), and let me know if you find any problems or anything missing.
-- * Ben Okopnik * Editor-in-Chief, Linux Gazette * http://LinuxGazette.NET *
[ Thread continues here (9 messages/13.03kB) ]
Prof. Parthasarathy S [drpartha at gmail.com]
Is there a neat way to export and save my GPG/PGP secret key (private key) on a USB stick ?
I have to do this, since I am often changing my machines (most of which are given on loan by my employers). The secret key goes away with the machine, and I am obliged to generate a new key pair each time. I did a Google search and did not succeed.
I know I can save/export my public key, but GPG/PGP refuse to let me use a copy of my secret key.
Any hint, or pointers would be gratefully appreciated.
Many thanks,
partha
-- ------------------------------------------------------------------- Dr. S. Parthasarathy | mailto: drpartha at gmail.com Algologic Research & Solutions | 78 Sancharpuri Colony, Bowenpally P.O.| Phone: + 91 - 40 - 2775 1650 Secunderabad 500 011 - INDIA | WWW-URL: http://algolog.tripod.com/nupartha.htm My personal news bulletins (blogs) :: http://www.freewebs.com/profpartha/myblogs.htm -------------------------------------------------------------------
[ Thread continues here (3 messages/2.96kB) ]
Mulyadi Santosa [mulyadi.santosa at gmail.com]
Sometimes, people are scared to get a screw driver and check what's inside the hard drive. Or maybe simply because we're too lazy to read manuals.
So, what's the alternative? How about a simple flash based tutorial? http://www.drivesaversdatarecovery.com/e[...]-first-online-hard-disk-drive-simulator/
It's geared toward disaster recovery, but in my opinion it's still valuable for anyone who would like to see how the hardware works.
PS: Thanks to PC Magazine which tells a short intro about the company: http://www.pcmag.com/article2/0,2817,2361120,00.asp
-- regards,
Mulyadi Santosa Freelance Linux trainer and consultant
blog: the-hydra.blogspot.com training: mulyaditraining.blogspot.com
[ Thread continues here (5 messages/9.55kB) ]
Ben Okopnik [ben at linuxgazette.net]
I don't know why this kind of thing keeps coming up. I never wanted to be
a mathematician, I'm just a simple programmer! 
(One of these days, I'm going to sail over to an uninhabited island and stay there for six months or so, studying math. This is just embarassing; any time a problem like this comes up, I feel so stupid.)
I've been losing a lot of weight lately, and wanted to plot it on a chart. However, I've only been keeping very sparse records of the change, so what I need to do is interpolate it. In other words, given a list like this:
6/26/2010 334 8/12/2010 311.8 8/19/2010 308.4 9/5/2010 300.0 9/9/2010 298.6 9/14/2010 297.2 9/16/2010 293.6
I need to come up with a "slope" function that will return my weight at any point between 6/26 and 9/16. The time end of it is no problem - I just convert the dates into Unix "epoch" values (seconds since 1970-01-01 00:00:00 UTC) - but the mechanism that I've got for figuring out the weight at a given time is hopelessly crude: I split the total time span into X intervals, then find the data points preceding and following it, and calculate the "slope" between them, then laboriously figure out the value for that point. What I'd really, really like to have is a function that takes the above list and returns the weight value for any given point in time between Tmin and Tmax; I'm sure that it's a standard mathematical function, but I don't know how to implement it.
Can any of you smart folks help? I'd appreciate it.
-- * Ben Okopnik * Editor-in-Chief, Linux Gazette * http://LinuxGazette.NET *
[ Thread continues here (24 messages/45.54kB) ]
Joey Prestia [joey at linuxamd.com]
Hi Tag,
I am trying to rework a script that currently uses an external file to keep track of what issue the Linux Gazette is on. I would like to do this with out relying on an external file (feels cleaner that way) and just calculate this from within the script using maybe the month and year from localtime(time) from within Perl. Using the month and year I thought this would be an easy task but it turns out its more difficult than I thought. I will probably need some formula to do It to since I will be running it from cron. Can you make any suggestions on how I might attempt this? I have tried to figure a constant that I could use to get it to come out correct with no luck. What works for one year fails when the year changes when you add the month to the year.
# Get Issue my (@date,$month,$year,$issue);
@date = localtime(time); $month=($date[4])+1; $year=($date[5])+1900;
$issue= $year - 1841 + $month ; print "Month = $month Year = $year Issue = $issue\n";
Joey
[ Thread continues here (5 messages/6.26kB) ]
Kiniti Patrick [pkiniti at techmaxkenya.com]
Hi Gang,
I have a question on how to go about installing kernel modules without going through the entire process of recompiling a new kernel. In question is the agpgart module which i want to have as a loadable module. As of now my the agpgart only exists as header files, and dont have the modules ".ko" file yet. Below is the output command from locate agpgart.
$ locate agpgart
/usr/include/linux/agpgart.h /usr/src/kernels/2.6.31.5-127.fc12.i686.PAE/include/linux/agpgart.h
Thanks in advance.
Regards,
--
Kiniti
[ Thread continues here (3 messages/6.96kB) ]
| Share |

|
Ben Okopnik [ben at linuxgazette.net]
On occasion, I need to check my clients' sites for changes against the backups/mirrors of their content on my machine. For those times, I have a magic "rsync" incantation:
rsync -irn --size-only remote_host: /local/mirror/directory|grep '+'
The above itemizes the changes while performing a recursive check but not copying any files. It also ignores timestamps and compares only file sizes. Since "rsync" denotes changes with a '+' mark, filtering out everything else only shows the files that have changed in size - which includes files that aren't present in your local copy.
This can be very useful in identifying break-ins, for example.
-- * Ben Okopnik * Editor-in-Chief, Linux Gazette * http://LinuxGazette.NET *
Jimmy O'Regan [joregan at gmail.com]
Freelang has a lot of (usually small) dictionaries, for Windows. They have quite a few languages that aren't easy to find dictionaries for, so though the coverage and quality are usually quite low, they're sometimes all that's there.
So, an example: http://www.freelang.net/dictionary/albanian.php
Leads to a file, dic_albanian.exe
This runs quite well in Wine (I haven't found any other way of extracting the contents). On my system, the 'C:\users\jim\Local Settings\Application Data\Freelang Dictionary' translates to '~/.wine/drive_c/users/jim/Local\ Settings/Application\ Data/Freelang\ Dictionary/'. The dictionary files are inside the 'language' directory.
Saving this as wb2dict.c:
#include <stdlib.h>
#include <stdio.h>
int main (int argc, char** argv)
{
char src[31];
char trg[53];
FILE* f=fopen(argv[1], "r");
if (f==NULL) {
fprintf (stderr, "Error reading file: %s\n", argv[1]);
exit(1);
}
while (!feof(f)) {
fread(&src, sizeof(char), 31, f);
fread(&trg, sizeof(char), 53, f);
printf ("%s\n %s\n\n", src, trg);
}
fclose(f);
exit(0);
}
The next step depends on the contents... Albanian on Windows uses Codepage 1250, so in this case:
./wb2dict Albanian_English.wb|recode 'windows1250..utf8' |dictfmt -f
--utf8 albanian-english
dictzip albanian-english.dict
(as root
cp albanian-english.* /usr/share/dictd/
add these lines to /var/lib/dictd/db.list : database albanian-english { data /usr/share/dictd/albanian-english.dict.dz index /usr/share/dictd/albanian-english.index }
/etc/init.d/dictd restart
and now it's available: dict agim 1 definition found
From unknown [albanian-english]:
agim dawn
-- <Leftmost> jimregan, that's because deep inside you, you are evil. <Leftmost> Also not-so-deep inside you.
[ Thread continues here (10 messages/18.69kB) ]
afsilva at gmail.com [(afsilva at gmail.com)]
The screen command with pre-set status bar, and cool (easy to remember) shortcuts, like F3, F4, F5 and a configurable menu on the F9 button.
yum install byobu
Got a nice screenshot at: http://www.mind-download.com/2010/09/better-screen-byobu.html
AS
An HTML attachment was scrubbed... URL: <http://lists.linuxgazette.net/private.cg[...]nts/20100927/26297595/attachment.htm>
[ Thread continues here (2 messages/1.74kB) ]
| Share |
|
Thomas Adam [thomas at xteddy.org]
Hello,
A bunch of the "Thread continues ..." links aren't working in issue #178.
Examples:
http://linuxgazette.net/178/misc/lg/load_average_vs_cpus.html http://linuxgazette.net/178/misc/lg/2_cent_tip___counting_your_mail.html
etc.
Also, it seems my name no longer appears in the list of mailbag
contributors, and hasn't done for a while now. Not for many issues. I
don't -think- I've changed my name, although at the weekends...
-- Thomas Adam
"Deep in my heart I wish I was wrong. But deep in my heart I know I am not." -- Morrissey ("Girl Least Likely To" -- off of Viva Hate.)
[ Thread continues here (4 messages/7.63kB) ]
afsilva at gmail.com [(afsilva at gmail.com)]
Not sure if it is normal to send a talkback to my own article, but here it is:
I have gotten a couple of comments/notes since my article "Common problems when trying to install Windows on KVM with vir-manager" came out related to tip #2 (turning off selinux). Yes, I understand it's recommended that selinux stay turned on in 'enforcing' mode in Fedora. Yet, if I do this, I get the following error when trying to startup the virtual machine using a SDL virtual display.
Traceback (most recent call last): File "/usr/share/virt-manager/virtManager/engine.py", line 878, in run_domain vm.startup() File "/usr/share/virt-manager/virtManager/domain.py", line 1321, in startup self._backend.create() File "/usr/lib64/python2.6/site-packages/libvirt.py", line 333, in create if ret == -1: raise libvirtError ('virDomainCreate() failed', dom=self) libvirtError: operation failed: failed to retrieve chardev info in qemu with 'info chardev'
As a 'somewhat reasonably' responsible member of the Fedora community, I
have filed a bug on Red Hat's bugzilla about it (
https://bugzilla.redhat.com/show_bug.cgi?id=635328). Until that is resolved,
or someone else is able to show me another way to get sound working on such
a VM, I stand by my tip to turn off selinux.
Thanks,
Anderson Silva
An HTML attachment was scrubbed... URL: <http://lists.linuxgazette.net/private.cg[...]nts/20100918/75dd5f8c/attachment.htm>
| Share |
|
By Deividson Luiz Okopnik and Howard Dyckoff

|
Contents: |
Please submit your News Bytes items in plain text; other formats may be rejected without reading. [You have been warned!] A one- or two-paragraph summary plus a URL has a much higher chance of being published than an entire press release. Submit items to bytes@linuxgazette.net. Deividson can also be reached via twitter.
 Oracle Supports Java, Solaris but not Developer Community Control
Oracle Supports Java, Solaris but not Developer Community ControlTechnology Titan Oracle just held its Oracle Open World mulit-user-group conference and released roadmaps and announcements impacting several projects in the Open Source sphere.
These updates include new releases for MySQL, Solaris, and Oracle Linux, new Oracle engineered servers and appliances, as well the next generation of the SPARC processor architecture with its partner Fujitsu. However, the future relationship between Oracle and developer institutions like the Java Community Process and OpenSolaris user groups were left uncertain and with hints of an adversarial turn.
Oracle seems to be backing away from OpenSolaris as a developer or small shop operating system by no longer sharing development source code with OpenSolaris distros. A panel of Oracle executives, speaking to the press, declined to discuss OpenSolaris but did state that new Solaris source code would eventually become open-sourced under the CDDL.
Oracle is altering Sun's prior relationship with the Open Source community while making its Solaris offerings more commercial and more like its Linux offerings, which are based on customer support contracts.
Back in August, an internal management memo to Solaris engineers was leaked to the OpenSolaris email distribution. While stressing Oracle's commitment to make Solaris "...a best-of-breed technology for Oracle's enterprise customers" and decision to hire the "top operating systems engineers in the industry," the memo described how Oracle would no longer share source code and builds on a regular basis, except with key partners. Instead, source code would be made available only after new version releases of Solaris:
"We will distribute updates to approved CDDL or other open source- licensed code following full releases of our enterprise Solaris operating system. In this manner, new technology innovations will show up in our releases before anywhere else. We will no longer distribute source code for the entirety of the Solaris operating system in real-time while it is developed, on a nightly basis.
"Anyone who is consuming Solaris code using the CDDL, whether in pieces or as a part of the OpenSolaris source distribution or a derivative thereof, would therefore be able to consume any updates we release at that time, under the terms of the CDDL, LGPL, or whatever license applies.
"We will have a technology partner program to permit our industry partners full access to the in-development Solaris source code through the Oracle Technology Network (OTN). This will include both early access to code and binaries, as well as contributions to us where that is appropriate."
For the complete memo, visit: http://unixconsole.blogspot.com/2010/08/internal-oracle-memo-leaked-on-solaris.html.
Oracle Outlines Core SPARC, Solaris and ZFS InnovationsDuring his keynote presentation at Oracle OpenWorld 2010, Oracle Executive Vice President John Fowler showcased technology innovations and outlined the value of hardware and software engineered to work together as in Oracle's high-end ExaData servers.
Reiterating Oracle's commitment to SPARC, Fowler introduced the industry's first 16-core processor, the SPARC T3, and SPARC T3 systems, which deliver optimized system performance for mission-critical applications. He unveiled eight world-record benchmark results, running the new SPARC T3 server family.
Fowler also unveiled the next-generation Sun ZFS Storage Appliance product line that provides unified storage solutions for deploying Oracle Database and data protection for Oracle Applications.
"We are focused on providing co-engineered systems - Oracle hardware and software engineered to work together - to continually drive better performance, availability, security and management, which translates into business value for our customers," said Fowler.
Oracle Outlines Next Major Release of Oracle SolarisBesides increasing its investment in the Oracle Solaris operating system, Oracle is preparing for Oracle Solaris 11 in 2011 by releasing Solaris 11 Express in 2010 to provide customers with access to the latest Solaris 11 technology.
Oracle Solaris 11 will contain more than 2,700 projects with more than 400 inventions. Oracle Solaris 11 is expected to reduce planned downtime by being faster and easier to deploy, update and manage, and:
- Nearly eliminate patching and update errors with new
dependency-aware packaging tools;
- Build a custom stack of Solaris and Oracle Software in a physical or
virtual image to enforce enterprise quality and policy standards;
- Reduce maintenance windows by eliminating the need for up to 50
percent of system restarts;
- Recover systems in tens of seconds versus tens of minutes with Fast
Reboot;
- Receive proactive and preemptive support that reduces service
outages from known issues via My Oracle Support telemetry integration
with the Oracle Solaris fault management architecture.
Oracle Solaris 11 is being engineered with new capabilities for building, deploying and maintaining Cloud systems. Oracle Solaris 11 will be optimized for the scale and performance requirements of immediate and future Cloud-based deployments, and will scale to tens of thousands of hardware threads, hundreds of terabytes of system memory, and hundreds of Gigabits of I/O.
