NASA is the National Aeronautics and Space
Administration for the United States government space program. The
shuttle liftoff picture and the Discovery landing picture are from NASA's
archives.
xplanet
follows the tradition of xearth but using real imagery. I've
prepared this picture using the following options:
I fetched the current cloudcover imagery per the instructions in
/usr/share/xplanet/images/README. I decided the night image was a
little too dark and made a softer one called night_mode which still shows some of
the landscape. Most people don't know that you can give it any background
you like instead of having it speckle the black background. Many people know
that you don't have to let it pick the origin point. I started with
-origin=moon which looks great but the moon wasn't visible from
Florida right then, so I had to move our point of view
I created a markerfile with only one entry in it, the latitude and
longitude for Kennedy Space
Center, where the current shuttle took off and
will land. There are a number of groups with
custom markerfiles for various purposes. If you're putting together your
own, you might take a look at Dave Pietromonaco's xearth
markers page since he has a Gazetteer of coordinates for many
locations.
May the shuttles enjoy many more successful flights.
Heather is Linux Gazette's Technical Editor and The Answer Gang's Editor
Gal.
Heather got started in computing before she quite got started learning
English. By 8 she was a happy programmer, by 15 the system administrator
for the home... Dad had finally broken down and gotten one of those personal
computers, only to find it needed regular care and feeding like any other
pet. Except it wasn't a Pet: it was one of those brands we find most
everywhere today...
Heather is a hardware agnostic, but has spent more hours as a tech in
Windows related tech support than most people have spent with their computers.
(Got the pin, got the Jacket, got about a zillion T-shirts.) When she
discovered Linux in 1993, it wasn't long before the home systems ran Linux
regardless of what was in use at work.
By 1995 she was training others in using Linux - and in charge of all the
"strange systems" at a (then) 90 million dollar company. Moving onwards, it's
safe to say, Linux has been an excellent companion and breadwinner... She
took over the HTML editing for "The Answer Guy" in issue 28, and has been
slowly improving the preprocessing scripts she uses ever since.
Fri Jul 22 11:43:02 2005
Bob van der Poel (bvdp at uniserve.com)
Answered By Lew Pitcher,
Ben Okopnik
I've recently gotten a digital camera (yes, I know I'm sort of late
coming into the digital revolution). This is a HP R607 and lets you add
audio tags to still images.
[Lew]
Kewl.
I would have thought that the audio would be a wav or mp3 file with the
same name as the image, but life is never easy. I can only assume that
the audio is embbedded into the jpg. I've checked, and the only files on
the camera (other than some short XML files) are the jpgs.
[Lew]
Yah. The JFIF format (that's the file format that "JPEG" pictures are stored
in) supports a bunch of metadata. Many (I'm tempted to say most) cameras
store a 'thumbnail' photo in the jpg along with the full photo. They also
store camera information (make, model) and photo metadata (date/time of
photo, focal of lens, exposure time, photographers comments, picture
orientation, and a whole lot more). It wouldn't surprise me if the HP camera
also stored an audio clip as metadata in the picture jpg.
[Ben]
When you say that you've checked, do you mean that you used something
like "camedia", or did you actually mount it as a storage device and
looked at the files on it? The former may only show the JPG files, while
the latter should show everything. My Olympus D-40, for example,
produces discrete files for audio, stills, and movies.
If you're actually looking at the files on the device, then I'd have to
agree with the previous post - it's stored as EXIF data.
Yes. It is definitely stored as EXIF data. Ran a jpg file into emacs and
had a look. There's a nice RIFF/WAV header block right in the file. Of
course, the picture files without audio don't have the header.
More reading leads me to think that some cameras use 2 files and others
embed the audio into the picture. Mine is that later
So, is there a way to play the audio in the pictures on Linux?
[Lew]
I'm not sure, but it's likely that the audio is stored in one of the EXIF
(JFIF metadata) tags. There are tools available that can extract EXIF tag
data, ranging from the digikam/gphoto2/libgphoto tools to standalone tools
like jhead. Perhaps one of these tools can extract out the audio, and you can
play it from there.
Yes, it helps. Problem is to find a tool to do the extraction. digikam,
etc (based on gphoto2) do NOT seem to support audio play/extraction.
[Ben]
'gphoto2' supports a '--get-audio-data' option. There are probably a
number of other programs; googling for "exif audio extract linux" comes
up with 40,500 hits.
I think from reading and a bit of testing that --get-audio-data just
copies .wav files if they are on the camera. I could be wrong, but I
could not get this program to extract data.
I did the google as well
I found 2 candidate programs:
dphotox - this appears to be a great program, but I can't access the
download site ftp://ftp.mostang.com/pub/dphotox I sent
David.Mosberger @acm.org a note, but no reply as of yet. This is being
distributed as a binary only ... something to do with non-disclosure
according to the web page (which is accessable
http://www.mostang.com/dphotox )
EXIFutilsLinux2.6.2.tgz is another package which works. Installed and
tried it. It is shareware and they want a bit of money to unlock all the
features.
Amazing, the files I did extract sounded not bad at all.
I can't imagine that getting the audio out is much more than trivial. I
just don't have time right now, but I did compare the extracted file to
the data in the camera file and it is identical. Just a matter of
figuring an offset and the size.
[Jimmy]
I shouldn't imagine it's even that difficult: the audio is stored as
an EXIF tag, so you really just need to extract the contents of a
specific tag. (Hint: with Perl, Image::EXIF and Data::Dumper are your
friends).
If you want to send along a sample file, I'd be happy to give it a
stab/eat my words
[Heather] dd has a very nice 'skip' option as well as 'count'. if your 'blocksize'
is set to 1 and you are otherwise able to calculate how long to make the
cut, you should be able to do something like substring extraction, on a
file basis.
If our gentle readers have more ideas, or someone would like to do an
article on really getting the most out of your camera under Linux, it'd
be just the kind of thing to make Linux just a little more fun
Problems with tcsh scripting
Mon Jun 27 01:39:00 2005
Aengus Walton (ventolin at gmail.com)
Answered By Ben Okopnik
I have a number of issues with tcsh (not my choice..) shell scripting
I need help with.
Basically I'm writing a shell script that automates a long setup
procedure. This top-level script is in bash, however the bulk of it is
comprised of commands that are fed to a program which is, in essence,
a tcsh shell. I've achieved this by using the << redirector. I need
help on two points:
1) Is there any way of suspending input redirection, taking input from
the keyboard, and then resuming input from the tcsh script?
[Ben]
There is, but it is Fraught With Large Problems. I'm not that familiar
with TCSH, but I've just had to do that in Perl - essentially, I was
writing a Perl version of 'more' and had to answer the question of 'how
do you take user input from STDIN when the stream being paged is STDIN?'
It requires duplicating the STDIN filehandle... but before you start
even trying to do it, let me point you to "CSH Programming Considered
Harmful" - Tom Christiansen's famous essay on Why You Shouldn't Do That.
If it's not your choice, then tell the people whose choice it is that
They Shouldn't Do That. The task is complex enough, and has enough
touchy problems of its own, that introducing CSH into the equation is
like the Roadrunner handing an anvil to the Coyote when he's already
standing on shaky ground over a cliff.
To give you some useful direction, however - the answer lies in using
'stty'.
2) There comes a point towards the end of the script when two shell
scripts are run simultaneously. These shell scripts open up individual
xterm windows to run inside. I'm wondering, is there anyway of having
the tcsh script monitor stdout of one xterm, and upon the output of a
certain piece of text, echoing a command into the stdin of the other
xterm?
[Ben]
Why not 'tee' the output of the script - one 'branch' into the xterm and
the other into a pipemill (or whatever you want to run 'grep' in)?
Any insight or knowledge on the matter would be very much appreciated.
I hope I have provided sufficient details.
[Ben]
You have - from my perspective, anyway.
If the gentle readers have more to say, please let Aengus know, and cc
The Answer Gang so we can comment on the results or see his answer in a
later issue. Artciles on working with shells beyond bash are always welcome.
-- Heather
But both sides of WSGI must be in the same process, for the simple reason
that the spec requires an open file object in the dictionary, and you
can't pickle a file object and transmit it to another process.
...............
Actually, the spec requires a file-like object, so an emulation like
StringIO is allowed. StringIO is pickleable:
>>> from StringIO import StringIO
>>> sio = StringIO("abc")
>>> p = pickle.dumps(sio)
>>> p
"(iStringIO\nStringIO\np0\n(dp1\nS'softspace'\np2\nI0\nsS'buflist'..."
>>> sio.read()
'abc'
>>> sio.read()
" # End of file.
>>> sio2 = pickle.loads(p)
>>> sio2.read()
'abc'
cStringIO, however, is not pickleable.
>
He also requests that Ben slip an editor's note to this effect into
115's instance of the article. If your mirror doesn't contain a note
about it by next month... sorry, we can advise our mirrors when the
archives update, but it's their bandwidth.
-- Heather
This is regarding Hugo Mills query on how to build a Debian initrd
without devfs.
<flamebait>
Now why would you be wanting to build a Debian kernel without devfs.
Surely you haven't bought all that stuff by Greg K.-H. about devfs being bad design?
</flamebait>
[Rick]
Surely, it would be rude to speak ill of the dead. As we say in
Norwegian, "Aluv ha sholem."
I assume that you are planning to use Debian's kernel-package
(make-kpkg) utility to build the kernel. This you can do without
worrying about anything. Just build a kernel without devfs and other
options as you want them.
The initrd that is installed along with the kernel is built
(providing you specified that you wanted it to be built) at the time
when you install the kernel-image-x.x.x-y package.
This initrd is build by a set of tools called (what else)
initrd-tools; the principal among them being "mkinitrd". Now
"mkinitrd" takes a conf file /etc/mkinitrd/mkinitrd.conf so you can
make some changes there.
I haven't tried this but you would need to create a script in
/etc/mkinitrd/scripts that would setup the necessary device files in
the $INITRDDIR/dev.
More importantly, the script /usr/share/initrd-tools/init is the "init"
that is put on the initrd image. You would need to replace this with
your own version as the default one makes use of devfs.
If you are keen on sorting out all these issues you should probably
contact the maintainer of initrd-tools as Debian's initrd will have
to give up "devfs" at some stage since Linux 2.8 won't have "devfs".
Just a thought, but how about if he compiles a plain-jane Pentium I kernel?
It could be that the more recent kernels (and GCC?) might be putting in CPU
instructions that didn?t get called before, or they are called more often now
and are causing other errors. My experience is if the system is locked hard
like he implies, then it's probably a hung CPU not answering interrupts (as he
alluded to).
[Heather] Except for the part about how it answers them just fine under 2.4.x
kernels, this seems plausible. It'll be tried.
He might also try limiting his use
to the 768MB of RAM that his MB officially supports. Either by using
the kernel command line "mem=768M" or put in only 768MB of RAM.
As a side note, he might want to run "MEMTest86+"
(http://www.memtest.org/) and see if that sees any RAM errors.
There just might be a reason the MB manufacturer didn't recommend >768MB RAM.
[Heather] The full gig worked under 2.4.x kernels however some time has passed.
So, this is a very worthy suggestion. Also a current 2.4.x kernel will be tried, if the hardware is failing in this sense that might be affected too. Note to readers: the good folk at
MEMTEST
do occasionally update their test suite. Looks like the last update was in 2004 sometime - but some of the rescue disks might have an older edition in them.
If you load the soundfonts and play a midi, you may have
to download the soundfonts from the SBLive card prior to
playing a wav file. The soundfonts do not stay loaded
very long, so you have to check the available SBLive memory
prior to playing a midi.
A tickler about last month's issue taking so long to publish...
-- Heather
Any news on the when the latest Gazette is out? Or have I missed the
announcement... Being subscribed on both of my accounts to the
announcement list...
[Ben]
I figured we'd get mail from our readers about now.
The new issue
should be out tonight, Martin; the problem was that - this being summer
- many of our authors are on vacation, and we were a bit thin on
articles. Several of the folks in The Answer Gang had, very capably,
scrambled their jets and kicked in a bunch of material, and I've been
working to get it all organized. Blame the delay on me.
For all our readers, if you've ever wanted to try your hand at writing -
we're always looking for new authors. In the worst case, if your
submission gets rejected - and this is part of my commitment to LG -
you'll get a note explaining exactly why it was rejected, along with
suggestions on how to improve your writing. That is, at the very least,
you'll get to learn something useful - and you may well end up getting
published, which is not a bad thing to have on your resume.
So don't
be shy, folks - read our
Authors' FAQ
and send'em in!
It is our preference to ship an issue somewhere around the first of the month. Our lives including work in the weekdays have led the last several issues to come out somewhere around the weekend that's nearest; with the articles that came in late, we ran a bit overtime even by that standard. Sorry. But I also encourage people with good articles that they feel need some work, to contact us and get into the sequence. You needn't always publish in the same month - we won't write your article for you, but our Articles@ staff may be able to point out some directions for improvement, and we get a new author out of the deal, too. So everyone wins
-- Heather
I know that Thomas, at least, is away from the City, but - just for my
own peace of mind - are all the Answer Gangsters from England OK? That
would be Mike Martin and Neil Youngman that I recall; if anyone else can
think of others, I'd appreciate it if you could ping them and CC the
list.
[Thomas]
Aww, thanks, Ben. Actually, I was only 33 miles from London at the
time. I was in Stevenage, a town around London visiting my
Grandparents. Would you believe they have broadband? Heh. More
modern than my parents.
But I'm well, and accounted for.
And I'm very glad to hear it!
[Thomas]
I just hope Neil is, although as
I know Neil is around the Pin-Green area (where my grandparents are), I
would surmise he too is just as well.
Yes indeed; he's emailed me (and as I recall, cc'd the Gang on it.) I
haven't heard back from Mike yet, though - it's a bit worrying. Since
you live in the same small island, could you perhaps walk over and knock
on his door?
[Neil]
Ben your concern is appreciated. I was working from home that day, fortunately
miles away from all the incidents. My wife was working in London as usual,
and the first bomb was on her route in. Luckily she was already at work when
it went off. Although she had a very unpleasant journey home, we are lucky it
was no worse than an inconvenience for us. With 49 confirmed dead and more
than 25 missing, our thoughts are with their families.
[Thomas]
Small? Hehehe, Ben, sail your boat round these waters, I'll show you
around this place.
[Jimmy] There was a lot of off-topic chat in here too:
enjoy the Launderette
if you're interested
This page edited and maintained by the Editors of Linux Gazette HTML script maintained by Heather Stern of Starshine Technical Services, http://www.starshine.org/
The Answer Gang
Linux Gazette 117: The Answer Gang (TWDT)The Answer Gang 117:
...making Linux just a little more fun!
The Answer Gang By Jim Dennis, Jason Creighton, Chris G, Karl-Heinz, and...
(meet the Gang) ...
the Editors of Linux Gazette...
and
You!
We have guidelines for asking and answering questions. Linux questions only, please.
We make no guarantees about answers, but you can be anonymous on request. See also: The Answer Gang's
Knowledge Base
and the LGSearch Engine
Hello everyone -- welcome, once again, to the world of The Answer Gang.
There's a world of people out here doing good things. As my
cover art raises a cheery note to those who are part of the space programs (not just for the USA program, though certainly since that's where I live that's the pics I'm looking at) - there's those of us who not only hope for a brighter future but make it so, by our heartfelt efforts and getting our hands deep in code and craft.
As good fortune would have it, I'll get to meet a larger batch of them at this year's LinuxPicnic than last. And I can reasonably hope I'll see a decent batch of you folks at
Linux World Expo in my area too.
Why is this important, you might ask. It's the Internet Age; people live on their cellphones, podcast LUG radio reports at each other, spend more time in IRC than visiting their aunts and uncles, mail order things via PayPal or other money-kindred and about a billion online stores. Who notices that real world thingy? The wattage in the Blue Room is up way too high, too. But that's just it -- it may be a big blue room... but it's the same world we all live in... and we've all got a much finer chance of doing our best if we learn to share the bright marble Nature has granted us.
Hooray for open source. Have a great Summer, folks. See you next month.
Network File Systems.
From mso@oz.net
Answered By: Rick Moen,
Lew Pitcher,
Jimmy O'Regan,
Bruce Ferrell,
Neil Youngman
What other choice is there besides Samba? Am I wrong for dismissing Samba
due to its Microsoft taint?
(I do have to use Samba at work. So far it's been fine except I had to
use the "cifs" filesystem instead of "smbfs". Apparently our server
pretends to speak the older smbfs but actually doesn't.)
[Rick]
Well, if you need help disposing of those troublesome spare CPU cycles,
there's always SFS (http://www.fs.net).
Personally, my preferred solution is called SMTP, aka "Please drop the
mail off right here where I am, thanks" -- for values of "where I am"
equating to "the machine I ssh to, where mutt is left running
permanently under GNU screen ".
Tridge's reported solution is to use rsync (what else?) to mirror his
mbox between his SMTP host and whatever machine he's sitting at.
OK. I meant for the general problem of mounting remote filesystems, not
the specific problem of remote mailboxes.
[Rick]
I have nothing against you changing the focus of the discussion in that
fashion; I just note that you've done so. Enjoy.
For that there's only NFS and
Samba? (rsync, scp, and ftp don't count
It looks like SFS on Linux is built on top of NFS, so I'm not sure it
counts as a "third" one.
http://www.fs.net/sfswww/linux
The reason for my question is, there doesn't seem to be a "good" solution
for sharing filesystems on Linux. For years I keep hearing:
NFS: Unreliable! Doesn't play well with file locking!
Samba: Evil! Microsoft! Proprietary protocol! Embrace and extend!
So what's the organization that wants a central fileserver to do?
[Rick]
Take your pick:
AFS, or
It depends.
Did
Microsoft in fact create something better than NFS (better = more reliable
and better designed), or is it just different?
[Rick]
They're different. It would take a long time to go through the
differences, and I'll leave that to some other poster.
[Lew]
I won't comment on "better than NFS or just different", but I will take
exception to the implication that Microsoft created the protocol.
[Rick]
I also recommend hearing hearing Jeremy Alison give his standard
lecture, if people want to hear the full details of just how bad
CIFS/SMB really is.
[Lew]
I will give Microsoft credit for extending an already existing protocol, but
the basics come from IBM's NETBIOS.
[Jimmy]
Well, there are actually three different fileserving systems in the
heap that is MS fileserving: NetBIOS, CIFS, and DCE DFS. CIFS may or
may not depend on one or both of the others.
MS's file serving is much, much better for file locking (but you only
get the benefits of that from software that uses MS's locking API).
It's also better to use Samba in an environment where there are
several Unix variants, and you care about ACLs -- the Samba team
'embraced and extended'[1] CIFS to add marshalling for the various ACL
types, which NFS doesn't do. (Well, NFS4 might do, I don't know).
[1] They just like saying that, as far as I can make out. AFAICT, they
just added an extension that plays well with others, and looks like
any other unknown DCOM interface to clients that don't look for it --
it doesn't get drunk at the party and throw up on the other guests.
[Bruce]
Umm Jimmy, aren't NetBIOS/NetBEUI simply transport protocols? I think
it might be more appropriate to say SMB and DCE DFS. And DCE DFS is
actually built on top of SMB, but I could be wrong there. I just set
these things up. I'm too busy to look at the messages anymore. And I
think you neglected NCPFS... Not that anyone does much with Novell
protocols anymore.
[Jimmy]
...cue brain dump.
This may not be entirely accurate, because: it's 6am, and though I was
working nights last night, I didn't sleep much during the day in the
hopes of readjusting to normal hours, and this is stuff I mostly
learned back in the days of NT4, when I was in college, and went a bit
further than strictly necessary in my studies for the MCSE exams I was
never able to afford to take, though fortified with some
investigations last year when Mike was asking about smbfs vs cifs. The
article I wrote about outliners came the month after that, and AFAIR I
included an example outliner file that contained some specifics, such
as RFC numbers etc.
NetBIOS is an API (originally, IIRC, a set of DOS interrupts)
SMB is the part most people think of when they think of NetBIOS, but
it actually uses a transport protocol such as NBT (NetBIOS over
TCP/IP), NetBEUI, or NetBIOS over SPX.
SMB, NetBIOS, and possibly NBT were created by IBM
Microsoft extended these, originally while working with IBM on OS/2
for LanManager (y'know, the easily crackable password hashes that made
NT's network authentication so horribly insecure)
CIFS is a version of SMB that doesn't require NBT -- that's why
smbfs and cifs are separate kernel modules -- that also includes
extensions for NTFS's features such as multiple file streams[1]
DCE DFS is something like NFS, over DCE RPC instead of Sun RPC
Microsoft uses an extended version of DCE RPC, Object RPC, as the
basis for DCOM. COM interfaces are implemented locally using C++
vtables, which are marshalled over ORPC, which in turn is passed over
NT's (network) Named Pipes: (extended) DCE RPC over SMB/CIFS.
I didn't mention ncpfs because I was answering the second question
(NFS vs. Samba), not the first (any network file system).
[1] This is one of the places where NT shows its VMS heritage, as all
file streams are preceded by ::$, such as ::$DATA, where the data is
contained. (If that seems familiar, it may be because of the IIS flaw
where it would send you the unprocessed source of ASP files if you
appended ::$DATA to the file name).