The first Oracle Solaris 11 Express release, expected by the end of calendar year 2010, will have an optional Oracle support agreement. This release is expected to be the path forward for developers, end-users and partners using previous generations of Solaris and OpenSolaris releases.
Over 1,000 SPARC and x86 systems from other hardware providers have been tested and certified by Oracle. Solaris 11 also will be powering the newly announced Oracle Exadata X2-2 and X2-8 Database Machines, as well as the Oracle Exalogic Elastic Cloud machine.
Oracle Outlines Plans for Java PlatformDuring the opening keynote of JavaOne 2010, Thomas Kurian, executive vice president, Oracle Product Development outlined plans for the future of the Java platform and showcased product demonstrations illustrating the latest Java technology innovations. Kurian's presentation covered four key areas of Java technology:
- Java Standard Edition (Java SE) - optimizing it for new application models and hardware; including extended support for running new scripting languages, increased developer productivity and lower operational costs. Kurian discussed the roadmap for JDK 7 and JDK 8, which will be based on OpenJDK, and highlighted some of the key OpenJDK projects.
- Java on the Client - Oracle is enhancing the programming model with JavaFX, to deliver advanced graphics, high-fidelity media and new HTML 5, JavaScript and CSS Web capabilities, along with native Java platform support.
- Java Enterprise Edition (Java EE) - Java EE will become more modular and programming more efficient with improvements such as dependency injection and reduced configuration requirements. Product demonstration highlighted how the Java EE 6 Web Profile reduces the size of the Java runtime for light-weight web applications, reducing overhead and improving performance.
- Java on Devices - Oracle will modernize the Java mobile platform by delivering Java with Web support to consumer devices. Oracle is also including new language features, small-footprint CPU-efficient capabilities for cards, phones and TVs, and consistent emulation across hardware platforms.
While 1.1 billion desktops run Java, 3 billion mobile phones run Java, and 1.4 billion Java Cards are manufactured each year. This is a very big market that impacts computing at every level.
"Oracle believes that the Java community expects results. With our increased investment in the Java platform, a sharp focus on features that deliver value to the community, and a relentless focus on performance, the Java language and platform have a bright future," said Kurian. "In addition, Oracle remains committed to OpenJDK as the the best open source Java implementation and we will continue to improve OpenJDK and welcome external contributors."
However, in its presentations, Oracle said very little about the well-established Java Community Process (JCP) that has directed the evolution of Java. Although many developers were concerned about this apparent diminishment of the JCP, most seemed pleased with the strong on-going commitment for Java by Oracle and its support of OpenJDK.
Android Poised to Overtake Blackberry, iPhone Market ShareThe rapid growth of mobile devices running Google's Android operating system will continue at the expense of the other leading smartphone platforms, BlackBerry, iPhone, and even Windows Mobile, according to market share data compiled by the comScore marketing service.
For the quarter ending in July, comScore found that Android-based devices improved their share of the overall smartphone market, growing to 17 percent from 12 percent. comScore researchers found that Microsoft lost 2.2 percent of total smartphone market share while RIM tumbled 1.8 percent and Apple, despite launching the vaunted iPhone 4 in June, shed 1.3 percent.
RIM was the leading mobile smartphone platform in the U.S. with 39.3 percent share of U.S. smartphone subscribers, followed by Apple with 23.8 percent share. Google saw significant growth during the period, rising 5.0 percentage points to capture 17.0 percent of smartphone subscribers. Microsoft accounted for 11.8 percent of Smartphone subscribers, while Palm rounded out the top five with 4.9 percent
The July report found Samsung to be the top handset manufacturer overall with 23.1 percent market share, while RIM led among smartphone platforms with 39.9 percent market share.
For more information, see: http://www.comscore.com/Press_Events/Press_Releases/2010/9/comScore_Reports_July_2010_U.S._Mobile_Subscriber_Market_Share.
DeviceVM Adds MeeGo to Splashtop Instant-on ProductDeviceVM, a provider of instant-on computing software, previewed the next-generation of its Splashtop instant-on platform at the Intel Developer's Forum in San Francisco. The flagship Splashtop product has already shipped on millions of notebooks and netbooks worldwide from leading PC OEMs including Acer, ASUS, Dell, HP, Lenovo, LG, Sony and others. The company will offer a MeeGo-compliant version of the popular companion OS to all existing OEM customers, while enabling current users of Splashtop-powered systems to take advantage of a seamless upgrade in the first half of 2011.
First introduced in 2007, the flagship Splashtop product is a Linux-based instant-on platform that allows users to get online, access e-mail, and chat with friends seconds after turning on their PCs. The MeeGo project combines Intel's Moblin and Nokia's Maemo projects into one Linux-based, open source software platform for the next generation of computing devices.
By embracing MeeGo as the foundation for Splashtop, application developers have the possibility to distribute their software to millions of potential users leading to greater adoption of the MeeGo platform. DeviceVM will also consider pre-bundling popular applications along with distribution of the MeeGo-based Splashtop. In moving to a MeeGo-based platform, users will now be able to download, install and run hundreds of apps currently available from the Intel AppUp Center.
"Since the launch of Splashtop in late 2007, we have received thousands of requests from application developers to release an SDK," said Mark Lee, CEO and co-founder of DeviceVM. "By embracing MeeGo and moving Splashtop to be fully compliant with the specifications shepherded by the Linux Foundation, we will effectively open up Splashtop to allow developers to deliver high-value applications to audiences across a range of computing devices."
Demonstrations of the new Meego-based Splashtop product were seen during the IDF expo.
DeviceVM is an active Linux proponent, and earlier this year announced the election of CEO and co-founder Mark Lee to the Linux Foundation Board of Directors.
The MeeGo-based Splashtop is already being made available to leading PC OEMs currently shipping Splashtop on a range of device types. Consumer and commercial end-users will be able to upgrade to the new Splashtop in the first half of 2011.. For more information, visit http://www.splashtop.com.
NetApp and Oracle Agree to Dismiss IP LawsuitsNetApp and Oracle have agreed to dismiss their pending mutual patent litigation, which began in 2007 between Sun Microsystems and NetApp. Oracle and NetApp want to have the lawsuits dismissed without prejudice. The terms of the agreement are currently confidential.
Sun released the code to the ZFS or Zettabyte file system used in Solaris to its developer community in 2005, but claimed to have developed it in-house years earlier. NetApp sued later, claiming that many of the features were similar to the WAFL (Write Anywhere File Layout) file system technology used by NetApp. There were also further IP patent suits regarding the Sunscreen technology that NetApp acquired in 2008.
No theft of code was alleged by either side. The conflict was around commercial use of similar ideas and design.
"For more than a decade, Oracle and NetApp have shared a common vision focused on providing solutions that reduce IT cost and complexity for thousands of customers worldwide," said Tom Georgens, president and CEO of NetApp. "Moving forward, we will continue to collaborate with Oracle to deliver solutions that help our mutual customers gain greater flexibility and efficiency in their IT infrastructures."
Broadcom releases open-source driver for its wireless chipsetsBroadcom has announced the initial release of a fully-open Linux driver for it's latest generation of 11n chipsets. The driver, while still a work in progress, is released as full source and uses the native mac80211 stack. It supports multiple current chips (BCM4313, BCM43224, BCM43225) as well as providing a framework for supporting additional chips in the future, including mac80211-aware embedded chips.
This is a major shift in policy by a dominant networking vendor.
In a blog entry on Linux.com, Linux Foundation Executive Director Jim Zemlin wrote:
"We are extremely happy to see this change for multiple reasons. One: it's obviously good to have more technology available to use; we want technology to "just work" with Linux and since Broadcom is a major technology supplier their absence from the mainline kernel was significant. Two: we have been working with our Technical Advisory Board on this issue for the last few years to educate vendors on Linux' model and why it's in their interest to open source their drivers."
The README and TODO files included with the sources provide more details about the current feature set, known issues, and plans for improving the driver.
The driver is currently available in staging-next git tree, available at: git://git.kernel.org/pub/scm/linux/kernel/git/gregkh/staging-next-2.6.git in the drivers/staging/brcm80211 directory.
The 9th USENIX Symposium on Operating Systems Design and Implementation (OSDI '10) will take place October 4-6, 2010, in Vancouver, BC, Canada.
Join us for OSDI '10, the premier forum for discussing the design, implementation, and implications of systems software. This year's program has been expanded to include 32 high-quality papers in areas including cloud storage, production networks, concurrency bugs, deterministic parallelism, as well as a poster session. Don't miss the opportunity to network with researchers and professionals from academic and industrial backgrounds to discuss innovative, exciting work in the systems area.

We are pleased to announce the 17'th Annual Tcl/Tk Conference (Tcl'2010).
Learn from the experts and share your knowledge. The annual Tcl/Tk
conference is the best opportunity to talk with experts and peers,
cross-examine the Tcl/Tk core team, learn about what's coming and how
to use what's here.
The Tcl Conference runs for a solid week with 2 days of tutorials
taught by experts and 3 days of refereed papers discussing the latest
features of Tcl/Tk and how to use them.
The hospitality suite and local bars and restaurants provides plenty of
places to discuss details, make new friends and perhaps even find a new
job or the expert you've been needing to hire.

The theme of the ASF's official user conference, trainings, and expo is "Servers, The Cloud, and Innovation," featuring an array of educational sessions on open source technology, business, and community topics at the beginner, intermediate, and advanced levels.
Experts will share professionally directed advice, tactics, and lessons learned to help users, enthusiasts, software architects, administrators, executives, and community managers successfully develop, deploy, and leverage existing and emerging Open Source technologies critical to their businesses.
 WeTab tablet first with MeeGo open operating system
WeTab tablet first with MeeGo open operating systemIn September, WeTab GmbH announced its tablet computer, the WeTab, developed in cooperation with Intel, just preceeding the IFA international trade fair for consumer electronics in Berlin and IDF in San Francisco. The WeTab, which went on to the German market in September, is the first tablet worldwide based on MeeGo.
WeTab OS, the WeTab operating system, is based on the free Linux distribution MeeGo and integrates runtime environments for various other technologies. In addition to native Linux apps, many other applications can run on the WeTab, including Android apps, Adobe Air applications and MeeGo apps. Several apps that may be interesting for the user have been compiled and are available on the WeTab Market, from where they can be loaded directly onto the WeTab. This means that developers can program in the languages they are familiar with and users can choose from an abundance of very different applications.
The Web-browser plays a special role here and is based on the free HTML rendering engine WebKit, enabling fast surfing and including suport for HTML5, Adobe Flash and Java.
"Working intensively with Intel, we have developed the WeTab OS with MeeGo to meet the requirements of a tablet user in the best way possible. The tablet runs extremely fast and, in addition to native apps, also provides direct access to countless Web-based apps", says Stephan Odörfer, Managing Director of 4tiitoo AG, which is are also involved in this joint venture with WeTab GmbH.
Wolfgang Petersen, Director of Intel Software and Services Group at Intel Deutschland GmbH, says: "The WeTab is the first tablet based on MeeGo and the Intel Atom processor. MeeGo is designed for a broad range of devices. Implementing MeeGo on the WeTab shows just how the operating system can be adapted for use on a tablet."
WeTab GmbH is a joint venture between 4tiitoo AG and Neofonie GmbH.
You can find more information at http://www.wetab.mobi, http://www.intel.com and http://www.meego.de.
Linpus Lite for MeeGo netbook edition adds Touch SupportLinpus announced in September further enhancements to its Meego-based version of its Linpus Lite, which is optimized for the Intel Atom processor. Linpus Lite is their consumer device operating system designed for a better mobile Internet experience.
Linpus originally brought one of the first MeeGo-based operating systems to market in time for Computex. They have since upgraded it with a number of improvements. First, they have included better categorization of the social networking and recent object panel in Myzone. Linpus has created a tab for each of the different sites and for recent objects, making it easier to find your messages.
Second, they have also added touch support and dual user interfaces. You have the choice of two interfaces: MeeGo and Linpus' Simple Mode. You can switch easily between these two modes by one tap on an icon in Myzone or in Simple Mode.
Linpus' version has also added a number of other enhancements:
- Extremely fast boot - now under 10 seconds
- More social network support in Myzone - Flickr and MySpace
- Online support - Linpus commercial grade LiveUpdate function to
deliver device-specific patches, upgrades and new applications to your
system
- Media Player - added support for audio and video streaming
- Power management - idle mode and auto-suspend net power savings of
15 to 20%
- Network Manager - more 3G modems and device-to-device file transfer,
VPN, PPPoE and WPA2-enterprise support;
- Linpus Windows Data Applications - for dual-booting with Windows;
- Peripheral support - extensive support especially for graphics,
including the Intel full series graphics and most of NVIDIA and ATI;
- Input method - multi-language input method and international
keyboard support through iBus;
- File Manager - a Windows-like experience means that the partitions
of USB drives are now alphabetically labeled.
Linpus (http://www.linpus.com) has worked on open source solutions across numerous platforms and products, garnering a reputation for engineering excellence as well as highly intuitive user interfaces. The MeeGo project combines Intel's Moblin and Nokia's Maemo projects into one Linux-based, open source software platform for the next generation of computing devices.
Oracle Enhances New Solaris ReleaseBuilding on its leadership in the enterprise operating system market, Oracle today announced Oracle Solaris 10 9/10, Oracle Solaris Cluster 3.3 and Oracle Solaris Studio12.2. 10 of the top 10 Telecommunications Companies, Utilities and Banks use Oracle Solaris.
Oracle Solaris is now developed, tested and supported as an integrated component of Oracle's "applications-to-disk" technology stack, which includes continuous major platform testing, in addition to the Oracle Certification Environment, representing over 50,000 test use cases for every Oracle Solaris patch and platform released.
Oracle Solaris 10 9/10 provides networking and performance enhancements, virtualization capabilities, updates to Oracle Solaris ZFS and advancements to leverage systems based on the latest SPARC and x86 processors.
The Oracle Solaris 10 9/10 update includes new features, fixes and hardware support in an easy-to-install manner, preserving full compatibility with over 11,000 third-party products and customer applications.
Oracle Solaris is designed to take advantage of large memory and multi-core/processor/thread systems and enable industry-leading performance, security and scalability for both existing and new systems.
Oracle Solaris Cluster 3.3 builds on Oracle Solaris to offer the most extensive, enterprise high availability and disaster recovery solutions.
Enables virtual application clusters via Oracle Solaris Containers in Oracle Solaris Cluster Geographic Edition and integrates with Oracle WebLogic Server, Oracle's Siebel CRM, MySQL Cluster and Oracle Business Intelligence Enterprise Edition 11g for consolidation in virtualized environments.
Provides the highest level of security with Oracle Solaris Trusted Extensions for mission-critical applications and services. Supports InfiniBand on public networks and as storage connectivity and is tightly integrated and thoroughly tested with Oracle's Sun Server and Storage Systems.
Oracle Solaris Studio 12.2 provides an advanced suite of tools designed to work together for the development of single, multithreaded, and distributed applications. With its integrated development environment (IDE), including a code-aware editor, workflow, and project functionality, Oracle Solaris Studio helps increase developer productivity.