(Scratches head.) There are still OS/2 users out there? And they are
more technical than Windows or Mac users who are scared of Linux?
[Neil]
Heck, there are still VMS users out there, there are probably still RSX users
out there. Generally these are people who have specific requirements, e.g.
real time, stability, security, that have had the sense not to jump on the
Windows bandwagon, because it doesn't meet their requirements.
So yes, I reckon OS/2 users are generally more technical than "Mac and Windows
users who are scared of linux". They may migrate to Linux, but they will do
it when they are convinced it meets their requirements better than the
alternatives and when it suits them, not a minute before.
[Lew]
You bet. OS/2 is/was heavily used in the banking industry as 'Teller' terminal
systems and as operator control systems/interface systems to IBM mainframes.
My employer (a Canadian bank) has a multi-year project currently running to
migrate our approx 15,000 OS/2 branch workstations and branch servers to
another OS. Linux was considered, but in the end, my employer went with
WinXP.
Our OS/2 users are no more technical than the cashier in your local grocery
store. Our OS/2 applications are quite sophisticated.
Making SSH a supported protocol
From Mark Jacobs
Answered By: Ben Okopnik,
Jimmy O'Regan
Gang,
I manage a web server that is used by an internal help desk,
currently this help desk uses telnet to access aix servers on our
corporate wan. I have multiple pages that serve URL's to the aix
machines e.g. telnet://hostname <telnet://hostname/> . We are in the
process of changing all of these servers to use SSH and need to know how
to make ssh://hostname a registered protocol so that I can convert my
links and have them work. I am unable to find any information on
where/how you set up a protocol and associate it with an application.
Is this a system or browser issue? Any information you might have or be
able to point me to would be a big help.
[Ben]
In the future, please send your questions in plain text; that's the
accepted format for The Answer Gang. The instructions for setting your
mail client to do this, as well as much other relevant information, can
be found in the "Asking Questions of The Answer Gang" FAQ at
http://linuxgazette.net/tag/ask-the-gang.html
Regarding your question, there's no "registration" that you can do to
make SSH magically happen from the server side: URLs are parsed on the
client end, by the specific browser that's being used.
Note that some browsers - e.g., Konqueror - do parse 'ssh://' URIs; they
fire up a console with a login prompt (which is, of course, the correct
response - SSH is a secure SHELL protocol.) Konqueror also supports
the 'fish://' protocol - an SSH-based connection that allows file
viewing and could be a bit closer to what you want... or maybe not.
The problem is that most other browsers do not support these schemes -
and many cannot even be adapted to do so. There's a huge number of
browsers operating on a number of OSes, and unless your company has some
sort of a draconian software policy, you have no way to restrict them or
control which ones people use.
The obvious solution here, in my opinion, is to run a web server, and
place your documents on it. Telnet should go away - sending passwords
across the network in plain text and IP-based authentication are not
sensible things to do in today's world. Running a web server,
particularly a simple, read-only one like "thttpd", is a trivial task
requiring either no or only a few seconds of configuration, and the
replacement of telnet by SSH and HTTP should significantly decrease your
vulnerability profile.
Wow. I've got to say that I'm just stunned by the moronic thing that
Mutt just did. It's probably the stupidest thing I've ever seen from
any Linux app - it rivals 0utlook and IE for complete slack-jawed
idiocy.
Once in a while, I get false positives in my spambox. Today, I got one
from somebody posting to TAG (I don't recall the name - somebody who had
sent it to the wrong address and then bounced the DSN + original mail to
TAG), so I saved it to my main mailbox by hitting 'v' (view), selecting
the "pre-Spamassassin message", hitting 's' (save), and choosing
"/var/mail/ben". When I opened the message, I decided to repeat the
operation (i.e., get rid of the "wrapper" message) - so I again hit 'v',
selected the original message, and hit 's'. Mutt then popped up a
message that said something like "file exists - are you sure?" - and
since I had done the same operation dozens of times before, I hit 'y'
for 'yes'... at which point, my mailbox got wiped. Zeroed. Nothing left
of the 20 or so messages I was going to answer, not even the message
that I had theoretically saved. (Mike, your Python article was part of
that - so if you could resend, I'd appreciate it.)
I'm in a bit of shock here, and rather pissed off. In all the years I've
used Mutt, I never realized that this essentially random bomb was hidden
in it - and triggered off by a message that seemed to make sense in the
context.
Dammit. Double dammit, since I use my mbox as a sort of a backup "to do"
list - I leave emails that call for some kind of action in it until I've
completed that action. Grrrrr.
[Kapil]
Commiserations for your loss.
Thanks. As best as I can recall, there was nothing really critical or
earth-shakingly important in there, but important enough for the loss to
create a high annoyance factor. Semi-amusingly, two of the messages got
"saved" by my despamming mechanism: they had been sent to me by a reader
who dressed them in spam-like clothing (all-HTML content, funky mail
hosts, etc.), and when I forwarded them to TAG - they were in regard to
Heather's query in the Mailbag - they got spam-slammed again. So,
between a little info message that Kat sent me, Mike's article, and the
two not-spams, I've got four messages back.
[Kapil]
You could try ext2 recover mechanisms. They might work.
I hadn't thought of that at the time, and given that the same file had
new mail in it just a few seconds later, and a very large email in it
yesterday evening, I'm pretty sure that there's nothing left.
[Kapil]
At one time I had a similar ToDo list at the top of my mbox and my
mailer (vm/emacs) of the time did something similar to what mutt just
did to you. I was able to recover my ToDo list (though not the
more recent stuff in my mbox).
Partly as a result of the above catastrophe, I moved away
from vm/emacs but (I think) more importantly, moved away from the mbox
format. I am currently an advocate of the MH or maildir formats for
personal folders. One mail---one file. Almost no screw-ups by a mail
user agent can screw up all my mail again.
[Heather]
Unless it screws up the directory. Also mdir index mechanisms can get
mangled; though it seems to take more work, it's much wonkier when it does.
I've thought about that in the past. My hindbrain had made some
disquieting noises about not being able to search the archive quite as
effectively - which does not appear to stand up to rational analysis
when considered soberly - and so I'd left it alone.
Hmm, perhaps this is becoming a Gang-relevant question. Folks, what do
you think of the pros and the cons of MH vs. Mbox? The net provides much
in a way of "yea" and "nay" answers, with only esoterica for support
(speed of opening 2,000 messages - wow, very important criterion to
me...), and I'd like to hear if anyone has had other positive or
negative experiences with either format.
[Rick]
(Note: I've studied the pros and cons of Maildir a bit; MH much less
so. To a first approximation, I'll assume they're similar.)
1. People with their mailboxes on Nightmare File System need to migrate
to Maildir or MH format with all reasonable speed, because of the
greatly increased chance of lossage.
Despite Sun's love affair with NFS and their subsequent attempts to
smear it on sandwiches, mix it into house paint as a mold retardant, and
use it for greasing subway trains, I avoid it like the plague.
[Rick]
2. Otherwise, the advantages of Maildir/MH format strike me as somewhat
but certainly not overwhelmingly compelling. I vaguely recall that the
mutt MUA has an (optional) indexing feature that reduces the performance
hit of Maildir. People who've migrated to that seem happy with it.
I still keep absolutely everything in mbox files, anyway, because I'm
lazy and set in my ways, because I've not yet been bitten by a glitch
the way you were, and because something about huge trees of little files
just doesn't seem right.
We seem to share a similar set of prejudices, Rick. "Lazy, set in my
ways, trees of little files vaguely wrong" - yep, that's me to a tee. So
far, I haven't heard any compelling arguments for switching - I was
hoping that somebody had one...
[Kapil]
Having already called myself an advocate for MH/maildir let me point
out one disadvantage of MH/maildir on a multi-user system where you do
not have control over disk quotas. Both MH/maildir could cause you to
run over file (not space) quota. This could also be a problem over NFS
(too many NFS file handles ... ).
Y'know, I really enjoy this kind of thing. When I ask this kind of
questions, people's answers tend to trigger off the "oh, yeah... I
remember reading/hearing/seeing that!" 8 times out of 10. It calls up a
strong echo of Brunner's "Shockwave Rider": "We should not be crippled
by the knowledge that no one of us can know what all of us together
know."
Thanks for the reminder, Kapil!
[Kapil]
I have not noticed speed issues. I know "mutt" is a four-letter word
in Ben's book right now, but it can employ "header caching" so that
MH/maildir folders can be scanned quickly. This also mitigates the
NFS problem somewhat. Other mailers may do the same.
Mutt did this one stupid thing in all the time that I've used it - under
a defined set of circumstances. I now know enough to avoid those exact
circumstances; the only thing that's left is a question of "do I trust
Mutt not to present me with other equally boneheaded non-choices?"
Well... there are no guarantees, but I believe that Mutt was written
with the best of intentions (as well as being subject to the Open Source
debugging mechanism), so, yeah, I'm willing to trust it. Conditionally.
[Kapil]
Between MH/maildir, the former should be avoided if there is some
possibility that the folder could be accessed by two programs at the
same time.
To Ben's question I would add the following compatability related
question. "Do most mail-related utilities handle MH/maildir
nowadays?"
[Nod] I'm very much a CLI user by preference. Looking at the list of
Maildir clients, it seems that most of them are GUIs - which mitigates
against my adopting it. Although there certainly are CLI clients, they -
other than Mutt - are not very common. Given that I log into a variety
of systems to read my mail, often over low-bandwidth links, this
definitely reduces my options.
[Rick]
(Again, I don't know much about MH-format support.)
I have information on various Linux MDAs (mail delivery agents) and LDAs
(local delivery agents), here, including which mail-store formats they
support, where known:
[Sluggo]
Actually, speed of opening mailboxes is important to me. I switched from
mbox to MH format years ago because it's "safer" and more "ideologically
correct" (notwithstanding Rick's comment to the contrary; I just prefer
not stuffing multiple things into one file with a program-specific
"separator".) But then I switched back so I could get the "You have new
mail" messages from zsh.
I think that this has been one of my dimly-sensed, not-fully-formed
objections to Maildir/MH - a feeling that it's not quite as well
supported/debugged as mbox. I don't have much of a problem with the idea
of a defined separator in the file; the only time I've seen it screw up
was when my mail server went bonkers and delivered me a box of messages
where the 1st message was headless (the clue came when I looked at one
of the old emails in the box - the original content had been extended
by something totally unrelated!)
[Sluggo]
That seems to work only with file mailboxes, not
directory mailboxes. I was concerned about losing mail, then thought,
"How often has mbox ever trashed my messages anyway?" I can't think of a
single instance where new messages stomped on existing messages. Mutt
does do sometimes display an mbox message as two messages, split
arbitrarily in the middle, with empty headers for the second (and thus a
date like Jan 1980), but that was never critical. NB. I don't use NFS,
especially not for mail spool directories.
It sounds to me like an upstream mail server that fails to use the "From
hack". The last time I recall that happening was in an email from a
listserv server - about ten years ago.
[Sluggo]
But with my current computer I keep my mail on my ISP's mailserver and use
IMAP. I'm less concerned about ISP snooping or the mailserver going down
than about my own computer going down after it has downloaded mail, or my
Internet connection randomly freezing for several hours when I was away
from home and had to look up a phone number in an email. But I found
mutt's IMAP user interface sucks ass: you can't set an IMAP address as
your primary inbox, apparently, meaning you have to type this verbose
syntax to access it each time you start mutt. I looked at other mail
clients. Kmail kept showing a long-outdated configuration I couldn't
override so that alarmed me. I settled on Thunderbird, although it
sometimes gets its index pointers out of alignment and won't let me access
a new message, so I have to restart it. Someday I'll look over the other
clients available. I definitely want a client that can read mail in place
in standard formats, rather than one that wants to slurp it up into its
own format (and deny access to other mail programs). I think both
Thunderbird and Kmail want to slurp up local mailboxes.
[Kapil]
This has to be an old version of "mutt". The newer one seems to allow
set spoolfile = imaps://luser@ghost/INBOX
Of course, "mutt" is not particularly good with IMAP. So my current
config is based on "offlineimap" which copies all the mail from the
server into a local maildir. It also syncs whatever changes I make
to the folder back onto the server; in this it improves on "fetchmail"
which is one-way.
Of course, this setup means one uses more bandwidth than is strictly
necessary just to read those mails that one is interested in. I have so
far not suffered any glitches in this setup (but I'm waiting ...).
[Heather]
My positive experiences with mdir are about arrival speed on a heavily loaded
server. Also, among the IMAP implementations, Courier was about 10x or 11x
as fast as wu-imap, which was fragile, and Cyrus was only about 3x. Courier
backends with maildirs, though I'm not sure that's where all of its benefit
comes from.
The notes and specs rant about mdir being safer but a lock is a lock.
They're probably right since I have seen mbox files get bad hiccups from
intermingling messages when locks fail. On the other hand individual mails
in mdir use up whatever storage unit is going around. Maybe on reiser
(where tails that are tiny are often crammed into one stroage unit) this is
less of a pain.
[Kapil]
> I know that this is a bit like asking you to lock the stable door
> after the horse has bolted it, so commiserations once again.
^^
[ puzzled ] If the horse has already bolted it - very smart horse, that
- why would I bother locking it? Or is this a multiple-level security
implementation?
[Kapil]
Thanks to one V. Balaji (Tall-balaji) for this excellent improvement
of a classical proverb. I have used this version ever since I learnt it
from him.
[Heather]
Not only that but after pulling this prank, the horse ran away really fast
Transcoding UTF to ISO8859-1
From Riza Aziz
Answered By: Jimmy O'Regan,
Ben Okopnik
Dear Answer Gang,
I am having some problems with reading converted
UTF8-encoded web pages on my Palm PDA. I can't figure out
how to transcode UTF, which the Palm doesn't understand,
into ISO8859-1, which the Palm displays properly.
Some background: I have a script that downloads the latest
news from a few sites. It's an ugly RSS look-a-like for
sites that don't support RSS. I then use "htmlconv", a Perl
script from the txt2pdbdoc package, to convert the
downloaded pages into a text-only format which I can then
upload to the Palm. The script also converts character
entity references (egrave, quot etc.) into ISO8859-1
characters. On the Palm, I use Cspotrun to read the PDB
files.
I downloaded the txt2pdbdoc package a long time ago and it
worked fine with Redhat 6. When I upgraded to Redhat 9,
Perl's UTF handling broke the script because it assumed I
wanted the converted web page in UTF. This poses a problem
because the Palm doesn't understand UTF characters;
accented letters and certain punctuation marks become
strange symbols. By adding
use encoding 'latin1';
use open ':encoding(iso-8859-1)';
everything worked again.
Now, I've come across a website
(http://www.zmag.org/recent_featured__links.cfm) that uses
UTF directly. Instead of using "egrave" for an accented E,
it uses the UTF character directly. The converter script
doesn't know what to do with the character and I get all
sorts of strange symbols when viewing the file on my Palm.
Is there any way to convert the UTF characters directly
into ISO8859-1? And how do I get rid of any characters that
don't map directly, so strange symbols don't show up on my
Palm? I've messed around with the encoding pragmas but I
can't get anything to work.
Thanks!
[Jimmy]
Righto. I have a silly perl script that prints out the Polish alphabet
(so I don't have to trawl through the iso-8859-2 man page for the long
names of the odd characters) that looks like this:
To get rid of the extra characters, you'd probably be better off
converting to ASCII rather than ISO-8859-1 -- Perl will print a question
mark instead. (recode will too, if you use the -f option, to force an
irreversable change. Otherwise, it'll stop as soon as it finds a
character that it can't convert).
I looked everywhere in my system and I can't find recode.
Does it belong to any particular package?
I did try
substituting all the UTF characters with their common ASCII
equivalents e.g. open & closing quotes with ". I created a
hash as above and used s/// but nothing happened.
One strange thing: the single closing quote character under
UTF is \x{2019}, which I tried substituting for. However,
running hexdump on the file shows the character is actually
E28099... what gives? What can I do to get a straight ASCII
dump of the file?
The xxx bit positions are filled with the bits of the character code
number in binary representation. The rightmost x bit is the
least-significant bit. Only the shortest possible multibyte sequence
which can represent the code number of the character can be used. Note
that in multibyte sequences, the number of leading 1 bits in the first
byte is identical to the number of bytes in the entire sequence.
Examples: The Unicode character U+00A9 = 1010 1001 (copyright sign) is
encoded in UTF-8 as
11000010 10101001 = 0xC2 0xA9
and character U+2260 = 0010 0010 0110 0000 (not equal to) is encoded as:
11100010 10001001 10100000 = 0xE2 0x89 0xA0
...............
If you want to look at the raw text, just use a text editor that isn't
unicode aware.
[Jimmy]
One thing to be aware of when dealing with files created on Windows (as
the page you pointed to was) is that Windows usually uses UTF-16LE
rather than UTF-8.
Yeah, created with MS Frontpage. Blech
All this time I
thought that ISO8859-1 was the standard encoding for web
pages, with other encodings used for Chinese, Japanese
script etc. Is mixing and matching allowed?
[Jimmy]
I don't know, to be honest. I'd assume that if you want to do that,
you'd be strongly encouraged to use Unicode. (Umm... actually, these
days, you're encouraged to use XHTML rather than HTML. Since XHTML is
based on XML, it's UTF-8 unless stated otherwise).
Thanks for the link to an excellent website on most things
Unicode. It cleared my misconception that Unicode sequences
correspond to actual byte sequences, when they don't e.g.
\x{2019} is actually E28099, not 2019.
[Jimmy]
Erm... be careful with your phrasing there. The part that's written to
disk is an encoded version of the Unicode sequence. UTF-7 is a good
example of how it works: IIRC, it's UTF-8 encoded with Base64.
I think I have the
problem mostly solved. I added the following pragmas:
use encoding 'utf8';
open( OUTPUT, '>:encoding(iso-8859-1)', "$txt_file"
)
So, the script processes everything in Unicode but spits
out the results in ISO-8859-1.
The hard bit for me is the substitution. The following
snippet is supposed to do the substitution, but it doesn't
work:
Instead, I get an error for each non-matching Unicode
character:
"\x{2019}" does not map to iso-8859-1 at
/home/riza/bin/htmlconv-utf line 302
However, using s/\x{2019}/"'"/eg, s/\x{201c}/"'"/eg and so
on for every non-matching character works. It's a really
clunky way of doing things but the resulting file displays
perfectly on the Palm. How do I match hex sequences for
non-matching Unicode characters in a regex, without wiping
out all other characters?
The regex still isn't working though. Let's break it down:
s/(\X+);/
I'll assume the semi-colon was a typo. I think the pattern should really
be (\X) though; you're using it to match individual characters against a
hash, so you don't want to get more than one character. If you want to
see what you're matching, you could use something like this:
s/(\X)(?{print "Matched: $^N\n"})/
and shouldn't it be $utf_entity{"$1"} instead of $utf_entity{$1} ?
But do you really need to do that stuff with the hash when you could use
tr instead?
tr [\x{2019}\x{201c}\x{201d}] ["];
Jimmy O'Regan wrote:
> and shouldn't it be $utf_entity{"$1"} instead of $utf_entity{$1} ?
I think the problem was with the encoding of the file
handle and a bit with the regex itself. Below are snippets
of my version of the converter script. However, I'm
following the original author's method of slurping up all
the input and putting it into $_, whereas your script loops
through the input. Which method is better?
[Jimmy]
How long is a piece of string?
(No, really - if you know your file
will fit into memory, your way is better, otherwise my way is better (I
think
).
[Ben]
That being the big caveat - although HTML files are not likely to be so
huge that they'd cause an OOM on a modern machine.
open( INPUT, '<:encoding(utf8)', "$html_file" ) or die
"$me: can not open $html_file for input\n";
$_ = join( ", <INPUT> ); # slurp up all of HTML
[Ben]
This is not a good idea. You're reading in <INPUT> as a list (which
takes ~5x the memory for the amount of data), then "join"ing the list -
seems rather wasteful, particularly since you don't need to do any of
the above (entities are not going to be broken across lines.) For future
reference, try this:
open Fh, "foo" or die "foo: $!\n";
{
local $/; # Undef the EOL character
$in = <Fh>; # Slurp the content in scalar context
}
close Fh;
close( INPUT );
if ( $txt_file ) {
open( OUTPUT, '>:encoding(iso-8859-1)', "$txt_file" ) or
die "$me: can not open $txt_file for output\n";
select OUTPUT;
}
### various HTML-stripping bits here
%utf_entity = (
"\x{2019}", "'",
"\x{201c}", '"',
"\x{201d}", '"',
"\x{2026}", "...",
"\x{fffd}", "",
);
s/(\X)/ exists $utf_entity{$1} ? $utf_entity{$1} : $1 /eg;
print "$_\n";
The above regex works. I found that I didn't have to use $_
= encode_utf8($_) to get it running, as long as the
non-matching UTF characters were stripped out before
output. If a character was left in, its Unicode sequence in
plain text was shown in the output file e.g. \x{fffd}.
[Jimmy]
It dawned on me this morning that I only needed to use the open() stuff
or the Encode stuff, but I'll just stare at the ground, shuffle my feet,
and mutter something about being doubly sure
That stuff was a
hangover from pasting a line in the wrong place, before I noticed you
were trying to match too much.