Oracle Solaris 10 9/10 features include:
Networking and database optimizations for Oracle Real Application
Clusters (Oracle RAC).
Oracle Solaris Containers now provide enhanced "P2V" (Physical to Virtual) capabilities to allow customers to seamlessly move from existing Oracle Solaris 10 physical systems to virtual containers quickly and easily.
Increased reliability for virtualized Solaris instances when deployed using Oracle VM for SPARC, also known as Logical Domains.
Oracle Solaris ZFS online device management, which allows customers to make changes to filesystem configurations, without taking data offline.
New Oracle Solaris ZFS tools to aid in recovering from problems related to unplanned system downtime. Operating system, database and other Oracle Solaris patches are now verified and coordinated to provide the highest levels of quality, confidence and administrative streamlining.
New Release of Oracle Secure Global DesktopFurther enhancing its comprehensive portfolio of desktop virtualization solutions, Oracle released Oracle Secure Global Desktop 4.6 in September. Secure Global Desktop is an access solution that delivers server-hosted applications and desktops to nearly any client device, with higher security, decreased operational costs, and increased mobility.
With a highly secure architecture, Oracle Secure Global Desktop helps keep sensitive data in the datacenter behind the corporate firewall, and not on end user systems or in the vulnerable demilitarized zone (DMZ), and can only be accessed by authenticated users with appropriate privileges.
Oracle Secure Global Desktop enables an additional layer of security for accessing sensitive enterprise applications, beyond using a web browser alone, by providing a highly secure Java-based Web client that does not retain cookies or utilize Web page cache files that could be exploited.
The new release lowers administration overhead by delivering secure access to server-hosted applications and desktops from a wide variety of popular client devices. Applications and desktops that run on Windows, Oracle Solaris, Oracle Enterprise Linux, and other UNIX and Linux versions are supported.
Oracle Secure Global Desktop 4.6 is part of "Oracle Virtualization," a comprehensive desktop-to-datacenter virtualization portfolio, enabling customers to virtualize and manage their full hardware and software stack from applications to disk.
Oracle Secure Global Desktop 4.6 enhances the security and centralized
management of applications in the datacenter by delivering:
- Greater browser flexibility: The Secure Global Desktop client has
the flexibility to be used with nearly any Java-enabled browser to
access server-hosted browser instances where the server-hosted
application requires a different browser, plug-ins, or settings;
- Enhanced availability: The Array Resilience feature automatically
re-establishes connections to the server array after a primary server
or network failure to provide higher levels of availability;
- Enhanced application launch control for users: Dynamic Launch
reduces administration overhead by giving end users greater control
over launching applications;
- Easier integration with third party infrastructure: Integration
with third party virtual desktop infrastructure (VDI) connection
brokers, in addition to the existing integration with Oracle Virtual
Desktop Infrastructure;
- Dynamic Drive Mapping allows users to "hot-plug" hard disk drives
and USB drives on their PCs and utilize them in Oracle Secure Global
Desktop sessions;
- Configurable directory services and password management:
Administrators can configure individual settings for multiple
directory services, such as Oracle Internet Directory, Microsoft
Active Directory and other LDAP servers.
"The new capabilities delivered in Oracle Secure Global Desktop 4.6 underscore our focus on making applications easier to deploy, manage and support in virtualized datacenter environments," said Wim Coekaerts, senior vice president, Linux and Virtualization Engineering, Oracle. "Oracle Secure Global Desktop 4.6 is the latest of many new desktop virtualization products and capabilities recently announced including new releases of Oracle VM VirtualBox, Sun Ray Software and Oracle Virtual Desktop Infrastructure. This demonstrates Oracle's continued commitment to providing a comprehensive desktop to datacenter portfolio."
For more information, visit http://www.oracle.com/us/technologies/virtualization/index.htm.
| Share |
|
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/dokopnik.jpg)
Deividson was born in União da Vitória, PR, Brazil, on 14/04/1984. He became interested in computing when he was still a kid, and started to code when he was 12 years old. He is a graduate in Information Systems and is finishing his specialization in Networks and Web Development. He codes in several languages, including C/C++/C#, PHP, Visual Basic, Object Pascal and others.
Deividson works in Porto União's Town Hall as a Computer Technician, and specializes in Web and Desktop system development, and Database/Network Maintenance.
Howard Dyckoff is a long term IT professional with primary experience at
Fortune 100 and 200 firms. Before his IT career, he worked for Aviation
Week and Space Technology magazine and before that used to edit SkyCom, a
newsletter for astronomers and rocketeers. He hails from the Republic of
Brooklyn [and Polytechnic Institute] and now, after several trips to
Himalayan mountain tops, resides in the SF Bay Area with a large book
collection and several pet rocks.
Howard maintains the Technology-Events blog at
blogspot.com from which he contributes the Events listing for Linux
Gazette. Visit the blog to preview some of the next month's NewsBytes
Events.


"I've bought us a new potato peeler. Doesn't it look fantastic!"
My wife's enthusiasm was boundless. Meanwhile I struggled with the nuances of her declaration.
Why us? I wondered uncharitably. I was perfectly happy with the three other potato peelers we already had. Why did we need a new one? And why would I care what it looked like?
A few days later, I complained, "It doesn't do a good job."
"You're such a curmudgeon. It's beautiful. That's all that matters."
This is our endless debate. For her, style is all. I, on the other hand, believe that, without function, form is irrelevant.
Sadly (for me), my wife is in the majority. And nowhere is this demonstrated better than on websites.
I see many jobs for web designers, but I can't get my head around what people mean. If all these websites are designed, how come they are so dreadful at what they do?
Perhaps I'm begging the question. Maybe the purpose of each website is to be a monument to its designer, an item for her folio, a notch on his belt.
Perhaps, in the vein of "your call is important to us" (newsflash: it isn't), these websites do indeed reflect the desires of their owners. These desires start with a complete disdain for their users, whom they treat with contempt. They seem to want their websites to be vehicles to push other products.
Take my bank, Citibank. When I first started using their website for banking (over 3 years ago), I was extremely impressed. It seemed that they had found a balance between security and usability. (Of course, I'm talking about my experience in Australia. I have no knowledge of how Citibank's websites work anywhere else in the world. I'm guessing it's the same throughout Australia, but I can't even guarantee that.)
What impressed me the most was their out-of-band confirmation. Before I transfer money to any party, I must first set that party up as an account in my profile. I use normal browser procedures to create the account, but before the account can be activated (ie used), I have to ratify it. In the past, I could do that in one of 2 ways: ring Citibank (a not particularly convenient mechanism - but it is only once per account); or respond to an email.
In the meantime, they have replaced both of these with another mechanism: they SMS a code which I must manually enter. I think most banks do that now.
Using SMS rather than email is likely to be more secure. In theory, if your PC is compromised, the hacker has access to your bank account and your email. To rip you off now, the hacker would also have to be in possession of your phone.
That's all basically good news. Now for the not-so-good news.
In the first incarnation of Internet banking, I had to provide my ATM card number and PIN (pretty much the same as when I went to an ATM). That seemed to me to be secure enough. If it was adequate protection for me at the ATM, why was it less than adequate for Internet banking?
I am not an authority on security, but neither am I a complete stranger.
The theory is that security is about something you have and something you know. (Technically, there's a lot more to it than that. There's also something you are. But that doesn't apply here, so let's move on.) So, when I go to the ATM, what I have is my bank's card. And what I know is my PIN.
One way that fraud is perpetrated on such a system is that the baddies capture (usually photograph or film) the details of your card (basically its number) and use the captured data to create a clone card. Capturing someone's PIN is often not difficult. There are video cameras everywhere these days; and most people are almost reckless in their failure to even try to conceal their activity when they enter their PIN. Just look around the next time you are in the queue at a store's checkout.
You should take the view that if your eyes can see what you are keying when you enter your PIN, then it is susceptible to capture. Ideally, you should cover your keying hand as you key.
When you pay your bill at the restaurant, the something you have is your credit card. There really isn't anything that you know. Arguably, you know how to produce your signature; but then so does any respectable forger. Once she has obtained your card, she has all the time in the world to practice forgery. Even better, if a baddy gets hold of a copy of your card's imprint, he can produce a clone and sign the clone in his handwriting (with your name).
I guess the weakness in Citibank's first incarnation, is that it converts something you have (the card) into something you know (the card's number). When it comes to things you know, two are not better than one. (Perhaps marginally better.)
There are techniques that achieve a de facto something you have. "RSA SecurID is a mechanism developed by RSA Security for performing two-factor authentication for a user to a network resource." (http://en.wikipedia.org/wiki/SecurID) In essence, it's a gizmo that displays a number (at least 6 digits). The number changes every minute. Every gizmo has its own unique sequence of numbers. So, in theory, unless you are holding the gizmo, you cannot know which number is correct at any time. Put another way, knowledge of the correct number is de facto proof that you have that special something you have.
These techniques are probably expensive. Perhaps the bank thought that its customers are too stupid to be able to use such a gizmo.
After some time, Citibank changed the access mechanism. I was invited (read ordered):
You will be guided to create your own User ID, Password and three "Security Questions". You will be asked to choose from a range of questions. Each time you sign on you will be asked one question.
My guess is that most users access their accounts from a PC running Microsoft, um, products (I cannot bring myself to write software in the same sentence as Microsoft). And I guess there was a concern that many of these machines could be (or had been) compromised. I generally don't use Microsoft platforms to access the Internet; I run Linux on my desktop (as any sensible person would). And I NEVER use Microsoft platforms to access anything to do with dollars.
So I wonder why I have to suffer. Why can't I choose the mechanism with which I access Citibank's facilities?
Ostensibly, Citibank's brave new world of banking was better than the previous world. Here's how it worked (and still works at time of writing).
Disclaimer By now, the reader must have realised that I have no personal inside knowledge of Citibank or any of its personnel. This entire piece is speculation on my part, together with my actual personal experience. As they say, YMMV. So I'm going to drop the "my guesses" and "I supposes"; it's all getting too clunky.
I go to the login screen (affectionately called a "sign on" so as not spook the cattle). I enter my User ID. I click on the field where I would normally expect to enter my Password. Up pops a virtual keyboard. This is supposed to defeat keyboard sniffers. Even if a sniffer has captured a session during which I entred my User ID and Password, the only bit that is usable is the User ID (and maybe part of the Password). The virtual keyboard consists of 3 parts. The letters of the alphabet are pretty standard; there's a numeric pad to the right; but there are no numbers on the top row of the keyboard, only the characters produced when these keys are shifted:
!@#$%^&*()_+
The special characters and digits are not in fixed positions; each time the virtual keyboard pops up, the order of these keys changes. So even if a keyboard sniffer detects where you clicked, it does not establish what you clicked.
The perpetrators of this approach had better be really really sure that this last assertion is true. Because the virtual keyboard with the changing keycaps comes at the expense of reducing my password strength. They have decreased the size of the symbol set. There are 94 ASCII printable characters available to a random password generator. Citibank's keyboard is case insensitive; there are only 46 characters to choose from.
Further, I'm not certain it defeats all hacks. If your PC is compromised, perhaps it is also possible that your browser has been hijacked. If the baddies present you with their virtual keyboard, would you notice?
There are other hacks that are theoretically possible.
My suspicion is that the virtual keyboard came from the same school as many of the security "enhancements" inflicted on people in the US after 9/11. These "enhancements" are more about creating the illusion of security than being effective.
It's horrendous to use. For me, when my eyesight was bad, the characters were almost unreadable. On a normal keyboard, I don't have to see the characters clearly; it's enough that I know where they are. But on the virtual keyboard they are never in the same place twice. I changed my password to use characters that I could more readily distinguish.
[ ...thus decreasing the password strength even further (it's not that hard to guess which characters are more distinguishable with poor eyesight.) This reinforces Henry's point: the Law of Unintended Consequences is alive, well, and hyperactive, particularly in the area of UI/security interactions. -- Ben ]
Because my eyesight was so poor, I was in the habit of using my browser's feature for increasing text size. That should solve the problem with the virtual keyboard, I hear you say. Missed it by that much. When I increased text size in the browser window, each character in the virtual keyboard was no longer aligned with the box with which it was associated. In some cases it became even harder to read, even though it was bigger.
My personal biggest gripe with this mechanism is that it takes me much longer to enter my password. Instead of a simple swipe-paste, I must click each character.
My other bank (Commonwealth Bank) has a simple Client Number and Password. As far as I'm concerned, that's perfectly acceptable and vastly preferable. Commonwealth Bank also uses SMS for ratification.
That brings us to yesterday (March 2010). The folk (web designers?) at Citibank have given their website a makeover. It has a completely different look. What's really galling is that the functionality is not better than it was. However, it is vastly different; so now I have to learn how to use the new user interface.
Imagine you've bought yourself a shiny new car. (Obviously it wouldn't happen like this.) You drive it for six months. And then one day you jump behind the wheel - er, wait! where is the steering wheel? Oh, they've moved it to the other side of the car. I have to get in the passenger side to drive. I wonder which one of these pedals is the brake? Ok, I'm starting to get used to it. Now, indicator? Hmm, where would they have put the indicator?
I think you get my drift.
And it's not any better than the previous user interface! - which wasn't great and could have done with some improvement.
But we're back to the potato peeler. If it doesn't peel potatoes, who cares what it looks like? In my opinion (obviously not worth much), Citibank's new look is really terrible.
But here we've come full circle also. The one noticeable difference is that there are many more references to and come-ons for Citibank's other products. Once again, the customer is treated with contempt - unless he's about to buy something.
| Share |
|
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/grebler.jpg)
Henry has spent his days working with computers, mostly for computer manufacturers or software developers. His early computer experience includes relics such as punch cards, paper tape and mag tape. It is his darkest secret that he has been paid to do the sorts of things he would have paid money to be allowed to do. Just don't tell any of his employers.
He has used Linux as his personal home desktop since the family got its first PC in 1996. Back then, when the family shared the one PC, it was a dual-boot Windows/Slackware setup. Now that each member has his/her own computer, Henry somehow survives in a purely Linux world.
He lives in a suburb of Melbourne, Australia.
PayPal's Innovate developer conference comes the San Francisco on October 26-27. Here's a chance to learn how the web collects its money.
This year, they move from the arguably lower-rent San Francisco Concourse, an augmented warehouse with skylights and carpeting, to the tech conference standard of the Moscone Center. The first event in 2009 was was a sell-out and was bursting at the seams. The step up is partly necessitated by the fact the rooms were not big enough for most of the 2009 sessions.
This year, some of the same formula is present: a 2-day format, ultra-low price (under $200 if you early-bird it), and major guest speakers like Tim O'Reilly, founder and CEO of O'Reilly Media, and Marc Andreessen, co-founder of Netscape Communications.
This year has an extra deal: a conference pass and 2 nights at the Parc 55 Hotel for only $399. And you can save $50 off that if you register by October 3rd with code INV810.