Use redirection to write your output to a file - or pipe it into
something else for further processing.
I think your way (of looping through the file) is actually
better for a large range of file sizes.
I usually "cat" a bunch of HTML files together before
converting them with the script. Using the slurp method, a
cobbled-together file of 1 mb or more pretty much kills the
computer
It just sits there, not processing but taking
up a lot of memory. After 10 minutes I have to kill the
process.
OTOH if you loop over the file, that would allow it to
better allocate memory, I guess?
[Ben]
Depends on your meaning of "loop over" - if you load the entire file
into memory and loop over it (as both slurping and the 'for' loop will),
then no. This is one of the things I constantly emphasize to my Perl
students: you can easily bring down your machine by slurping files - do
not do it unless you're very confident that the maximum file size will
be no more than a tiny fraction of the memory.
# Wrong ways for arbitrary file sizes, OK for small files:
### Slurp into array
@file = <Foo>;
### Load <Foo> into memory as an array
for $line ( <Foo> ){ do_stuff( $line ); }
### Load Foo into memory as a string
{ local $/; $file = <Foo>; }
# Right ways when in doubt:
### Read the filehandle one line at a time
while ( $line = <Foo> ){ do_stuff( $line ); }
### Read a paragraph at a time, in case there are continuation lines
### (e.g., mail headers)
{ local $/ = "\n\n"; while ( $line = <Foo> ){ do_stuff( $line ); }
Many thanks for the help! I'm attaching the whole script,
in case someone might have use for it.
[Ben]
Both Jimmy and I mentioned the reasons why slurping can be dangerous,
but there are times when you can't avoid it - although constructs like
this one tend to handle most of the "line-continuation" scenarios:
while ( $line = <Fh> ){
while ( test_for_incomplete_line( $line ) ){
$line .= <Fh>;
}
# Process $line further
...
}
In other words, if there's some metric you can use for distinguishing an
incomplete line, then you don't need to slurp. Conversely, if you're
looking at formatted text, you can also avoid slurping by processing a
paragraph at a time:
$File = "/foo/bar/gribble.qux";
open File or die "$File: $!\n";
{
local $/ = "\n\n"; # Define EOL
while ( <File> ){
process_content();
}
}
Asking which method is "better" makes no sense until you consider the
data that you're processing. In your case, since entities don't break
across lines, slurping is unnecessary - so processing it a line at a
time is quite sensible.
Thanks! I guess the script's original author wrote it only
to convert small, single HTML files instead of huge HTML
lumps of multiple files.
[Ben]
That would be my guess. Either that, or he didn't even consider the
issue. Either way, handling the problem in the script would have been
trivial:
# After processing all the command-line options, loop over files
for ( @ARGV ){
if ( -s > $MAX_SIZE ){
warn "File $_ rejected: TOO LARGE!\n";
next;
}
process_files( $_ );
}
Just curious, what kind of data would have entities spread
across multiple lines ie. binary data? Even plain text
would be terminated with CR or CR/LF, correct?
[Ben]
Well, what makes them entities is that they're atomic - i.e.,
irreducible units. That means that they _can't_ be broken, across lines
or in any other way - otherwise they become, erm. non-entities.
[Jimmy]
Erm... not quite. Let me veer off-topic a little...
In SGML and XML you can define your own entities, which can contain
pretty much anything you want -- a multi-line disclaimer, for instance.
Since the trend in browsers has moved towards generic XML browsers that
render using CSS or XSL stylesheets (but with a fallback mode to handle
the mangled mess that is HTML), defining your own entities is possible,
though not advisable.
You can define binary data as an entity, but anything other than plain
text will at best be ignored, at worst cause an error. If you want to
output a CR, for example, you would have to use XSL-FO (though there is
a way to preserve whitespace from XSL, including CR or CR/LF, you just
can't do it as flexibly as plain text).
(Defining your own tags is OK, though - browsers ignore tags they don't
understand. Most HTML browsers can handle XHTML[1] because of this).
[1] That is, as long as the XHTML namespace isn't prefixed, and some
browsers have trouble with <br/>, <hr/>, etc. (Though they can manage
<br />, etc)
[Ben]
Jimmy, correct me if I'm wrong but - we were speaking of HTML
character entities, right? Otherwise, the methane-based entities from
the Dravidian cluster are going to complain about discrimination. If
we're going to bring in every other kind of entity and ignore them,
it'll look like solid grounds for a lawsuit.
To restate my point with a bit more precision, though: HTML character
entities cannot be broken - otherwise, they'll be, well, - broken.
[Jimmy]
Sorry. Thought the original question was something completely different.
Thanks for all the help in solving this UTF problem and
giving me some insights into the murky world of Unicode, at
the same time cleaning up my atrocious Perl
You're all a
real blessing for the Linux community. Keep up the
excellent work!
[Ben]
You're certainly welcome; glad we could help!
Submitters, send your News Bytes items in
PLAIN TEXT
format. Other formats may be rejected without reading. You have been
warned! A one- or two-paragraph summary plus URL gets you a better
announcement than an entire press release. Submit items to
bytes@linuxgazette.net
Legislation and More Legislation
Patents
The European Union directive on the patentability
of computer-implemented inventions has been
rejected by the European Parliament by a large margin; the final
tally was 648 votes to 14, with 18 abstentions.
This high turnout came following
intense lobbying on all sides in the run up to the
vote.
As
reported by The Register, the directive seemed to
hemorrhage support as the vote approached. The Pro-patent
camp became afraid that the anti-software patent amendments
might be reintroduced and given a second stamp of democratic
approval (the Commission could still shelve the whole thing,
but that could be politically difficult). Meanwhile, the
anti-patent activists have been keen to kill this directive,
which they see as having been severely tainted by the
involvement of big (huge!) business pro-patent interests.
The recent behaviour of Cisco
regarding the publication if a
flaw in its products has highlighted the ways in which legal
proceedings can be used to the detriment of individuals and
indeed the security of a community. This story centres on
the decision of Michael Lynn, an employee of Internet
Security Systems, to publicly announce a flaw in Cisco's IOS
(Internet Operating System) software. Lynn came to his
decision to go public after Cisco was notified of the
vulnerability, but had failed to remedy the fundamental
problem. As Lynn has noted, the source-code to Cisco's IOS
has been stolen twice, so he felt there was a significant
chance that outside parties would soon be able to develop a
practical exploit unless measures were taken to force Cisco
to patch the flaw.
When Cisco became aware of Lynn's decision to speak at the
Black Hat Conference,
pressure was put on ISS, Lynn's employers, to prevent him
from going through with his presentation. Lynn was also
personally threatened with legal action. Following this
pressure, Lynn resigned from his position at ISS, but went
ahead with his presentation.
The basis for Cisco's legal attack on Lynn was that he had
illegally obtained his information, as to do his research he
had violated the Cisco license agreement with regards to
reverse engineering. Although in the immediate aftermath of
Lynn's presentation he was still being threatened with legal
action,
a settlement has since been reached. The terms of this
include preventing Lynn from further using the Cisco code in
his possession for reverse engineering or security research,
and he is also forbidden from presenting his research on
this flaw again. In the meantime, Michael Lynn is looking
for a new job.
Another country
pushes towards Linux.
The Norwegian Minister for Modernisation
Morton Andreas Meyer is asking governmental institutions
to prepare, before the end of 2006, plans for the use of
open-source. In particular, it is hoped to avoid the use of
proprietary formats for communication with citizens.
(courtesy Howard Dyckoff).
Linux vs Windows-Mobile
It
has been reported that
embedded Linux powered 14 percent of smart phones shipped
worldwide in Q1. Meanwhile, Windows Mobile shipments made up
just 4.5 percent of the market (courtesy Howard Dyckoff).
Critical MySQL Flaw Found
A "highly critical" flaw
has been reported in MySQL that can be exploited to
cause a DoS (Denial of Service) or to execute arbitrary code
on the open-source database.
Distro News
Asterisk@Home
Asterisk@Home
is a GNU/Linux distribution aimed at lowering
the level of technical skills required for home users to be
able to make use of Asterix, the open source PBX (Private
Branch Exchange) telephony software.
NewsForge has
a detailed article
on this distribution.
Debian
The Debian project
has moved to reassure users
by confirming that the security infrastructure for the new
current release, Debian GNU/Linux 3.1 (alias sarge) and the
former release (3.0, alias woody), both enjoy the benefits
of a working and effective security infrastructure. This
reassurance followed a brief period after the release of
Sarge, during which issues with the security infrastructure
prevented the issuing of updated to vulnerable packages.
The Debian project has
announced
that this year's
Debian Conference
was a great success with more
than 300 people attending and over 20 sponsors. One highlight was the
presentation about the large-scale deployment of 80,000 Debian
workstations in Extramadura, Spain. The presentations were captured by
the video team and are
available online.
Though it is not of course based on Linux, many GNU/Linux
enthusiasts will doubtless be interested to learn of the
existence of
FreeSBIE, a FreeBSD based liveCD. This software has
been
featured on NewsForge.
SoftIntegration, Inc. has announced
the availability of Ch 5.0 and Embedded Ch 5.0 for Linux on PowerPC
Architecture. Supported platforms include iSeries, pSeries, OpenPower, JS20
Power based Blades and zSeries from IBM as well as computers from Apple
Computer. Ch is an embeddable C/C++ interpreter for cross-platform scripting,
2D/3D plotting, numerical computing, shell programming and embedded scripting.
The release of Ch and its toolkits for Linux PPC continues SoftIntegration's
involvement in cross-platform scripting, numerical computing and embedded
scripting. Ch Control System Toolkit, Ch Mechanism Toolkit, Ch CGI Toolkit
and C++ Graphical Library are available in Linux PPC as well.
Apache HTTP Server 2.1.6-alpha Released
The Apache Software Foundation
and
The Apache HTTP Server Project
have
announced the release of version 2.1.6-alpha of the Apache
HTTP Server ("Apache").
The 2.1.6-alpha release addresses a security vulnerability present
in all previous 2.x versions (but not present in Apache
1.3.x).
Apache HTTP Server 2.1.6-alpha is
available for download.
Sun and Open Source
Sun
has announced that it will open source the next release
of its Java Application Server.
Also planned is to release its Instant Messaging code as open source.
This will take place under the CDDL license, also used for
Sun's OpenSolaris project.
(Courtesy of Howard Dyckoff)
Mick is LG's News Bytes Editor.
Originally hailing from Ireland, Michael is currently living in Baden,
Switzerland. There he works with ABB Corporate Research as a
Marie-Curie fellow, developing software for the simulation and design
of electrical power-systems equipment.