The food and caffeine was plentiful in 2009, even though it was mostly sandwiches, chips, and pizza - but really good pizza. They did not take away the coffee/tea/soda between sessions and that is most appreciated. At the Moscone Center, catering staff take away food and drink after the allotted time has passed. Let's see if the coffee urns stay out this year.
But why PayPal? Because of their PayPal X community which developed when they opened up their APIs and also because PayPal is empowering the global micro-payments industry and is experimenting with mobile phone micro-payments to support aid and development projects in the 3rd world - bringing hi-tech into lo-tech places. The event is in part about "crafting the future of money, literally changing the way the world pays." That's a very ambitious goal.
More specifically, PayPal X is an open global payments platform which includes developer tools and resources. The developer community around PayPal X is trying to shape the way the world uses - and thinks about - money. Those tools can be reviewed and tested at http://x.com. They include payment APIs, code samples, in-depth documentation, training modules, and much more.
According to an article in the Economist magazine in 2009, the use of mobile money via cell phone in the developing world reduces banking and transportation costs and leads to family wealth increasing by 5-30%. Transactions are faster, safer, and have better transaction logging. Mobile payments are becoming the default banking system of those without banks and credit, accelerating the movement away from cash.
There will be over 50 technical sessions for an expected 2000-2500 attendees. And at these sessions you can learn strategies for monetizing businesses or see how others are using the PayPal APIs. Last year there also were chalk talk sessions but they were mostly under-attended.
This link take you to the Innovate 2009 Keynotes and Breakout Sessions: https://www.x.com/docs/DOC-1584
To get a better sense of the ad-hoc and dynamic nature of the sessions, check out these 3 session links:
There were lots of giveaways: free PayPal Dev accounts, source code giveaways (the shopping cart PayPal developed for Facebook), T-shirts, etc. But the most outstanding perk for PayPal Innovate attendees was the 10 inch ASUS 'eee-pc' netbook given to all who were at the keynote on the first day. They did run out and gave receipts to the late claimants to get an eee shipped to them - the luggage tag in the conference bag had a time code which determined if you were an early bird or a late one. The netbook came preloaded with PayPal X materials and had a PayPal sticker on the cover. I suspect that the perks this year will be smaller as Moscone Convention Center rates must be 2x-3x of the 2009 site. In fact, you might say the 2009 PayPal conference was free and $200-300 fee went into the perks... no guarantees for 2010, however.
To register or find out more about the Innovate conference, visit: https://www.paypal-xinnovate.com/index.html
| Share |
|
Talkback: Discuss this article with The Answer Gang
Howard Dyckoff is a long term IT professional with primary experience at
Fortune 100 and 200 firms. Before his IT career, he worked for Aviation
Week and Space Technology magazine and before that used to edit SkyCom, a
newsletter for astronomers and rocketeers. He hails from the Republic of
Brooklyn [and Polytechnic Institute] and now, after several trips to
Himalayan mountain tops, resides in the SF Bay Area with a large book
collection and several pet rocks.
Howard maintains the Technology-Events blog at
blogspot.com from which he contributes the Events listing for Linux
Gazette. Visit the blog to preview some of the next month's NewsBytes
Events.
And in the fourth month of my new job, I encountered numerous problems all related to backup.
Backup! My eyes glaze over. I suppose some people can get enthusiastic about backup, but not me. Oh, sure, I understand the point of backup. And I try very hard in my own endeavours to keep lots of backup. (What would happen to my writing if I lost it all! Oh, the horror.)
Currently, I seem to spend about a third of my time on backup. There are many aspects to this, and several reasons. Nonetheless, there are many activities that are not a particularly good match for my skill-set: operating a Dymo labelmaker; searching for tapes; opening new tape boxes; removing shrink-wrapping; loading and unloading magazines; searching for tape cases; loading tape cases; removing tapes from their covers; inserting tapes into their covers; delivering tape cases to, and retrieving them from, a nearby site.
I yearn to throw the whole lot out and start again. But, of course, that is unthinkable.
We have 3 jukeboxes which feed 5 tape drives. About a month ago, the PX502 started to misbehave. I started scouring documentation, searching around in the logs and trying various commands. Somewhere I came across this helpful message:
The drive is not ready - it requires an initialization command
Oh, really? Well, if you are so smart, send the appropriate initialization command. Or tell me what the initialization command looks like and ask me to issue it.
Don't you just hate that? It's on a par with those stupid messages that compilers sometimes produce, something like:
Fatal error: extraneous comma
!! I mean, I wouldn't mind,
Warning: extraneous comma. Ignored.
But "Fatal error"?! Give me a break. That's just punitive.
It seemed to me that the aberrant behaviour was hardware-related. I chased around to see if the unit was under maintenance. There was some difficulty in locating the relevant paperwork, but I was given a phone number and assured it would be OK. It wasn't really OK, but David came out nonetheless and poked around.
It was one of those visits like when you take your car to the mechanic - or your kids to their friends. The car and the kids are suddenly on their best behaviour. The mechanic cannot hear any of those ominous noises that caused so much consternation. And the other parents report what sweet children you have.
As you drive away in frustration, the car starts its strange noises and the kids are attempting to kill each other in the back seat.
Two days later I was back on the phone to David. He assured me that our support was not with him but with some other crowd, but since he had started down this path, he would continue and work out some cross-charging with the other crowd. He told me to run some program and send him the output.
Apparently, he sent the output on to the US and was informed that one of the drives needed replacement. They shipped a replacement drive to David, who came out again a few days later.
And that should have been the end of it.
But no. This is the story of a nightmare; don't look for happy endings. The happiest part of a nightmare is when you wake up.
The software which coordinates all the backup tasks is Sun's StorageTek EBS which is really Legato NetWorker under the covers. After the drive swapout, the StorageTek software showed only a single drive on the PX502.
I struggled with this for a while, believing it ought to be fairly
straightforward to solve this problem. And this is where I demonstrate
why I earn the big bucks. 
When you encounter a problem like this you have the analogue of the manufacturer's make/buy dilemma. Do you try to fix it yourself? Or do you call in support? Before you can think about calling for support you have to answer a few questions.
First, have you investigated the problem? If your opening gambit is, "It doesn't work," you may find it hard to get useful help. Support may suggest politely that you try reading the manual.
Second, is the problem hardware or software? In many cases, my answer is that if I knew that I wouldn't be calling for support. Nevertheless, you need to be able to engage support, get them interested enough to want to help you. Otherwise, they'll just give you a lot of dopey menial tasks.
Finally, do you even have support?
First, I tried the Microsoft approach: if things don't work, try restarting them; or power cycling. I'm not proud to take this route, but I figure support is going to suggest it, so I may as well clear the decks. Unsurprisingly, nothing was gained.
I started trying to break things down. Does the machine see the hardware?
Before the problems, the PX502 controlled 2 tape drives:
/dev/rmt/0cbn /dev/rmt/1cbn
The first of these was the faulty one. When it was swapped out, the new tape drive came up as /dev/rmt/2cbn. I don't understand why. As I write this, it occurs to me that another approach to this problem may have been to persuade Solaris at the lowest level that this tape drive was /dev/rmt/0cbn.
I also thought it might not be a bad idea to reboot the Sun to which the tape drive is attached, but this is the organisation's file server; rebooting it is not a task to be taken lightly. Fortuitously, it rebooted itself one night when one of its SAN disks had a hiccup. Even the reboot did not improve matters.
I was able to go to the front panel of the PX502, press some buttons and load a tape into the "invisible" drive. So, at least as far as the PX502 is concerned, the tape drive is present.
I then went to the Sun to which the tape drive is attached and issued:
mt -f /dev/rmt/2cbn status Quantum DLT-S4 tape drive: sense key(0x6)= Unit Attention residual= 0 retries= 0 file no= 0 block no= 0
That's promising. It looks like the Sun knows about the tape drive.
Since the tape was one of the backup tapes, it had a label. I don't know exactly what a label looks like, but I expect it to be at the beginning of the tape. I did:
dd if=/dev/rmt/2cbn ibs=1000000 count=1 | od -Cx | less
This reads the first MB off the tape and pipes it into a dump format. Lots of the dump were incomprehensible to me, but about 16 lines down I found a string that corresponded to the label (tapeBSA.3472).
0000360 \0 \0 \0 \f t a p e B S A . 3 4 7 2
At the lowest level, the drive is present and works fine.
When David had come out, he had shown me how to connect to the PX502 web interface. From the web interface one can control the PX502 more conveniently than from its front panel. I navigated from one screen to another, satisfying myself that it could see two tape drives, could move a tape from a magazine to a drive; and move it the other way as well. So it seemed fair to conclude that the PX502 was OK.
That left the interface between the PX502 and the Sun, or the StorageTek software. The StorageTek software claimed it could see the PX502 and one of the drives, so my money was on a problem with the StorageTek software. Time to find out if we have support (we do) and then get in touch with Sun.
After only a little bit of palaver over my inability to locate the correct paperwork, Sun routed my call to someone who took down the details. He was reasonably patient with my uncertainty as to whether this was hardware or software. After some discussion, he agreed with my view that it was probably the StorageTek software that merited attention. I was given a Tracking Number.
I didn't expect anything much to happen right way, especially as I'd called about 4:30 pm on a Friday. I began thinking about packing up and going home, expecting that I'd pick up the matter on Monday, so I was somewhat startled when the phone rang only a few minutes later.
"I'm ringing about your Sev 1."
Sev 1?! A Severity One error means something catastrophic like the entire business has ground to a halt! I freaked. Typically, to get an organisation like Sun to even allow you to call in a Sev 1, you have to be paying big bikkies. Normally you get "best effort" or maybe "response within one business day". Sev 1?! Maybe defence departments get to call Sev Ones, not me.
I hastened to assure the caller that I had never mentioned that the problem was critical. Far from it - I was in no great rush to get the problem solved. He took this with good grace, and we agreed to leave it until Monday.
I guess Sun runs some sort of tag-team problem-solving that follows the, um, sun. On Monday morning, my inbox had a couple of emails with the Tracking Number in the subject, which had arrived Friday after I had left.
The first email seemed to be on the ball. It asked me to provide details of the software I was using; the output of several commands; and the contents of several logs. This approach suits me well. I get to find out which instructions the experts use, so in the future I can help myself.
The second email came from the same sender. I'm guessing he's based in India. He had tried to call me and wanted to confirm that the number he had was correct. Since his email included a bit that went "... as I did not get a response @ 61-3 ...", I concluded that he had tried to make an international call. (I usually expect to see a plus (+) for international access, but "61" is the country code for Australia and "3" is my area code.) He also asked for a few more details.
I spent the rest of Monday fighting fires. It was Tuesday before I could gather the various responses. I was still a bit antsy about the Sev 1, so I prefaced my responses with:
I've said this before, but I'll repeat it just in case. The unit is usable (even though it seems to complain that it can't see the changer). We are doing backups with the one tape drive it can see. However, it had 2 tape drives and we want it to be able to use both tape drives.
I included in my email a summary of the situation to date, pretty much what I have written above.
When it came to sending the logs, I had a bit of a problem. One of the log files was 12 MB, the other 544 MB. It seems that these log files are never rolled over. I sent the last part of the log file, containing entries for the last few months.
I had been asked to "kindly provide the screenshot that shows the errors from console."
I had two methods for monitoring the backup: a java GUI; and nsrwatch, a curses-based application. The GUI proved unhelpful, but nsrwatch displayed several messages.
The main error message was:
media warning: The /dev/rmt/0cbn is either skipped as requested (due to hardware problem) or no longer connected to the storage node. media warning: Please remove /dev/rmt/0cbn from NetWorker if it is permanently disconnected.
Well, that's probably correct. The old drive was zero; for some reason the new one is two. There was also an analogous message for the changer. And yet, the software can drive the changer!
I wrote back:
I've attached a screenshot, but there are no error messages as such. Perhaps the following might be more useful: # jbedit -j 'Quantum PX502' -a -f /dev/rmt/2cbn -E 81 Using 'unix33.alpha.wehi.edu.au' as NetWorker server host. 39078:jbedit: RAP error: The device '/dev/rmt/2cbn' is already part of jukebox 'Quantum PX502'. # jbedit -j 'Quantum PX502' -d -f /dev/rmt/2cbn -E 81 Using 'unix33.alpha.wehi.edu.au' as NetWorker server host. 39077:jbedit: error, Cannot find device `/dev/rmt/2cbn' in jukebox `Quantum PX502'.
I included this to underline the point that the software had become very confused. I can't add the tape drive because it's already there. But I can't delete it because it isn't there.
Late the next afternoon a reply came summarising their understanding of the problem; then this:
Please Select the jukebox PX502 from GUI and do a scan for drives. I am sure this will show the missing drive into the configration. If this fails we need to delete this Jukebox and recreate it once again. It is suggested to do this when there is a downtime available.
There was an interesting bit that followed. Here's a fragment of my reply:
------------------------------------------------------------------------
-->please let me know how did you get the element number "81". Kindly
I honestly don't remember.
-->confirm the correct element number using the sjisn command.
sjisn 3.7.0
Serial Number data for 3.7.0 (QUANTUM PX500 ):
Library:
Serial Number: QP0714BDC00025
SCSI-3 Device Identifiers:
ATNN=QUANTUM PX500 QP0714BDC00025
IENN=00E09EFFFF0B61FE
WWNN=100000E09E0B61FE
Drive at element address 128:
SCSI-3 Device Identifiers:
ATNN=QUANTUM DLT-S4 QP0713AMD00014
Drive at element address 129:
SCSI-3 Device Identifiers:
ATNN=QUANTUM DLT-S4 QP0734AMD00102
I guess 81 (hex) = 129 (decimal).
------------------------------------------------------------------------
And here we have an encapsulation of some of the many ways that things can go wrong. This is so easy in hindsight. I have a PhD in hindsight. Rear vision is always 20/20.
Why had I used element number "81"? Because I am too clever by half! In the man page for jbedit(1m), I had seen an example which ended with "-E 82". When one is a Brilliant Expert, one gets a "feel" for the "shape" of numbers. A number like 81 or 82 in the context of devices is so obviously hexadecimal only a fool would imagine any other possibility. (Would the fool typing please put his hand up?) When I saw "129" it was obvious that I was meant to translate it to hex, so I did. Wrong!
Strangely, the support guys never corrected me. That's the next lesson. I had spent much time trying to establish how to determine the element number. I should never have responded the way I did.
I ought to know better. I have worked for many years in support. I am reluctant to let my customers tell me what they think is wrong. I am only interested in what they were trying to do, what they saw, and what they expected or wanted to see. Very often, if I let them tell me what they think is wrong, I get sucked in to their view of the problem. Had that view been helpful, they would have solved the problem already. They are coming to me for a fresh perspective.
In researching for this article, I came across this in the man page:
The data element address is the "decimal number" that the jukebox assigns to each of its drives.
This underlines another valuable lesson. Most people, most of the time, operate as if they subscribe to the theory "don't confuse me with facts, my mind's made up". Of course, if you try to say that to people out loud, they respond that it's ridiculous.