Before this, Michael worked as a lecturer in the Department of
Mechanical Engineering, University College Dublin; the same
institution that awarded him his PhD. The topic of this PhD research
was the use of Lamb waves in nondestructive testing. GNU/Linux has
been very useful in his past work, and Michael has a strong interest
in applying free software solutions to other problems in engineering.
This article is a follow-up to Maxin B.
John's article, which introduced us to the Festival
text-to-speech synthesizer and some possible applications. Here, we will
push it a bit further and see how we can convert ebooks from the most
common formats like HTML, CHM, PS and PDF into audiobooks ready to send to
your portable player.
The Why
With the high availability of cheap and small portable MP3 players
these days, it has become very convenient to listen to books and
articles just anywhere when you would not necessarily have the time
to read them. Audiobooks usually require very small bit-rates, and hence
very small sizes - and as a consequence they are the most suitable content
for the cheap/small capacity MP3 players (128 MB or less).
There are lots of websites out there catering for audiobooks
needs with a wide range of choices. However, it might happen that you
really want to read that article or book that you found on the
web as a PDF or as HTML, and there is probably no audio version of it
available (yet). I will provide you with some scripts that will
enable you to convert all your favorite texts into compressed audio
files ready to upload and enjoy on your portable player. Here we go!
the lame MP3 encoder
(we'll encode to MP3 since this is the most widely-supported format
in hardware players)
Most of these tools are packaged in the main Linux distributions. Once you
have all of the above installed, we can start the fun. We will begin with
one of the most common format for ebooks: Adobe PDF.
Postcript / Adobe PDF to MP3
#!/bin/sh -
chunks=200
if [ "$#" == 0 ]; then
echo "Usage: $0 [-a author] [-t title] [-l lines] <ps or pdf file>"
exit 1
fi
while getopts "a:t:l:" option
do
case "$option" in
a)author="$OPTARG";;
t)title="$OPTARG";;
l)chunks="$OPTARG";;
esac
done
shift $((OPTIND-1))
ps2ascii $@ | split -l $chunks - tmpsplit
count=1
for i in `ls tmpsplit*`
do
text2wave $i | lame --ta "${author:-psmp3}" --tt "$count ${title:-psmp3}" \
--tl "${title:-psmp3}" --tn "$count" --tg Speech --preset mw-us \
- abook${count}.mp3
count=`expr $count + 1`
done
rm tmpsplit*
How it works
First 'ps2ascii' converts the PDF file or Postscript file to simple
text. That text is then split into chunks of $chunks lines; you
might have to tweak that value, since splitting the book into more than 255
files might cause troubles in some players (the id3v1 track number tag can
only go up to 255.) After that, each chunk is processed by text2wave and
the resulting audio stream is sent directly to 'lame' through a pipe. The
encoding is performed with the mw-us preset, which is mono ABR
40 kbps average at 16 kHz. That should be enough, since Festival outputs a
voice sampled at 16 kHz by default. You can leave it as it is, unless you
are using a voice synthesizer with a different sampling rate. Refer to
lame --preset help for optimum settings for different sampling
rates.
When you input the artist or title, do not forget to quote the string
if it includes spaces; for example:
ps2mp3 -a "This is the author" -t "This is the title" my.pdf
Next, we are going to see how to convert to an audio file from the most
common format: HTML.
HTML to MP3
#!/bin/sh -
#requires lynx, festival and lame
if [ "$#" == 0 ]; then
echo "Usage: echo $0 [-a author] [-t title] <html file1> <html file2> ..."
exit 1
fi
while getopts "a:t:" option
do
case "$option" in
a)author="$OPTARG";;
t)title="$OPTARG";;
esac
done
shift $((OPTIND-1))
count=1
for htmlfile in $@
do
section=`expr match "${htmlfile##*/}" '\(.*\)\.htm'`
lynx -dump -nolist $htmlfile | text2wave - | lame --ta "${author:-html2mp3}" \
--tt "$count. ${section:-html2mp3}" --tl "${title:-html2mp3}" \
--tn "$count" --tg Speech --preset mw-us - ${section}.mp3
#rm /tmp/est_*
count=`expr $count + 1`
done
How it works
The first part of the script, up to line 16, is about extracting the
optional parameters from the command line. From line 19 we are going to
perform a loop on the list of all HTML files, the remaining arguments given
at the command line. On line 21, "${htmlfile##*/}" strips out everything
up to and including the last "/" character - useful if we are dealing with URLs or
a directory path - so only the filename remains. Then the '\(.*\)\.htm'`
regular expression takes care of the extension of the file so the variable
section holds only the stem of the file. It will be used to tag and
name the resulting MP3 files.
Line 22 is really the heart of the script: first, 'lynx' takes an HTML
file as input and dumps its text to stdout. That output is piped to
'text2wave' and converted into a WAV-encoded stream, which is then piped to
'lame' to be encoded with the mw-us preset and id3-tagged with
the artist/title/speech genre.
Note that the script can also take URLs as arguments, since they are
directly sent to lynx.
This html2mp3 script is going to be
very useful for our next step, which is converting from CHM to MP3.
CHM files are a proprietary format developed by Microsoft, but
basically they are just compiled HTML files with an index and a table of
contents in one file. Their use as an ebook format is certainly not as
widespread as HTML or PDF, but as you will see, it is pretty
straightforward to convert them to audio files once you have the right
tools.
CHM to MP3
#!/bin/sh -
#requires archmage and html2mp3
if [ "$#" == 0 ]; then
echo "Usage:"
echo " $0 <chm file> [-a author] [-t title] <html file1> <html file2> ..."
exit 1
fi
while getopts "a:t:" o
do
case "$o" in
a)author="$OPTARG";;
t)title="$OPTARG";;
esac
done
shift $((OPTIND-1))
archmage $1 tmpchm
find tmpchm -name "*.htm*" -exec html2mp3 -a "$author" -t "$title" {} \;
rm -fr tmpchm
How it works
archmage is a Python-based script that extracts HTML files from
CHM. You will need to have Python installed to get it to run.
Unlike 'ps2mp3', 'chm2mp3' does not require an arbitrary decision on
where to split the book: every page compiled into the CHM file becomes its
own audio file. All we need to do is extract these pages with 'archmage'
and convert them with 'html2mp3'.
We are using the find command to recursively search for HTML
files in the CHM book that we extracted, since sometimes the HTML files are
stored in subdirectories inside the CHM. Then, for each HTML file found, we
call 'html2mp3'.
Timing
Remember that it can take a while to encode several dozen
pages of text to speech and then to MP3. But you do not need to encode a
full book to start uploading and enjoying it on your portable player.
JavaOne was huge this year, with 15,000 conference attendees and over
200,000 on-line visitors. The world's biggest Java Developer event got
lots of attention, but for more than just its attendance numbers. Besides
deep structural changes to simplify the Java programing paradigm, Sun
dipped more of its corporate toes into the waters of Open Source Software
after its recent release of its flagship Solaris OS under the CDDL (Common
Development and Distribution License).
While Java isn't free of Sun licensing encumbrances, more of it is more
open to the Java developer community and key Sun software efforts are
becoming OSSw projects. Leading the trend is the next version of Sun's
Java Application Server, to be called Project Glassfish. This is a
contribution of over 1 million lines of code! Sun's current developer
group will seed the project under CDDL.
Developers can view the latest daily updates, contribute to fixes and
features, and join in discussions at http://glassfish.dev.java.net.
Sun also is sharing its Java System Enterprise Server Bus (Java ESB) under
the OSI-approved CDDL license [ also being used for Sun's OpenSolaris
project ]. While the idea of an ESB isn't new, this is the first major
effort that will be OSSw-based. ESBs are based on the Java Business
Integration (JBI) specification (JSR 208).
And if that isn't interesting enough.... Sun is donating 135,000 lines of
collaboration-focused communication source code from its Sun Java System
Instant Messaging and Sun Java Studio Enterprise products for use by the
entire open source community on NetBeans.org.
The collaboration software, which was demoed both at a Keynote and at the
free NetBeans Developer Day that proceeded JavaOne, is designed to
increase productivity by enabling Java developers to dynamically work
together anywhere around the world. It also offers corporate types a
roll-their-own IM app. Both demos worked fine, but your mileage may vary.
That free NetBeans Day may have been a bit of self-promotion, but the
sessions were decent and the demos were later repeated at JavaOne.
Included was a very nice looking Java-based software CD player that also
works nicely and is downloadable at the NetBeans web site.
Sun is also making previews of the next versions of Java available to allow
greater community contributions. And Sun is simplifying its hefty naming
scheme ["Java 2 Standard Edition version 5.xxx"] to just Java
SE 5 [or Java EE 6]; the '2' is gone. And the release versions will not
be dotted in their names. That will save some ink and even some paper
[ older versions will remain unchanged. ]
Big numbers for Java: Sun claims that some 2 Billion devices have Java in
some form, including 708 million mobile devices and 700 million desktops
and an incredible 825 million Java-enabled smartcards! That's a whole
lotta of Java.
Japanese telcom NTT/Docomo is spending a lot on Java too. Some 60% of the
billion dollars its investing in new service and software development will
be Java-based. This will include their 'Star' project, aimed at building
the next generation Java phone runtime. There was also a new mobility kit
for NetBeans developers, if you are working on embedded Java.
Open Source theme
IBM announced that they will officially support Apache Geronimo as an equal
but lightweight application server alternative for its app server,
WebSphere. IBM has been an active contributor to the Geronimo project, and as
part of that they will donate several Eclipse plugins to speed up J2EE
development. Robert LeBlanc, IBM's WebSphere General Manager, speaking at
a keynote, noted Geronimo's status for IBM and stressed the importance of
SOA [Service Oriented Architecture] for today's integration challenges.
[see more on Geronimo and the heavy use of OSSw by Java users in the BOF section of this report.]
Eclipse 3.1 was officially released after being announced at JavaOne. The
new version allows users to streamline testing, create user interfaces for
rich client applications, and enhance support for Ant build scripts. Also,
NEC became the 100th organization to join the Eclipse Foundation.
Continuing with the developer-friendly, Open Source theme at JavaOne, BEA
Systems is offering official support for both Spring and Struts frameworks
running on top of WebLogic Server.
Oracle announced that it's JDeveloper J2EE development tool will be
available for free and that they have partnered with the Apache MyFaces
project. That was 'free' as in beer....
IBM and Sun announced a new and improved relationship - which is good for
the entire Java community. After sparring a lot for recent years, they
signed a new landmark agreement calling for an 11-year collaboration
effort. It's actually an additional year on the current argreement plus 10
more years... so that's 11 years, but the point is that their collaboration
on Java will improve. Sun's shift to a more Open Source friendly position
probably placated IBM's desire for Sun to loosen its control over Java.