I may have read that part of the man page when I was trying to solve the problem. But, if I did, I never connected "decimal number" with the value associated with "-E". (I wonder why the man page has "decimal number" in quotes.)
The next day I received another email suggesting that the GUI "database is corrupted"; that I pkgrm (uninstall) the GUI part of the software; delete the database components; and then pkgadd ((re)install) it. I'd seen a similar suggestion in posts on the Net.
Be careful what you wish for. And, once again, I justify my wage.
I am always reluctant to delete. Except in extremis, I always rename. Or take a copy and then pkgrm. Fortunately, that's what I did.
And when he got there the cupboard was ...
... not exactly bare. However, when I had pkgrmed the software, I then tried the pkgadd
pkgadd: ERROR: no packages were found in </var/spool/pkg>
Oops.
I started rooting around the file system. However, there were some problems. I guess I should have said "more problems"; I seem to have them in spades.
This is a Sun running Solaris 10. Unlike sensible systems (Linux, FreeBSD), Sun does not offer "locate" by default. As I read somewhere, if ever a system needed "locate", it's Solaris. Further, this system is the file server: it serves over 20 TB. It's also extremely overloaded. I'm not going to be popular if I start doing a find across 20TB; and I'm not going to get an answer any time soon. So, although I know what the package is called, I'm going to have a hard time finding it.
I eventually found the package and installed it. Um, not quite. I installed 7.3 and we were running 7.4. So although I can use the GUI, it doesn't have all the features which used to be present.
Some problems can be solved in one sitting. It should be clear that this saga continued over the course of a month, maybe more. Concurrently, I was doing other parts of my regular job, including the limping backups. Every now and then I would find the time to mount another assault on my problem du jour.
Time is a great healer in all sorts of activities. However, a balance must be struck. If all you do is monomaniacally try to solve the problem to the exclusion of other activities, firstly you will neglect important duties; but more importantly, you may get too close to the problem - you start going round in circles, stumbling blindly, getting confused, making mistakes.
I reckon I've solved more tough problems on the drive/walk/tram/train home, or in the shower, than I have at the keyboard.
One day, I tried a minor variation on an earlier command and had success.
jbedit -j 'Quantum PX502' -a -f /dev/rmt/2cbn -E 129
If you've persevered to here, you will recognise this as similar to a command listed earlier, but now I'm using 129 instead of the alleged hex 81.
Now 2 tape drives show up in the GUI. My original problem has been solved.
If only I hadn't uninstalled the console software!
Where was I going to find the version we used to have?
When you read job ads, you'll often see specifications that the prospective employer requires or desires. In my experience, these are rarely relevant. Sure, you want someone with a computer background, not a ballerina or a chef. You probably want someone with a Unix background if you run a Unix shop.
But getting more detailed than that seems to me pointless. If your looking for a mechanic, you want someone who has worked on cars, but do you really need someone who has worked on 1975 Dodge Darts?
I'm looking for some software. Which part of my CV is going to demonstrate my ability to find it? The question is not going to be asked. But this is exactly the sort of real-world problem that must be solved.
And that's my point. Most organisations are sufficiently idiosyncratic that the way they do things contributes to the steepest part of the learning curve. In-depth knowledge of a particular release of a distribution, or a specific rev of some software package is only transiently helpful.
The real requirement is to be able to get answers and solve problems; to perform the necessary research.
Before this job, I had used Legato, but I had not been in charge of the backup. I had no familiarity with managing the backup. But that task has not been difficult to pick up. It's just like getting behind the wheel of an unfamiliar car.
Finding where the software might be is a horse of a different colour.
I decided I needed a locate database. Not a genuine, complete, standard locate database; but something simple and workable. I didn't need to update it regularly, because I was only interested in files which were already there. A df showed that the root directory and /var were on separate filesystems. All the other filesystems, the 20TB, were out of my area of interest. I went with
nice find / /var -mount >> ~/tmp/locate.output
Now I can grep for what I need. It's not brilliant, but it will do.
It enabled me to find files which were helpful in other ways, but in creating my little ersatz locate I managed to overlook /usr/local. A colleague pointed me to an obscure subdirectory of /usr/local where I found rev 7.4 of the Legato software.
It was close to what we'd had before, but even that wasn't the end of the story. I found something dated later than the other candidates in a patch directory. So once more I went through the cycle of uninstall of the old version and reinstall of the new. But the latest item was in a patch directory. It complained that it could only be installed over an existing installation of the Legato software.
Patches have come to mean so many different things. When I was just starting out in computers, a patch was an analogue of what I use to repair my bike tubes. Typically it consisted of instructions to overwrite the contents of a file at a small number of locations with binary data; patching was done by hand. Over time, patching also came to mean a form of automated editing of source code. And patching is also used to describe the selective replacement of some files in a package. In fact, in the Solaris world, patches are packaged in a very similar way to software. There is not a lot of difference between pkgadd and patchadd. My guess is that they share an awful lot of codebase.
I have seen so-called jumbo patches from Sun which run to nearly a gigabyte. From humble beginnings...
I reinstalled 7.4 and then installed the patch and finally I was back to our original GUI console. Finally, after nearly a month, all the problems had been resolved.
A day or two later, another jukebox, attached to another machine, started to play up. As I write, it looks like I am looking at repeating the exercise above. I hope that my experience will allow me to get out the the other side with less drama.
| Share |
|
Talkback: Discuss this article with The Answer Gang
Henry has spent his days working with computers, mostly for computer manufacturers or software developers. His early computer experience includes relics such as punch cards, paper tape and mag tape. It is his darkest secret that he has been paid to do the sorts of things he would have paid money to be allowed to do. Just don't tell any of his employers.
He has used Linux as his personal home desktop since the family got its first PC in 1996. Back then, when the family shared the one PC, it was a dual-boot Windows/Slackware setup. Now that each member has his/her own computer, Henry somehow survives in a purely Linux world.
He lives in a suburb of Melbourne, Australia.
By Ben Okopnik
Some months ago, I set up a anti-spam system on my laptop which I wrote up back in issue #176. Having it based on my local machine, however, produces a significant amount of SMTP traffic. Since I wanted to minimize that load, I copied my .procmailrc, my whitelist, and my blacklist files to my home directory on the mail server. As a result, my mail traffic dropped from about 1k messages per day, plus the round trips to GMail for any emails in the "doubtful" category, to about 25 (valid) messages per day. This is especially wonderful since I often have a slow or fragile connection to the Net, depending on where I happen to be at the moment.
However, there's still a slight catch: the two list files mentioned above get updated on a regular basis. That is, if I get an email from someone and I decide that I'm going to correspond with that person regularly, I white-list them by hitting 'Ctrl-W' in Mutt (this, of course, requires setting up a keystroke alias in '~/.muttrc'.) Conversely, black-listing someone just takes hitting 'Ctrl-B'. Both of these actions, obviously, update their relevant list file - but they do so locally, and that's not where my (primary) spam filter is anymore. What to do? Logging into the mailserver on a regular basis and copying the files would be a hassle and an additional task that I'd have to remember - and that's precisely the kind of load that I don't want to add to my routine. Fortunately, automating it is easy.
Needless to say, your network transactions need to be secure. Fortunately, the standard tool for these, 'ssh', is perfectly suited to the task - and it even allows for secure connections without using a password. All you need to do is configure the two machines to perform authorization via public key exchange, essentially by copying your public key from one to the other. Here's the procedure:
ssh-keygen -tdsa
ssh user@remote_host 'cat>>~/.ssh/authorized_keys'<~/.ssh/id_dsa.pubEnter your password when prompted, and take pleasure in knowing that this is the last time you'll need to do so.
You should now be able to simply type 'ssh user@remote_host' and be logged in - no password required. In fact, you can make this exchange even simpler by giving your remote system a short alias; just add an entry in your local ~/.ssh/config file (create it if it doesn't exist) similar to this one:
Host sfs Hostname smithfamilyserver.com Protocol 2 User joe Compression yes
Once that's done, you'll be able to log into the above server simply by typing 'ssh sfs'. Nice, short, and simple.
At this point, I could simply copy the files that I want to the server by issuing an 'scp' command ('secure copy', part of the SSH suite); however, as a matter of good general practice, I like to only update the files if it's necessary - i.e., if they either don't exist or if the local files are different from the remote ones - and skip the update otherwise. The 'rsync' command can do exactly that - and I can even tell it to use SSH as the transport mechanism. All that takes is a couple of simple steps:
echo 'export RSYNC_RSH=/usr/bin/ssh -l remote_username' >> ~/.bash_profileNote: depending on your distro and on how you use your system, you may also need to add it to your ~/.xprofile ; in fact, you might as well do it just to make sure, since it won't do any harm. If you use a shell other than Bash, then presumably you'll know what to do to set and export that variable in that shell.
Now that both SSH and rsync are configured, updating the remote files is simply a matter of issuing the following command:
rsync ~/.mail-* sfs:
The colon, of course, tells 'rsync' (just as it would for the 'ssh' command) that we're copying the files to a remote host. The default remote location is your home directory on the remote machine; obviously, you can specify any directory you want there - assuming you have the right system permissions for it - by adding it immediately after the colon.
Automating it is just as easy: just create a line in your 'crontab' file that will run the above command on your desired schedule. For example, if I want these two files updated once an hour, I'll set up a cron job by typing 'crontab -e' and editing my crontab to look like this:
# m h dom mon dow command
05 * * * * /usr/bin/rsync /home/ben/.mail-{accept,deny}-list sfs:
Following the comment line, this means "on the 5th minute of every hour of every day of every month on every day of the week, execute this command." That task will now be executed for you, regular as clockwork - and without you having to think about it ever again.
Obviously, this isn't something that you'd go through just to copy a couple of files; that's easy enough without any special configuration. However, once you've set this up, it can serve you in many different ways - and SSH and rsync are both great tools to have in your toolbox. For me, they come in handy many times a day - and since I have them correctly configured, my network actions are just as simple as the ones involving files on my local machine. Here are a few examples:
ssh lg # Log into the Linux Gazette machine rsync file.html www:okopnik.com/misc # Copy or update 'file.html' to the 'misc/' directory of my website ssh 203k 'tail /var/log/messages' # See the last 10 entries in the log on a client's server rsync -a ~/devel rb:backup/`date +%%FT%%T`/ # Back up my 'devel' dir in a time-stamped subdir on my remote server
Enjoy, and let us know about any interesting uses you find for your newly-transparent network!
| Share |
|
Talkback: Discuss this article with The Answer Gang

Ben is the Editor-in-Chief for Linux Gazette and a member of The Answer Gang.
Ben was born in Moscow, Russia in 1962. He became interested in electricity at the tender age of six, promptly demonstrated it by sticking a fork into a socket and starting a fire, and has been falling down technological mineshafts ever since. He has been working with computers since the Elder Days, when they had to be built by soldering parts onto printed circuit boards and programs had to fit into 4k of memory (the recurring nightmares have almost faded, actually.)
His subsequent experiences include creating software in more than two dozen languages, network and database maintenance during the approach of a hurricane, writing articles for publications ranging from sailing magazines to technological journals, and teaching on a variety of topics ranging from Soviet weaponry and IBM hardware repair to Solaris and Linux administration, engineering, and programming. He also has the distinction of setting up the first Linux-based public access network in St. Georges, Bermuda as well as one of the first large-scale Linux-based mail servers in St. Thomas, USVI.
After a seven-year Atlantic/Caribbean cruise under sail and passages up and
down the East coast of the US, he is currently anchored in northern
Florida. His consulting business presents him with a variety of challenges,
and his second brain Palm Pilot is crammed full of alarms,
many of which contain exclamation points.
He has been working with Linux since 1997, and credits it with his complete loss of interest in waging nuclear warfare on parts of the Pacific Northwest.
Once upon a while ago I got a Christmas present from my fiancée. It was a book. Its title was "Time Management for System Administrators". So technically it was both a present and a message for me, because I am a professional system administrator working as a freelancer. In turn this article is both a book review and a collection of thoughts from the other end of the terminal. Many of you work as sysadmins, developers, project coordinators, or similar jobs. The problems of time and task management are very similar.
Do you have a hard time focusing your thoughts? Do you forget to deal with tasks, or do some tasks
slip through your mind? Do you get cranky when people ask questions or report problems by phone (or at all)? Are
you afraid of deadlines? Are you late for appointments? Trouble getting out of bed?
The chances of getting a yes from IT staff are quite high. I won't try to find a reason,
but I noticed that getting overloaded is very easy if you don't track issues before they turn into
major problems. The first step is to periodically review what you are doing and to make it a habit.
Developers call it refactoring, sysadmins call it maintenance, you can call it whatever you want, but
make it a habit to review what you are doing. First you need to know, then you can think of solutions
or improvement. It's very similar to diagnosing server problems or finding bugs in software.
The list of tools you use for work may be very long. Of all tools you use two are the most important ones: a calendar and a TODO list. These don't have to be digital. Analogue calendars and lists will do just fine - but make sure you can use them on a daily basis! Did you get the daily in the last sentence? Daily!
It means that you will use your calendar and TODO list for work every day. This implies that these tools must not
be inoperable as soon as you buy a new cell phone, play with the server setup of your CalDAV installation, fiddle
with firmware, buy a new notebook (the ones with the paper or the electronics inside) or run out of ink.
Your calendar allows for a basic planning of resources and your future. The TODO or task lists allows for tracking
what you still have to do and what you've already done. The latter is especially useful when figuring out days where you
were busy but have no idea of what you really did. In this case just look it up in your task list and you're done!
A remark about notes: do take notes! Do not try to remember anything - you will fail sooner or later! The act of writing down has a psychological side effect. You can forget immediately what you wrote down, because you can look it up later (when you browse through your task list to see open tasks). I never make phone calls without having my notes ready (and I tell people on the phone if I have notes or not; if not I ask them to call back later). This is a useful habit. It is also a good advice in case you cannot sleep. Whenever my mind is busy racing through the tasks I have still do to, I write everything down. Usually I'm calmer after that and can relax. You should try it some time.
Since I am a freelancer I suggest adding a time recording tool to the basic toolbox. Most companies use time recording tools for determining how much work was spent on which task. Ostensibly these records are needed for generating invoices after the tasks are finished, but tracking time is always a good idea. You should track time for all tasks. This helps in answering questions like "How long does it take to set up a LAMP server and deploy it in the DMZ?" or "Can you add a new backup client on server XY before the next backup run is activated?" A lot of time is spent on these estimates, so keep a list of frequent tasks or small projects and use it for reference.
I omitted a list of software on purpose, because finding the right tools is different for every one of us. Invest some time, try different tools, code the tools for yourself - do whatever you must, but do it. It's well worth the effort.
Well-designed communication protocols and a lower rate of interrupts are a benefit to every server
hardware and software application. The same is true for human beings. Computers can do multitasking
a lot better than most humans can. Ringing telephones (and other symmetric communication lines)
are the bane of focused work. What can you do?
In case you work as a team (i.e. you have co-workers) you can try to shield each other. Divide the
time where one of you is reachable, so that the others can work uninterrupted when not "on duty".
If you work alone, try defining and communicating "office hours". This doesn't mean that you should
turn down anyone calling you "out of line". It just means that you can try and control the interrupts
to some extent. Emergencies stay emergencies, of course.
As for instant messaging tools, e-mail clients and similar applications: Try to turn them off once in a while. For example if you are writing an article for the Linux Gazette, you most probably don't need to be notified of incoming e-mails. The same is true for instant messaging. Just before starting to write this article I set my Jabber status to "Do not disturb". Mailing lists are a welcome distraction, too. Do you have unread e-mails piling up in the folders of your favourite lists? If so try at least to automatically filter your incoming e-mails. It's also a good idea to unsubscribe from one mailing list per week or month (actually you can unsubscribe from RSS feeds and other sources of distraction, too). You don't need to get all the information, you just need to get the right information. Find your personal balance on a weekly or monthly basis.
As for the dreaded phone: In case you have no shield, you can nevertheless politely tell the caller that
you cannot deal with her/his problem in the moment and that you will call back. Make a note in your calendar
or in your task list, then proceed with what you were doing. If it's urgent, the caller will tell you so.
Keep in mind that others might not realise
that you are occupied with other tasks. Cell phone numbers do not have presence information.
I cannot stress this too much: always be polite! Most people really understand when you are busy. Most of the
time you just have to acknowledge their call and postpone the conversation.
Meetings are fun! After a day filled with meetings most of us feel like having wasted their time. If this is the case then something went clearly wrong. Meetings are necessary, but you have to be aware of their purpose.
What if someone is late for a meeting? Easy: try hard not to care. Don't start any meeting a second later than
announced! We live in a world where reliable time sources are abundant (think NTP clients). Everyone has a chance
to synchronise and everyone has sufficient means of communication (think cell phones and wireless gadgets). If not, then there's the summary. Every meeting
has a summary which should be distributed to all participants. So you don't have to wait if you lead the meeting,
and you don't have to hurry if you're late. You can catch up later.
What about decisions? No problem there, either. If you're late for a meeting, you've already claimed that you do not care.
If you care, inform about being delayed or be on time.
Every company and every individual has cycles. Every day, I go to sleep and I get up. Once every month, I write
invoices and pay my rent. Every winter semester, I teach a class. Every night, the backup server executes the
backup schedule, and every Saturday the backups are copied to the archive server.
You have to identify cycles in your job and incorporate them into your schedule. As soon as you have done that,
the amount of "sudden surprises" will decrease. Knowing what happens next is also a good way of disttributing your
workload more evenly. Remember, I am only talking about periodical events here.
Once you know your cycles, try to automate tasks. Technically this isn't coupled to cycles; you should always
automate your tasks. Servers have automatic upgrades, garbage collections, backups, scripted actions; you need
to catch up! My fiancée persuaded me to find or implement a time recording system that automatically
generates the invoices for all tasks of a month. It took me some weeks to implement it (and it's not "ready" yet, but
it's working). This means I record my tasks daily, and at the beginning of every month I browse through the
automatically generated PDFs on the fileserver, check the invoices and send them to customers. Before that,
I spent hours of wading through the notes on my desk and through the entries in my calendar, cursing, copying
task descriptions, and remembering all (?) the things I hadn't recorded. So this one day of bad mood has been effectively
programmed away.
It's just an example, but I am sure that you will find a lot of tasks in your day that can be automated.
Do it! It frees your mind and you can concentrate on more important issues. If you don't believe this, ask your
local sysadmin. These people usually write scripts for everything, too. It really works.
There are other cycles tied to your biology as well. Some people like to get up early, some like to work into the night. There's no problem with that as long as you a) know your personal circadian rhythm and b) are nevertheless able to interact with society.
There will be periods where you will definitely be unable to do concentrated work. For example our office will be cleaned every Tuesday (also a perfect example for a cycle). This is a pretty regular event. Since there will be a lot of cleaning around my desk and in the rooms, I always try to get the things done that don't need a lot of concentration: paperwork, phone calls, light correspondence, sorting stuff, maybe even cleaning my desk, too. Plan your schedule according to these events. Try to combine the right task with the right moment.
Deadlines are the driving force behind everything. Actually they're quite old and most of them are not negotiable. Gather enough food for the Winter. Give a talk at the conference about cluster filesystems. Write and submit an article for the Linux Gazette before the 20th of every month. The list is long. So what about deadlines? Nothing. They just are. Of course they can cause a lot of trouble, but having deadlines is the only way of really getting things done. They force you to assign priorities to your tasks. Make sure you use them for requests and all of your tasks.
Believe it or not, you cannot do everything on your own. It's impossible, even if you got root.
It can't be done. So first thing you should do is to stop trying to do everyting yourself! Now!
Learn to trust others. Learn to ask them for help and to accept what they are doing. The hardest part is
accepting that others deal with tasks a little differently. That's why we can talk to each other and set
guidelines. This can be done with politeness and cooperation. And it works - provided you give it a try.
So I guessed right, this isn't a book review at all. I left out most of the stuff that Thomas A. Limoncelli describes in his book. It's also not rocket science. Most of the hints and best pratices are known to anyone who's ever worked in a company or as a freelancer. You just need a wake up call to improve your habits from time to time. I suggest taking a look at "Time Management for System Administrators". There's a second link to a Wikipedia article about "verbal self defense". Check it out, too. It's about being polite even in the worst of all situations you can imagine. If you work in sales you know what I am talking about, but system administrators have "difficult" customers, too. Difficult is not the right word. If someone has lost data or is frustrated by the behaviour of applications he/she has all the right in the world to be "difficult". Bear that in mind and skip the luser joke, people turn to you for help, not because they want to make your life "difficult".
| Share |
|
Talkback: Discuss this article with The Answer Gang

René was born in the year of Atari's founding and the release of the game Pong. Since his early youth he started taking things apart to see how they work. He couldn't even pass construction sites without looking for electrical wires that might seem interesting. The interest in computing began when his grandfather bought him a 4-bit microcontroller with 256 byte RAM and a 4096 byte operating system, forcing him to learn assembler before any other language.
After finishing school he went to university in order to study physics. He then collected experiences with a C64, a C128, two Amigas, DEC's Ultrix, OpenVMS and finally GNU/Linux on a PC in 1997. He is using Linux since this day and still likes to take things apart und put them together again. Freedom of tinkering brought him close to the Free Software movement, where he puts some effort into the right to understand how things work. He is also involved with civil liberty groups focusing on digital rights.
Since 1999 he is offering his skills as a freelancer. His main activities include system/network administration, scripting and consulting. In 2001 he started to give lectures on computer security at the Technikum Wien. Apart from staring into computer monitors, inspecting hardware and talking to network equipment he is fond of scuba diving, writing, or photographing with his digital camera. He would like to have a go at storytelling and roleplaying again as soon as he finds some more spare time on his backup devices.
Linux is the best general purpose operating system for controlling hardware. It allows fast and well-controlled access to Input/Output ports such as the parallel port and serial port as well as plug in cards. The Linux Gazette has two good articles on how to achieve this, see [1] and [2]. If you need real time response, consider the RTAI extension of Linux, again Linux Gazette has some very useful articles that use RTAI to achieve motor control [3], make a stroboscope [4], and use a joy-stick to control servo motors [5] .
Many of these approaches rely on direct access to ports such as the parallel port, but this is becoming increasingly difficult as laptops and newer desktops rely on USB as the sole input-output (IO) mechanism. Hardware access via USB requires a plug-in USB module that translates USB to basic digital IO, and if possible analogue IO. These boards are relatively cheap, starting from about US$35. It's also possible to build your own USB interface based on Open Source designs such as VUSB [6] .
In this article we will show you how to use a very flexible USB interface board called Open-USB-IO [7] to achieve speed control of a DC motor without any form of shaft encoder. Open-USB-IO provides a lot of options for a very reasonable price. Notable hardware interfaces include digital IO with switches and LEDs, analogue inputs, three channels of PWM (Pulse Width Modulation), a serial port, and seven open collector drivers for motors. The USB stack is written in C that runs on an ATMEGA32 microprocessor; remarkably, you can add your own code to the USB code and then use a symbolic debugger to debug that code. Open-USB-IO hardware can thus be controlled from code running on the Linux box as we will do in this article, or from code that runs on the ATMEGA32 microprocessor (if we get enough requests to the editor I will write an article showing how to write and debug code on the microprocessor from the Linux environment). The web site also has an extensive manual with many examples, and the full circuit of the board.
 There is a wide variety of DC motors; see Wikipedia [8]
for a good overview. We will be dealing with the permanent magnet type
which is the most common DC motor for small applications. The model of a DC
motor at stable speed is shown in Figure 1. It's quite simple - if you can
remember Ohms Law, then
you can understand it. The voltage across the motor must match the battery
voltage and at a steady speed this is made up out of two parts: the first
is the resistance losses through the motor equal to
Im*Rm. The second part is caused by the
spinning rotor acting as a generator which creates a voltage that opposes
the battery. This voltage is often called the back-EMF
(Vbemf) of the motor and is directly proportion to
speed.
There is a wide variety of DC motors; see Wikipedia [8]
for a good overview. We will be dealing with the permanent magnet type
which is the most common DC motor for small applications. The model of a DC
motor at stable speed is shown in Figure 1. It's quite simple - if you can
remember Ohms Law, then
you can understand it. The voltage across the motor must match the battery
voltage and at a steady speed this is made up out of two parts: the first
is the resistance losses through the motor equal to
Im*Rm. The second part is caused by the
spinning rotor acting as a generator which creates a voltage that opposes
the battery. This voltage is often called the back-EMF
(Vbemf) of the motor and is directly proportion to
speed.
Vbatt = Im * Rm + Vbemf (1) Vbatt= battery voltage
Vbemf = k * motor_speed (2) Rm = motor resistance
Motor Torque = c * Im (3) Vbemf = back emf of motor
Im = motor current
k,c = constants
When the motor starts it will speed up until the Vbemf rises and together with Im*Rm balances Vbatt. If the motor has a mechanical load applied then it will slow down until a new balance is reached, the current must increase so the back-EMF drop is matched by a rise in the Im*Rm voltage drop. The increased current will increase the torque of the motor to cope with the new mechanical load.
Given the formulas above it's possible to work out the speed of the DC motor using just electrical measurement, thus no shaft encoder is required. There are two basic approaches -
motor_speed = ( Vbatt - Im*Rm) / k (4) motor_speed = Vbemf/k (5)
Formula 4 requires measurement of the motor current, formula 5 requires measurement of the back-EMF of the motor. On first inspection measuring motor current looks easiest, simply add a very small resistor Rs in series with the motor and measure the voltage drop Vs across that resistor. The motor current is simply Vs/Is. However, this has the disadvantage of wasting energy, requiring amplification and measurement of very small voltages, and requires a high current, low value resistor. Measuring the back-EMF of the motor would not have these problems - but there is no point where back-EMF can be directly measured when the motor is driven with a steady voltage. Fortunately, the back-EMF can be measured when a motor is driven with PWM (Pulse Width Modulation).
To see a more complete treatment of a DC motor and a good SPICE model, see http://www.ecircuitcenter.com/circuits/dc_motor_model/dcmotor_model.htm.
 Pulse Width Modulation, usually
abbreviated to just PWM, is a clever way to create a low voltage from a
high voltage without any losses. Figure 2 shows a simple PWM waveform where
a battery is driving a heater element, with an active duty cycle of
Ton / Tperiod. The heater has a thermal
inertia, so the heat output will not vary in response to the fast on and
off pulses. This inertia averages the out the pulses to give an effective
voltage of Vbatt * Ton / Tperiod.
A load like a heater or a motor can be given a variable voltage just by
using a switch opening and closing at high speed. This approach is much
better than using a voltage regulator or series resistor, as there is no
energy loss.
Pulse Width Modulation, usually
abbreviated to just PWM, is a clever way to create a low voltage from a
high voltage without any losses. Figure 2 shows a simple PWM waveform where
a battery is driving a heater element, with an active duty cycle of
Ton / Tperiod. The heater has a thermal
inertia, so the heat output will not vary in response to the fast on and
off pulses. This inertia averages the out the pulses to give an effective
voltage of Vbatt * Ton / Tperiod.
A load like a heater or a motor can be given a variable voltage just by
using a switch opening and closing at high speed. This approach is much
better than using a voltage regulator or series resistor, as there is no
energy loss.
 Figure 3 shows the waveform of a
motor driven by a PWM. When the switch disconnects the motor, the voltage
measured at Vx is not Vbatt, it is
reduced by the back-EMF of the motor. PWM not only allows a variable
voltage to be fed to the motor, it gives the opportunity to directly
measure the motor back-EMF for the purposes of speed control. The waveform
at Vx is far from perfect for our needs. When the switch first turns off
the motor's stray inductance gives a voltage kick, typically 0.5
milliseconds for a small motor. After the inductive kick has finished, the
back-EMF is not smooth and has considerable noise. This waveform needs to
be smoothed out in some way to give a single measurement for
Vbemf over one cycle. When the switch is turned on,
again the result is not perfect: Vx is not zero volts
because all real switches have a finite resistance. For a mechanical switch
this is very low but for electronic switches this will be noticeable and
must be taken into account.
Figure 3 shows the waveform of a
motor driven by a PWM. When the switch disconnects the motor, the voltage
measured at Vx is not Vbatt, it is
reduced by the back-EMF of the motor. PWM not only allows a variable
voltage to be fed to the motor, it gives the opportunity to directly
measure the motor back-EMF for the purposes of speed control. The waveform
at Vx is far from perfect for our needs. When the switch first turns off
the motor's stray inductance gives a voltage kick, typically 0.5
milliseconds for a small motor. After the inductive kick has finished, the
back-EMF is not smooth and has considerable noise. This waveform needs to
be smoothed out in some way to give a single measurement for
Vbemf over one cycle. When the switch is turned on,
again the result is not perfect: Vx is not zero volts
because all real switches have a finite resistance. For a mechanical switch
this is very low but for electronic switches this will be noticeable and
must be taken into account.
Why is there a diode across the motor? A motor is a an inductor, and inductors can generate a huge voltage spike if the current through them is suddenly turned off. This spike can be hundreds of volts and destroy the switching device. The diode allows the current to continue to flow in a loop through the inductor while the switch is turned off. This is shown in figure 3 as Vx rises above Vbatt by the voltage drop across the diode.
Motor speed can be estimated as follows-
Average_Vm = (Vbatt-Vbemf) * Poff + Von * Pon (6)
Poff = proportion of time switch is off = Toff/Tperiod, 0-1.
Pon = proportion of time switch is on = Ton/Tperiod, 0-1.
Von = voltage across switch when turned on, caused by internal switch resistance.