Sun reiterated its position: there would be more OSSw in the Java space
over the next year. Would that include opening up the JVM??? That may be
news for JavaOne 2006.
Jonathan Schwartz, President and COO at Sun, opened the first keynote
address, titled "Welcome to the Participation Age", discussing
the importance of 'participation' in building communities, creating
value and new markets, and driving social change. To drive the point
home, Schwartz added, "The Information Age
is over." [Really?] He was, to be sure, referring to Sun's new
branding that has a curvaceous, subliminal
"S" that stands for "Share" and extends that term
to mean OSSw, Developer communities and even the Wikipedia. Schwartz
re-emphasized that Sun has always shared some of its IP going back to the
founding days of Unix. But watch the replay of the keynote to judge for
yourself.
During the second keynote, Graham Hamilton, a Sun fellow and vice
president, addressed advances planned for Java SE software over the two
upcoming releases, a period of 3 years!
Hamilton offered developers an early taste of Java SE 6 software, which is
expected to ship in summer 2006, and invited them to contribute directly to
the future of Java by reviewing source code, contributing bug fixes and
feature implementations and collaborating with Sun engineers. Developers
can join the community at http://community.java.net/jdk.
The following Java SE 6 features are [or soon will be] available for
testing and evaluation at the JDK software community site on java.net:
Support for client-side web services, including a revamped XML
stack, a new scripting engine, declarative programming support
through annotations and improved developer experience for JDBC
technology programming
Improved end-user experience: An implementation of Microsoft's
"Longhorn" look and feel and the ability to co-exist with
the .NET Common Language Runtime (CLR), and numerous other graphics
enhancements [I'm not sure everyone thinks this is 'better'.]
A new, simpler and faster code verifier and enhanced file I/O.
Beyond these, features being considered for Java SE 7 include:
Streamlined development: Java SE 7 software will extend the use
of generics in the Java Management Extensions (JMX) API and will
use annotations to help make the job of writing Mbeans simpler and
quicker for developers. This will help speed time to market and
reduce development costs;
Simpler administration: Java technology code and resources will
be packaged into modules that identify resources and dependencies
and will provide the ability to discover and load applications in
real time.
XML web services will be used for remote management with the
JMX API
Direct support for XML data types within the Java programming
language
On the Enterprise Java Beans [EJB] development side, there is a new spec
that does away with the Container Managed Persistence scheme [CMP] and make
EJBs much more like 'Plain old Java objects' [or POJOs]. This came about
from a lot of discussion and arm-wrestling with alternative projects and
frameworks, most notable Toplink, Hibernate and JDO. So there will be one
single persistence model for both Java SE and EE going forward.
The new scheme makes extensive use of the new Annotations feature which
allows for in-code specification of resources and dependencies. Although
this approach is not without some controversy in the developer community,
it should ease reading code and do away with complicated deployment
descriptors and, perhaps, make the intent of a developer or team more
obvious. See information on Annotations here: http://java.sun.com/j2se/1.5.0/docs/guide/language/annotations.html
Sun is also releasing support for integration with scripting languages over
both Java 6 and 7 SE. A technical session - TS-7706 Scripting in the
Java™ Platform - described the new scripting engine that is already
available in beta format and will be included in Mustang, Java 6. It is
based on JSR 223 and will support several scripting languages.
[I'm including session numbers and titles since most of the presentations
can be freely downloaded now - see last section below.]
There were several sessions dealing with performance and security, and
these were among the most heavily attended.
The Tuesday session on performance, TS-3268, Performance Myths Exposed, was
one of the few actually repeated on the last day. It reviewed several
strategies and tested these on small and large apps. It also compared 7
JVMs Against 6 performance hacks and summarized it:
- use of "final" does not help performance - in-lining is automatic
- try/catch blocks are [mostly] free
- use of RTTI is a marginal performance win at best - with maintenance costs
Also of note, in spite of an ungainly title, was TS-3397: Web Services and
XML Performance and the Java™ Virtual Machine: What Your JVM™
Is Doing During That Long Pause When XML Processing, With Optimization
Suggestions which highlighted some practical rules-of-thumb to speed
XML-Java interactions:
Understand overall processing pipeline
The most efficient XML representation is (probably) byte[]
Avoid touching XML directly, but if you must touch:
Only headers
Only once
Use the right API/interface for the task
e.g., Axis for SOAP, Xalan TrAX for XSLT, JAXB for marshalling
Corollary to above: you probably don’t want DOM
Avoid extensions
Use coarser-grained APIs
In the area of new and novel, the good Doctor Bil Lewis from lambdacs.com
offers the Omniscient Debugger [for free]. This was during TS-7849.
This debugger collects "time stamps" of everything that happens
in a program. The debugger runs from the command line and once data is
collected you can navigate backwards in time to look at objects, variables,
method calls, etc.
"This is the debugger that you have always dreamed about, but never
thought possible," said Bil Lewis, who developed the ODB. "You
can see which values are bad, locate them, and learn who set them and why.
You don't have to guess where the problems might be. You don't need to set
breakpoints or wonder which threads ran or which methods were called. If a
problem occurred, you can find it. You don't ever have to rerun the
program."
Expect to generate huge log files and have seriously degraded performance
while the logger/debugger is running. Dr. Lewis estimated a hit of 1:2 to
1:40 or so. But you will have all the needed info to find out where the
bug was introduced. And it's free... all in a
single debugger.jar file.
New Security for Web Services, TS-7247, focused on both Java 5 and the
forthcoming Java 6. New features beef up Java security with RSA public
key encryption, triple DES support in Kerberos, XML digital signatures, a
certificate creation API, and a multithreaded SSL engine. There are also
indefinite plans to include a new Microsoft C-API, which would assist Sun's
efforts to better interoperate with future Microsoft crypto offerings.
One of the best TS presentations I've caught was TS-3955, "Nine Ways
to Hack your Web Application", which rated 5 stars by my lights --
complete, concise, interesting, informative, and with clear slides and a
knowledgeable speaker. I overheard many developers praising it in lines
for other sessions.
In the Very Cool category was the Sun SPOTS project, in conjunction with UC
Berkeley. This is a preparation for ubiquitous wireless nets of
nano-robots acting as remote sensors. The SPOTS are capable of autonomous
work and dynamic reprogramming. For instance, they could monitor light and
heat in office buildings after hours to cut energy waste. This is reported
in TS-8601 Java™ Technology and Smart-Dust: Building Intelligent
Sensor Networks.
These low power sensor devices are called motes or SPOTS:
Original work done at UC Berkeley by Professor Kris Pister
Commercialized through Dust Networks™
Simple hardware is used that any computer hobbyist can find:
ARM7 CPU (75MHz)
256Kb SRAM running an 80 KB JVM
2Mb Flash Memory
Chipcon CC2420 RF Transceiver (2.4GHz) with Light and
Temperature sensors and a 3-axis accelerometer.
The remarkable thing is that its all Java, including the device drivers [no
C] and runs directly on the hardware. The JVM is J2ME-based and supports a
multithreaded programming model. Here's a picture.
Also cool was Boeing's static display of its self-piloting drone in the
Pavillion. It uses a 'real time' version of Java and can remain on
station for more than 15 hours. Scott McNealy joked at a Keynote that
Boeing wanted to fly it for a demo, but SF officials didn't want an
aircraft flying itself inside a building. More information is here:
http://www.boeing.com/defense-space/military/unmanned/scaneagle.html.
And for the TV and Movie junkies....
Blu-Ray has Java inside
This was announced at a keynote. Next years' future Blu-Ray HD-DVD players
will ship with Java inside. Blu-Ray is a new DVD format with up to 50
Gigabytes on a single disc. The format was developed to record
high-definition HD video and for storing large amounts of data. Blu-Ray
devices will have a network connection for SOHO use and value-added
services. Several devices were on display at the Pavillion Expo showing
classy 3D menus that made use of the black space above and below a
letter-boxed movie.
There were almost 200 BOFs [Birds of a Feather sessions], almost as many as
conference sessions, and only for 3 evenings, so the overlap factor was
very high. Although there were only a handful in the 11pm hour, there
were a lot of people hanging out past 10 pm. The conference organizers
probably should have scheduled some of these for Thursday evening, after
the last conference sessions, since dozens of BOFs occurred during the big
conference bash - with lots of rock 'n' roll and beer - and that gave many
attendees double conflicts.
Unfortunately, the presentations from the BOFs are not going to be posted
on the JavaOne web site, so there is no second chance on this material.
I'm just sorry I didn't catch more of them.
A solid BOF reported on the Open Source use by Java Developers. Albion
Butters, a senior analyst at Evans Data, reported on a new study showing
80% percent of heavy Java users (using Java more than 50% of the time) and
73% of light Java users (less than 50% of the time) use open source
software for development compared to less than 45% of non-Java developers.
In addition, Java users have more confidence in Linux for mission critical
applications with 80% having enough confidence to use it in such important
deployments compared to less than 50% of non-Java users.
"Microsoft's .NET has established a slight lead in the overall
development space over Java, but we have found that the situation reverses
in the enterprise space with more development taking place in Java than in
.NET, 60% to 56% respectively", Butters said. Also, the study,
involving some 20,000 developers, found that heavy Java users write
multithreaded apps ~80% of the time, vs. only ~30% for non-Java users.
Evans Data provides market intelligence for the IT industry.
This was BOF-9187: "Sorting Out Java Technology Fact from Java Technology
Fiction: Trends, Adoption, Migrations, and Key Issues facing the Developer
Today and Tomorrow". See a slide
HERE.
It should be worth looking up TS-7011, Architectural Overview of the Apache
Geronimo Project. Although I couldn't fit that one into my schedule, I
did attend the associated BOF. [Geronimo is an Apache project to produce
an OSSw J2EE app server.]
The Geronimo BOF
Sometimes you go to a good BOF... sometimes its a really good
BOF. In this case, the Geronimo BOF had a surprise announcement early on.
While Aaron Mulder gave a short status talk on the project, highlighting
that they were almost ready to pass the J2EE TCK, he was interupted by
team member David Jencks who carried an open laptop.
"Its all green!," Jencks shouted as he walked up to a smiling
Mulder. Jencks carried his laptop around showing the result of the test
suite – all green bars. He said that represented 23,000 test cases
and it had been running for a very long time.
Mulder, with rising confidence, announced that NOW Geronimo is J2EE
compliant and got a crash of applause. He and his team gave thanks to the
many OSSw projects that had software incorporated into Geronimo, including
Jetty, OpenEJB, Howl, etc. Although the test was passed, the developers
explained that there were additional usability issues to clear up before
the J2EE certification would be official [this was completed shortly after
JavaOne 2005].