Vbemf = Vbatt - (Average_Vm - Von*Pon)/Poff (7)
The back-EMF, Vbemf, can be taken as a proxy for speed as the speed is directly proportional to this value. The Average_Vm can be created by continually sampling Vm at high speed and taking an average, or by using a low pass filter to create a stable voltage. We will use the second approach as shown in Figure 5 because USB interfaces generally work at low speed, around 250 commands a second at best and its not possible to sample fast enough to be certain of getting a reliable value.
 The Open-USB-IO board, shown in
Figure 4 opposite, comes with a command line program that allows you to
control all the hardware features of the board from the comfort of your
Linux computer. Common features such as PWM are very easy to use. Download
the "ousb" program from this
website and place it in your path; /usr/local/bin is convenient if you
have root privileges.
The Open-USB-IO board, shown in
Figure 4 opposite, comes with a command line program that allows you to
control all the hardware features of the board from the comfort of your
Linux computer. Common features such as PWM are very easy to use. Download
the "ousb" program from this
website and place it in your path; /usr/local/bin is convenient if you
have root privileges.
To demonstrate the PWM function, we will use PWM 1 which lights LED 3 at various light intensities. In the commands below note that the # and beyond are comments, and do not need to be typed in.
ousb pwm-freq 1 45 # set PWM 1 frequency to 45 Hz. ousb pwm 1 2 # set PWM duty cycle to 2% on. ousb pwm 1 100 # PWM 1 is 100%, always on. ousb pwm 1 0 # PWM is 0%, always off.
Note that the pwm-freq command must be used first to set frequency but after that any number of pwm commands can be used to change the duty cycle.
The Open-USB-IO board has many useful features, one of which is seven open collector drivers that can cope with up to 50 volts, and carry up to 500 milliamps, enough for most small DC motors. Open collector drivers act as a switch connected on one side to zero volts, just as in the circuits above. One of these is controlled by PWM 1 and can be used to drive a small motor. There are eight ADC (Analogue to Digital Converter) inputs and one of these, ADC0, will be used to sense the motor voltage. The USB link to the computer supplies 5 volts, and can in theory be used to drive a small motor. In practice the motor injects a lot of electrical noise to the power supply and this can crash the microprocessor, so it's best to use an external plug-pack that plugs into the external socket (top right of Figure 4). The plug pack can be either unregulated or regulated, as long as it is rated at up to about 1.5 times the motor voltage. If you're an electronics experimenter, there is a good chance that you have one of these in your junk box.
 One thing that Open-USB-IO lacks is
a low pass filter to smooth out the noisy motor voltage as shown in Figure
3. Luckily, the board has a prototype area that can easily fit the
necessary components. Figure 5 shows the circuit of a simple smoothing
filter and figure 6 shows how it can be wired into the prototype area. The
smoothing filter drops the observed voltage by about 1/3, which allows the
motor to be driven by up to 15 volts without overloading the 5 volt powered
microprocessor and ADC input. The 47kΩ resistor also gives some
protection to the ADC input in case of voltage spikes when the switch turns
off and the inductive kick occurs. The corner frequency
is about 1 Hertz, so it will smooth out the 45 Hertz PWM waveform to a
reasonably stable voltage. The capacitor will need to be an electrolytic
which is polarized, and its plus side must be connected to the resistor
joint and not zero volts.
One thing that Open-USB-IO lacks is
a low pass filter to smooth out the noisy motor voltage as shown in Figure
3. Luckily, the board has a prototype area that can easily fit the
necessary components. Figure 5 shows the circuit of a simple smoothing
filter and figure 6 shows how it can be wired into the prototype area. The
smoothing filter drops the observed voltage by about 1/3, which allows the
motor to be driven by up to 15 volts without overloading the 5 volt powered
microprocessor and ADC input. The 47kΩ resistor also gives some
protection to the ADC input in case of voltage spikes when the switch turns
off and the inductive kick occurs. The corner frequency
is about 1 Hertz, so it will smooth out the 45 Hertz PWM waveform to a
reasonably stable voltage. The capacitor will need to be an electrolytic
which is polarized, and its plus side must be connected to the resistor
joint and not zero volts.
 Figure 6, opposite, shows a small motor bolted onto the Open-USB-IO board for
convenience. The connections needed for the circuitry are all on J5, the 20
by 2 IDC pin array at the top of the board. All even pins, the left hand
row, are connected to zero volts and all the right hand row have useful
connections. Each of the right hand row pins is also connected to a solder
pad right next to the pin. This makes it easy to solder in your own
circuitry. The motor leads are soldered to 2-pin headers which can be
pushed onto J5. The zero volt connection is at the top of the board and is
connected to the 22kΩ resistor and 10µF capacitor. The 47kΩ
resistor connects to the other end of the resistor and capacitor just
mentioned and on to pin 27 of J5. The joint of all three components has a
wire running down to pin 1 of J5 which is ADC0. This photo has a 1 kΩ
resistor between pins 37 and 27, which is not needed for this application.
Figure 6, opposite, shows a small motor bolted onto the Open-USB-IO board for
convenience. The connections needed for the circuitry are all on J5, the 20
by 2 IDC pin array at the top of the board. All even pins, the left hand
row, are connected to zero volts and all the right hand row have useful
connections. Each of the right hand row pins is also connected to a solder
pad right next to the pin. This makes it easy to solder in your own
circuitry. The motor leads are soldered to 2-pin headers which can be
pushed onto J5. The zero volt connection is at the top of the board and is
connected to the 22kΩ resistor and 10µF capacitor. The 47kΩ
resistor connects to the other end of the resistor and capacitor just
mentioned and on to pin 27 of J5. The joint of all three components has a
wire running down to pin 1 of J5 which is ADC0. This photo has a 1 kΩ
resistor between pins 37 and 27, which is not needed for this application.
Be careful with the connections as pin 27 and 37 will have the plug pack voltages which are probably well over 5 volts. If these pins are accidentally connected to the wrong place then damage may be done to the 5 volt powered devices on the board.
The complete C++ code to implement motor control can be found here. Below, key elements of the code will be discussed.
The code in Figure 7 allows any C++ program to directly access the Open-USB-IO board by calling the ousb program. If you prefer C, then please see the extensive Open-USB-IO manual at www.pjradcliffe.wordpress.com . The function opens a pipe to a newly created ousb process and sends it the text string of commands passed in with str. The ousb process then finishes and returns a result, which is converted into an integer and returned to the calling code. The extra "-r" in the ousb command tells ousb to just return the numerical result and omit any useful text description. This is ideal when ousb is called from other programs and not a human using the command line.
Figure 7: C++ Function to Control USB Hardware
int cpp_do_ousb_command(string *str)
{ FILE *fpipe ;
if ( !(fpipe = (FILE*)popen(str->c_str(),"r")))
{ cout << "pipe error" << endl ;
exit(0) ;
}
char line[100] ;
fgets( line, sizeof line, fpipe) ;
pclose(fpipe) ;
*str = line ; // Caller can see whole returned string.
return( atoi(str->c_str())) ; // try returning string as integer.
}
...
new_adc0_read = cpp_do_ousb_command("ousb -r adc 0") ;
...
Before the motor can be controlled, two constants must be determined, Von (switch on voltage drop) and Vbatt (power supply voltage). One could measure these voltages and put them into the program as a constants - but it's handier to write a little code to automatically find these values. There is one disadvantage: the motor will run at full speed for a second when the program starts up. If a period of full speed is unacceptable, then the Von value must be turned into a constant.
Figure 8: Automatic Determination of Motor Constants
//--- set PWM frequency. str = "ousb pwm-freq 1 45" ; cpp_do_ousb_command(&str) ; //--- calculate Vext using pwm of zero. str = "ousb pwm 1 0" ; cpp_do_ousb_command(&str) ; sleep(2) ; // allow motor to stop if going. str = "ousb -r adc 0" ; float Vext = cpp_do_ousb_command(&str) ; //--- calculate ADC for motor full on, Vsat str = "ousb pwm 1 100" ; cpp_do_ousb_command(&str) ; sleep(1) ; // allow motor to get up to speed. str = "ousb -r adc 0" ; float Vsat = cpp_do_ousb_command(&str) ; cout << " Calibration: Vsat= " << Vsat << ", Vext= " << Vext << endl ;
Figure 9, below, shows the control loop which attempts to keep the motor speed constant. The loop tries to ensure that the motor back-EMF (Vgen below) matches the target back-EMF (Vgen_goal). On line 6, Vgen is calculated using Equation 7; on line 7, a change to the pwm duty cycle is calculated using "gain" times the difference between Vgen measured and Vgen_goal. Line 8 accounts for maths errors and resets the pwm to zero if any errors have occurred. Similarly, lines 8 and 9 keep the PWM value within allowable limits. Finally, lines 13 to 16 are responsible for sending the next PWM value to the Open-USB-IO board.
Figure 9: Motor Control Loop
1 float Vavg, Vgen ;
2 while(1)
3 {//--- read ADC input and calculate next PWM value.
4 str = "ousb -r adc 0" ;
5 Vavg = cpp_do_ousb_command(&str) ;
6 Vgen = Vext - (Vavg - Vsat*pwm/100) / ( 1 - pwm/100) ;
7 pwm += gain*(Vgen_goal - Vgen) ;
8 if (!isnormal(pwm)) pwm = 0 ; // if maths error set motor to stop.
9 if (pwm>100) pwm = 100 ;
10 if (pwm<0) pwm = 0 ;
11 cout << " pwm%= " << (int)pwm << ", ADC0= " << Vavg
<< ", Vgen= " << (int)Vgen << ", Vgoal= " << Vgen_goal << endl ;
12 //--- form PWM command and send to board.
13 stst.str("") ;
14 stst << pwm ;
15 str = "ousb pwm 1 " + stst.str() ;
16 cpp_do_ousb_command(&str) ;
17 }
The gain is a constant that can dramatically affect performance. Consider putting a mechanical load on the motor: a small gain will mean the motor slows down and then slowly creeps back up to speed as the PWM value is slowly moved up. A higher gain will get a quicker response but there may be overshoot (going above the desired speed) or limit cycles (small oscillations around the desired speed). You may well need to change the gain to suit your motor and power supply voltage.
The basic plot of this article can be extended in many ways to get better control of motor speed or drive larger motors.
The code to control the motor could be moved into the microprocessor so the Linux computer need only send down the desired speed; this is probably best done with the live-DVD of development tools that can be found at http://www.interestingbytes.wordpress.com. See the /home/user/projects/Co-USB folder for a very simple way to add your own code to the USB interface code. The microprocessor code you write can be debugged using a symbolic debugger which also include breakpoints. The manual and examples on how to achieve this are quite clear and helpful.
Control code in the microprocessor can work much faster than commands sent via a USB connection. The ousb program can be called at most about 25 times a second. By using pipes carefully the ousb program can stay in memory and can cope with 250 commands per second (see the live-DVD mentioned above). Code in the microprocessor can read the ADC at about 30,000 times per second and so get much finer grained control. For example, referring to Figure 3, the inductive kick pollutes the estimate of the motor back-EMF during the PWM off period. A microprocessor could do away with the smoothing capacitor and sample the waveform just through the resistors. It could then average the voltage during the PWM off period but exclude the inductive kick and so get a more accurate estimate of the back-EMF and hence the speed. The code in this article does not exclude the inductive kick and this can lead to problems when the PWM off cycle is very small: the control loop "believes" the back-EMF is negative and so gets totally confused. The simplest solution is to limit the PWM duty cycle to something less than 100% so as to get a reasonable estimate for the back-EMF.
The motor control circuit assumes that the on-board open collector drivers can handle up to 500 milliamps which is adequate for many small motors. If a higher current motor is to be used then it may be best to use a power MOSFET such as the BUZ71 or IRF520. These can be driven with 0 or +5v and drive up to 3 amps given a reasonable heat sink, and the microprocessor pins on Open-USB-IO can be directly used for this. Currents over 3 amps need a higher gate drive voltage and the on-board open collector driver may be used to achieve this.
The frequency chosen for the PWM is only 45 Hz and this can be changed. Higher frequencies start to have more problems with the inductive kick period distorting the estimate of back-EMF. Frequencies above about 70 Hertz and below 20 KHz can be heard as an annoying buzz and so are usually avoided. The Open-USB-IO PWM 2 can provide much finer grained frequency control and can be used to investigate frequency issues. This PWM comes out on pin 23 of J5 and does not have its own LED. Interestingly, a PWM frequency of 45 kHz can provide some speed control using the algorithms above: this works because the inductive kick rise time also depends on motor speed and so a smoothed version of the motor voltage gives some information about motor speed. However, the 45 Hz PWM is much better at keeping motor speed to a constant value.
This article sheds light on several important issues for anyone who wishes to control real hardware from their Linux computer. First of all, Linux is the best general purpose operating system for controlling hardware. Next, given that USB is becoming the only way that many computers will interface with external hardware means that some form of USB interface board is necessary. We found the Open-USB-IO to be particularly useful but many other boards would do.
The core of this article showed how speed control of a DC motor can be achieved using only electrical means without any need for a shaft encoder. The Open-USB-IO board can in theory control up to seven motors this way. You can use the code and circuitry directly, or extend it to suit your own needs.That's one of the great joys of Linux: since so much of it is Open Source, you can look at it, understand it, and extend it for your own purposes.
[1] Radcliffe, Pj, "Linux: A Clear Winner for Hardware I/O", retrieved from http://linuxgazette.net/112/radcliffe.html
[2] Chong D., Chong P., "Linux Analog to Digital Converter", retrieved from http://linuxgazette.net/118/chong.html
[3] Sreejith N., "Digital Speed Controller using RTAI/Linux", retrieved from http://linuxgazette.net/118/sreejith.html
[4] Pramode C.E., "Measure CPU Fan Speed with an RTAI/LXRT Stroboscope!", retrieved from http://linuxgazette.net/114/pramode.html
[5] Pramode C.E., "Simple Joystick control of a servo motor with RTAI/Linux", retrieved from http://linuxgazette.net/101/pramode.html
[6] Objective Development's VUSB, a GPL USB stack, retrieved from http://www.obdev.at/products/vusb/index.html
[7] Open-USB-IO board, manual, examples and reference material, retrieved from http://www.pjradcliffe.wordpress.com
[8] "Brushed DC electric motor" at Wikipedia, retrieved from http://en.wikipedia.org/wiki/Brushed_DC_electric_motor
| Share |
|
Talkback: Discuss this article with The Answer Gang
PJ Radcliffe is a senior lecturer at RMIT University in Melbourne
Australia. His career started as an electronics/microprocessor engineer at
Ericsson followed by consulting work in hardware and software, then an
academic position at RMIT. Teaching has become a great pleasure, especially
when linked with technologies and issues relevant to the workplace. In 2004
he received an award for "Student Centred Learning" from RMIT.
For many years he was a Microsoft junkie - but then had to run a lecture
series on Linux, and got hooked. Who wouldn't be? Linux can be used as a
turn-key GUI like Windows, a powerful server, and to control hardware.
His interests apart from Linux, software and hardware are... ( I'll
remember in a tick)... (context switch)... a lovely wife who hates
computers (the other women in my life, you see), three really nice kids,
and a rather large garden.

Collaboration. It's a buzzword, like 'innovative' and 'cloud computing', and like most words, it can be used or misused. It reminds me of the words openness and community. It reminds me of open source. Rivals and allies such as Microsoft, Google, Red Hat, Oracle, HP, and so many others working on code in the Linux kernel is arguably one of the greatest examples of collaboration in the technology world.
Another great example of collaboration across the globe is Wikipedia, and I thought it would be appropriate to use its definition of 'Collaboration' as part of the introduction to my article. Per Wikipedia [1]:
Collaboration is a recursive process where two or more people or organizations work together in an intersection of common goals - for example, an intellectual endeavor that is creative in nature - by sharing knowledge, learning and building consensus.
It is with that definition in mind that I decided to share with you five specific tools for Linux that I either currently use or have used in the past to improve collaboration among individuals and departmental teams. I will point out that, for each of the tools I will mention, there most likely exist several other alternatives that may or may not do as good as a job as the ones I have decided to write about - after all, that is the beauty of the open source world.
Vncserver has been around for years as desktop sharing in multiple Operating Systems. Starting with Gnome 2.8, the Vino VNC server started being shipped by default. Vino allows a user to share the desktop with other remote users while granting them fine-grained access.
If enabled, the vino server only starts up once the user logs into their Gnome session. When the remote user tries to connect to the local desktop a pop-up window will show up on the local desktop and the remote user will only be able to access the desktop if the local user accepts the connection request.
To start up the connection with the desktop, all the remote user needs is a VNC client like vinagre. Some other possible clients are tigervnc for Fedora, tightvnc, or realvnc for Ubuntu.
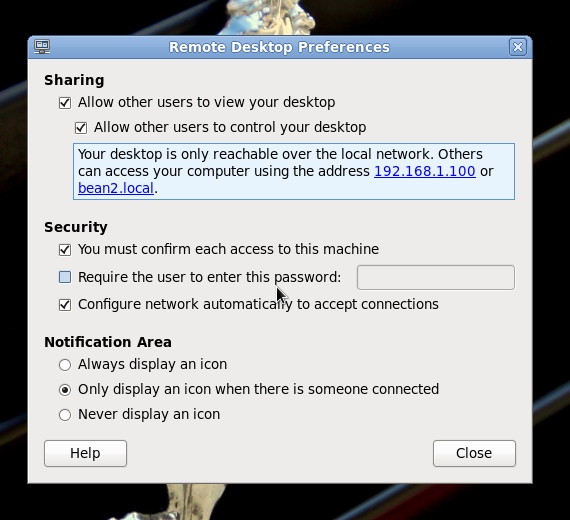
A few things to be mindful of when enabling remote desktop under Gnome:
It is almost impossible nowadays to talk about collaboration in a technical environment without talking about a Wiki. I will even assume that virtually every person with some sort of networked device has either gained or contributed some wiki-based knowledge, even if they were not aware they were using a wiki.
With that said, installing a wiki on a Linux server has become simpler and simpler over the years. For this article, I picked PHP based wiki DokuWiki, which can be easily installed by running:
On Fedora:
yum install dokuwiki
On Ubuntu:
apt-get install dokuwiki
You will then have to make sure Apache is running, and should be able to access your newly installed wiki at: http://yourhost.com/dokuwiki/
Some other wikis available 'out of the box' for your installation on both Fedora and Ubuntu are mediawiki, trac, kwiki (perl-kwiki in Fedora), and moin (python-moin in Ubuntu).
A couple of years ago, I was invited to a meeting at work to discuss a project a couple of the developers were working on. What I thought was going to happen was that someone would hook up a projector to their laptop, and all eight of us would stare at the wall and every once in a while give a suggestion about some excessive 'if' statement or a poorly-designed method. Well, I was wrong. The lead developer popped Gobby on the screen, created a session, and asked the rest of us to install it and join the session.
From there, we started writing pseudo and real code, creating a 'to do' list, and updating documentation in the source code. Gobby is that cool!
Once you create a session, all other gobby instances in the network will automatically detect the created session. If you want a private session, add a password to your session. Each user is requested to pick a name and a color and as they modify the document, their picked color highlights the text they contribute.
To install gobby on Fedora:
yum install gobby
On Ubuntu:
apt-get install gobby
Have you ever tried walking someone through steps on how to accomplish a task on the desktop? And then they forget what they did, and ask you again six months later, and you have to walk through it all over again?
I have had this problem before, and it didn't take long until I decided to start using a screencast application on GNOME to record any tutorials I might end up working on.
I started using istanbul, a little python application that will place a 'record' button on your GNOME panel, and allow you to record what's going on your screen. It also let's you change the resolution of the screen and capture sound as you go through your motions.

Take a look at this small sample of istanbul at work.
Along with a compiler or interpreter, a version control system is arguably one of the most important tools a developer will use from day to day. As you probably already know, it allows one or more developers to store, retrieve, log, identify, and merge revisions of a file through time.
A few version control systems available under Linux are cvs, subversion, mercurial, bzr (bazaar), and git.
At work, as an organization, we've migrated from subversion and cvs to git, and that's mostly the reason why I decided to mention it in this article. If you have never tried git, I highly suggest you check it out. Git was originally written by Linus Torvalds for the Linux kernel development, and over the past few years has become more and more popular around the open source community. Just take a look at this list of current projects that are using Git as their version control system.
I also recommend you take a look at the wikipedia page about git and its official home to find out a bit more of its history, design and implementation.
Installing git on Fedora:
yum install git
on Ubuntu:
apt-get install git
Creating a repo is as simple as [2]:
$ cd (project-directory) $ git init $ (add some files) $ git add . $ git commit -m 'Initial commit'
And checking out some files from a repo and creating a patch [2]:
$ git clone git://github.com/git/hello-world.git $ cd hello-world $ (edit files) $ git add (files) $ git commit -m 'Explain what I changed' $ git format-patch origin/master
Once you start creating branches, and squash merges with git, you may find keeping track of diffs, logs and different branches a bit overwhelming at times. A great little tool a friend of mine introduced me to is called: tig, which is "a repository browser for the git revision control system that additionally can act as a pager for output from various git commands." [3]
Because some of the tools discussed above are client-server based, you should always check your firewall rules. Also, these tools are just the tip of the iceberg; technologies like microblogging, social networking, email, chatting, and so many others could easily be adapted into our day-to-day collaboration requirements. As you work through them with your organization, always take into consideration your infrastructure and security requirements before implementing any of these tools or services.
Unless you have a commitment from your organization or your team mates to work together in sharing knowledge and keeping this knowledge up-to-date, all of these collaboration tools at the end of the day sum up to just that: tools.
| Share |
|
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/silva.jpg)
Anderson Silva works as an IT Release Engineer at Red Hat, Inc. He holds a BS in Computer Science from Liberty University, a MS in Information Systems from the University of Maine. He is a Red Hat Certified Architect and has authored several Linux based articles for publications like: Linux Gazette, Revista do Linux, and Red Hat Magazine. Anderson has been married to his High School sweetheart, Joanna (who helps him edit his articles before submission), for 11 years, and has 3 kids. When he is not working or writing, he enjoys photography, spending time with his family, road cycling, watching Formula 1 and Indycar races, and taking his boys karting,
These images are scaled down to minimize horizontal scrolling.
Flash problems? All HelpDex cartoons are at Shane's web site,
www.shanecollinge.com.
| Share |
|
Talkback: Discuss this article with The Answer Gang
 Part computer programmer, part cartoonist, part Mars Bar. At night, he runs
around in his brightly-coloured underwear fighting criminals. During the
day... well, he just runs around in his brightly-coloured underwear. He
eats when he's hungry and sleeps when he's sleepy.
Part computer programmer, part cartoonist, part Mars Bar. At night, he runs
around in his brightly-coloured underwear fighting criminals. During the
day... well, he just runs around in his brightly-coloured underwear. He
eats when he's hungry and sleeps when he's sleepy.
These images are scaled down to minimize horizontal scrolling.
All "Doomed to Obscurity" cartoons are at Pete Trbovich's site,
http://penguinpetes.com/Doomed_to_Obscurity/.
| Share |
|
Talkback: Discuss this article with The Answer Gang
Born September 22, 1969, in Gardena, California, "Penguin" Pete Trbovich today resides in Iowa with his wife and children. Having worked various jobs in engineering-related fields, he has since "retired" from corporate life to start his second career. Currently he works as a freelance writer, graphics artist, and coder over the Internet. He describes this work as, "I sit at home and type, and checks mysteriously arrive in the mail."
He discovered Linux in 1998 - his first distro was Red Hat 5.0 - and has had very little time for other operating systems since. Starting out with his freelance business, he toyed with other blogs and websites until finally getting his own domain penguinpetes.com started in March of 2006, with a blog whose first post stated his motto: "If it isn't fun for me to write, it won't be fun to read."
The webcomic Doomed to Obscurity was launched New Year's Day, 2009, as a "New Year's surprise". He has since rigorously stuck to a posting schedule of "every odd-numbered calendar day", which allows him to keep a steady pace without tiring. The tagline for the webcomic states that it "gives the geek culture just what it deserves." But is it skewering everybody but the geek culture, or lampooning geek culture itself, or doing both by turns?
The Ecol comic strip is written for escomposlinux.org (ECOL), the web site that supports es.comp.os.linux, the Spanish USENET newsgroup for Linux. The strips are drawn in Spanish and then translated to English by the author.
These images are scaled down to minimize horizontal scrolling.
All Ecol cartoons are at tira.escomposlinux.org (Spanish), comic.escomposlinux.org (English) and http://tira.puntbarra.com/ (Catalan). The Catalan version is translated by the people who run the site; only a few episodes are currently available. These cartoons are copyright Javier Malonda. They may be copied,
linked or distributed by any means. However, you may not distribute
modifications. If you link to a cartoon, please notify Javier, who would appreciate
hearing from you.
| Share |
|
Talkback: Discuss this article with The Answer Gang
More XKCD cartoons can be found here.
| '; digg_topic = 'linux_unix'; | Share |
|
Talkback: Discuss this article with The Answer Gang
I'm just this guy, you know? I'm a CNU graduate with a degree in physics. Before starting xkcd, I worked on robots at NASA's Langley Research Center in Virginia. As of June 2007 I live in Massachusetts. In my spare time I climb things, open strange doors, and go to goth clubs dressed as a frat guy so I can stand around and look terribly uncomfortable. At frat parties I do the same thing, but the other way around.
By Ben Okopnik
More faux-Linux images from the streets, with some new ones from our contributors. Thanks, folks - and please keep them coming!

"We've discovered the secret GNU kernel-writing labs, but their latest
project just makes no sense at all..."

(Sent in by Triyan Nugroho)
I thought my OS was secure, but now it seems that Linux crackers are
everywhere.

You simply won't believe what MySQL can store in a BLOB these
days!
| Share |
|
Talkback: Discuss this article with The Answer Gang
Ben is the Editor-in-Chief for Linux Gazette and a member of The Answer Gang.
Ben was born in Moscow, Russia in 1962. He became interested in electricity at the tender age of six, promptly demonstrated it by sticking a fork into a socket and starting a fire, and has been falling down technological mineshafts ever since. He has been working with computers since the Elder Days, when they had to be built by soldering parts onto printed circuit boards and programs had to fit into 4k of memory (the recurring nightmares have almost faded, actually.)
His subsequent experiences include creating software in more than two dozen languages, network and database maintenance during the approach of a hurricane, writing articles for publications ranging from sailing magazines to technological journals, and teaching on a variety of topics ranging from Soviet weaponry and IBM hardware repair to Solaris and Linux administration, engineering, and programming. He also has the distinction of setting up the first Linux-based public access network in St. Georges, Bermuda as well as one of the first large-scale Linux-based mail servers in St. Thomas, USVI.
After a seven-year Atlantic/Caribbean cruise under sail and passages up and
down the East coast of the US, he is currently anchored in northern
Florida. His consulting business presents him with a variety of challenges,
and his second brain Palm Pilot is crammed full of alarms,
many of which contain exclamation points.
He has been working with Linux since 1997, and credits it with his complete loss of interest in waging nuclear warfare on parts of the Pacific Northwest.
Jimmy O'Regan [joregan at gmail.com]
http://www.news.com.au/technology/terry-[...]-meteorites/story-e6frfro0-1225926584339
'Pratchett, who has Alzheimer's disease, also said he had thrown in "several pieces of meteorites - thunderbolt iron, you see - highly magical, you've got to chuck that stuff in whether you believe in it or not".' ... 'He said: "It annoys me that knights aren't allowed to carry their swords. That would be knife crime."'
-- <Leftmost> jimregan, that's because deep inside you, you are evil. <Leftmost> Also not-so-deep inside you.
[ Thread continues here (2 messages/2.00kB) ]
Jim Jackson [jj at franjam.org.uk]
Dunno if people have seen this...
http://blog.linux-lancers.com/images/articles/2008/10/28/programmerhierarchy.jpg
I have no wish to start a programming langauages war[1], and only offer it
up as amusement
Jim
[1] but it really is remarkably accurate in all sorts of ways :-P
[ Thread continues here (2 messages/1.60kB) ]
Jimmy O'Regan [joregan at gmail.com]
On 18 August 2010 20:42, Ben Okopnik <ben at linuxgazette.net> wrote:
> JS without Ajax? Awesome. Next up: Assembler to DOS Batch File Language > converter. The conversion is 100% accurate, but the output feature is > still in development...
Not quite what you mentioned, but not a million miles away:
http://www.secretgeek.net/dod_intro.asp "DOS on DOPE is the modern MVC framework built on the awesome power of Batch scripts."
-- <Leftmost> jimregan, that's because deep inside you, you are evil. <Leftmost> Also not-so-deep inside you.
[ Thread continues here (2 messages/2.31kB) ]
Jimmy O'Regan [joregan at gmail.com]
Discussed here:
http://languagelog.ldc.upenn.edu/nll/?p=2673
("it's too bad that they didn't set the system up to match the actual
norms of English metered verse")
they mention this:
http://research.google.com/archive/papers/review_in_verse.html
a review in verse
-- <Leftmost> jimregan, that's because deep inside you, you are evil. <Leftmost> Also not-so-deep inside you.
| Share |
|




![[cartoon]](misc/ecol/tiraecol_en-388.png)
![[cartoon]](misc/ecol/tiraecol_en-381.png)
![[cartoon]](misc/ecol/tiraecol_en-387.png)
![[cartoon]](misc/xkcd/password_reuse.png "It'll be hilarious the first few times this happens.")
![[cartoon]](misc/xkcd/debian_main.png "dpkg: error processing package (--purge): subprocess pre-removal script returned error exit 163: OH_GOD_THEYRE_INSIDE_MY_CLOTHES")
{kind=link}
{kind=link}
{kind=link}