Since many of the developers at Geronimo are IBM employees, there was a BOF
question asking to position Geronimo verses WebSphere. Mulder joked
"Well, we just wanted to release a shoddy product that no one will
want..." [ later there were snarky remarks from an IBM JVM
engineer regarding Sun's JVM, showing the true state of the IBM-Sun
partnership. But then this was a late BOF, and many of these guys had been
working all day on the certification. ]
BOF attendees were also warned not to download the so-called milestone
release -- it's outdated. Instead, they encouraged everyone to download the
"unstable release" which is actually more complete and more
stable. [ See, everything we knew is wrong.... ]
Sun is publishing a commemorative coffee table book that covers how the
Java technology revolution got started and where Java technology can go in
the future. The first 500 attendees to pre-order the book at the JavaOne
got a free Java mug and will get a copy of the book autographed by James
Gosling. And those signing up at JavaOne could have their names included
in the book as members of the Java Community. Sweet perk!
Simplified Format, Snacks
The format of JavaOne was simplified this year by not having early AM
session before keynotes and by holding fewer but larger sessions. Some
rooms (but not all) were set up for overflow sessions, and those that were
'televised' live did not always start at the beginning of presentations.
This also lead to longer and slower lines entering technical sessions.
The delay was partly due to the conference planners, since they made people
line up for technical sessions and then required everyone to have their
badge RFID tag read by a scanner. So, to get a decent seat, we had to
line up immediately after leaving a session and wait for the entire 15
minute break time before they let anyone in. It was a bit like being back
in High School.
They were in fact trying to find out the most popular sessions and which
ones deserved repeating - and by late Tuesday they had added more RFID
readers and were allowing folks to enter earlier. But I do remember
lining up for a session which filled up and then being redirected to
another line at the overflow room which wasn't allowed to enter until after
the session was underway. [Grrr!]
Food also was much simpler, and less interesting, with box lunches and
only served at a single large room in the Moscone Center. In contrast, in
previous years there were 2 or 3 large tents set up outside in the
park-like Yerba Buena Center with multiple buffet lines. That way, people
could get in quickly, pick the items they wanted, and get seconds if
desired. But this new arrangement was probably easier to plan.
I have attended many JavaOne conferences and have written about the many
amenities in glowing terms. This year, with a new conference planning
outfit, the standards slipped a few notches.
Snacks were clearly of lower quality. Only corn and potato chips and Rice
Krispies' Marshmallow Bars [made with animal gelatin], with
occasional pretzels. No energy bars, no health food, very little fruit
and certainly no cookies or brownies! There was only a single
coffee and tea service in the afternoon, but there were 3 regular sessions
and then 4 hours of BOFs. I saw several attendees carrying in Starbuck's
cups, probably because they couldn't wait for the late afternoon beverage
service or needed a boost in the evening.
JavaOne originally set the standard for food and snacks at developer
conferences. In this area, JavaOne has certainly fallen. Compared to
SoftwareDevelopment and OracleWorld, this was a vastly inferior affair for
food. But JavaOne is still a premier technical conference.
You might want to pack your own Cliff Bars next year. And bring a thermos
of java juice....
Howard Dyckoff is a long term IT professional with primary experience at
Fortune 100 and 200 firms. Before his IT career, he worked for Aviation
Week and Space Technology magazine and before that used to edit SkyCom, a
newsletter for astronomers and rocketeers. He hails from the Republic of
Brooklyn [and Polytechnic Institute] and now, after several trips to
Himalayan mountain tops, resides in the SF Bay Area with a large book
collection and several pet rocks.
A Brief Introduction to Network Printing with CUPS
Tired of hassles with printers not intended for Linux and
the endless compromises they involve, I finally decided to buy a
color laser printer with a network card.
There were several factors involved in making this decision:
Cost
Although laser printers are still fairly expensive,
in the long run it should turn out to have been worth the money,
considering the waste of paper, ink, and my time in the past
fighting hardware not seriously supported by the manufacturer under Linux.
Quality
For non-professional photographic requirements
ink-jet is still a better choice, but
the quality of laser printers over time remains excellent
(until they start to run low on toner).
I have had ink-jets continue smearing the paper even after
replacing the cartridge (due to the built-in print-head).
Independence
The motivation for a network card in the printer was
to obtain as much independence from hardware as possible.
It should not be necessary to boot a PC and copy a file
from the notebook onto the PC just to print it.
Noise and Emissions
Laser printers produce distinct odors and can be quite loud.
They really don't belong in the same room with anyone trying
to concentrate on something.
This one does go into power-saving mode but it takes about 15 minutes
for the fan to shut down.
But the consequences of this decision were not trivial.
SuSE (at current writing at 9.3, I'm at 9.2) has been installing CUPS
behind the scenes for several releases.
Since the printer commands are pretty much the same as those used
under lprng, there never was any real need to learn much about CUPS.
Well, not until the network printer arrived and
then very quickly the fun began.
Just one example of the problems:
although the documentation says that the password wanted when logging in
to admin is the root password, that has never worked for me.
However, as usual, if you know what needs to be done,
CUPS really isn't that difficult to work with.
Assuming that CUPS has already been installed on the machine
in question, here is my list of the steps to install a
network printer on it under CUPS.
You will need to do this on every machine that is to have
access to this printer.
Note that in the following, the installation instructions
of the manufacturer are irrelevant.
Make sure you select a printer for which the manufacturer provides a PPD
(Postscript Printer Definition) since only the manufacturer can produce the PPD
needed to make optimum use of the hardware.
Actually, this is important whether the printer attaches directly to a PC
or via the LAN.
The printer I selected didn't have a PPD on the CD-ROMs that came with it,
but a little time searching the Internet pointed me at a file that had
two - one for the black and white variety, and one for color.
As root, do the following:
In /etc/cups/cupsd.conf comment out
AuthType, AuthClass and AuthGroupName
Add "cupsd : ALL" to /etc/hosts.allow
Copy the PPD for the printer into /usr/share/cups/model/
Restart CUPS with "/etc/init.d/cups restart"
As some (non-root) user, issue the following command
(almost verbatim from the CUPS documentation):
"net_printer" is the name to be assigned to the printer and
can be any text string.
If there is only one printer, the name won't need to be used in
any print commands.
"printer.ppd" is the name of the PPD file you placed in /usr/share/cups/model/.
The IP-address I had previously assigned through the front panel
on the printer but CUPS includes a command, arp, with which to do this
by using the Ethernet MAC address.
Then check on the status of printers: "lpstat -p -d".
The output should look something like:
printer net_printer is idle. enabled since Jan 01 00:00
system default destination: net_printer
The line "system default destination" is important.
That is where Mozilla, Opera, OpenOffice, and all their friends will be
printing if not told otherwise when you ask them to print something.
CUPS' web interface "http://localhost:631/admin" is a convenient
way to change the default printer.
Recent converts to Linux should note that a PPD is analogous to but quite
different from the notorious driver.
As with a driver, under CUPS one needs a PPD for the printer.
But it isn't executable code that can make your system unstable.
Perhaps better compared with a configuration file, essentially
it just contains plain-text data that informs the print system (CUPS)
what capabilities the printer has and how to format data accordingly.
On the other hand, each machine that is to send print jobs to the printer
has to have the correct PPD, as is the case with a driver:
the machine initiating printing has to send something to the printer
that it can understand.
By following the above steps, it took me less than 15 minutes to enable a
notebook under SuSE 8.0 to print via the network printer.
And that includes the time it took to remove lprng and install CUPS
from the distribution CD!
Keep in mind that this ignores about 99.99% of CUPS and is totally
insecure.
Anyone with access to your network could start print jobs
wasting toner until the paper runs out.
But for a simple home system behind a firewall, it will enable your network
printer under CUPS and buy you the time to learn all the things we've ignored
for the moment.
Edgar is a consultant in the Cologne/Bonn area in Germany.
His day job involves helping a customer with payroll, maintaining
ancient IBM Assembler programs, some occasional COBOL, and
otherwise using QMF, PL/1 and DB/2 under MVS.
(Note: mail that does not contain "linuxgazette" in the subject will be
rejected.)
There are several templating systems for Python, but here we'll look at PTL and
Cheetah. Actually, I lied; we'll focus on some little-known templating features
of Quixote that aren't PTL per se but are related to it. These can be used
to get around some annoyances in PTL. We'll also compare Cheetah against
PTL/Quixote to see whether one of the two is more convenient overall, or which niches each
system works best in. Both systems can be used standalone in Web or non-Web
applications. You can download Quixote at
http://www.mems-exchange.org/software/quixote/, and Cheetah at
http://cheetahtemplate.org/. Install them via the usual "python setup.py
install" mantra.
The Quixote documentation has a thorough description of PTL, so we'll just
give a brief overview here. A PTL template looks like a Python function, but
bare expressions are concatenated and used as the implicit return value.
Here's an example:
def add [plain] (a, b):
answer = a + b
'a plus b equals '
answer
Calling add(2,3) returns "a plus b equals 5". Doing this in ordinary
Python returns None; the two bare expressions are thrown away. To build an
equivalent to this template, you'd have to use StringIO or build a list of
values and join them. And you'd have to convert non-string values to
strings. So PTL is a much cleaner syntax for functions that "concatenate" a
return value.
The [plain] is not valid Python syntax, so you have to put this function in
a *.ptl module and teach Python how to import it. Assume your module is
called myptl.ptl.
$ python
Python 2.3.4 (#1, Nov 30 2004, 10:15:28)
[GCC 3.3.4 20040623 (Gentoo Linux 3.3.4-r1, ssp-3.3.2-2, pie-8.7.6)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> from quixote.ptl import install # Install PTL import hook
>>> import myptl
>>> print myptl.add(2, 3)
a plus b equals 5
>>> myptl.add(2, 3)
'a plus b equals 5'
One of PTL's features is automatic HTML quoting. Suppose you had this:
def greeting [html] (what):
"<strong>Hello, %s!</strong>\n" % what
A nice user types 'world' into a form and your function returns:
PTL escapes it automatically in case you forgot to. How does it know which
values to escape? It escapes everything that's in a bare expression and not
defined literally in the function: arguments, subroutine return values, and
global variables. To protect a string from further escaping, wrap it in an
htmltext instance:
>>> from quixote.html import htmltext
>>> text = htmltext("<em>world</em>")
>>> print myptl.greeting(text)
<strong>Hello, <em>world</em>!</strong>
In fact, the return value is itself an htmltext instance:
htmltext is mostly string compatible, but some Python library functions
require actual strings:
>>> "The universe is a big place.".replace("universe", text)
Traceback (most recent call last):
File "<stdin>", line 1, in ?
TypeError: expected a character buffer object
This is one of the annoyances of PTL. The other is overquoting. Sometimes you
have to use str() and htmltext() to get around these. Sometimes this is
a pain in the butt. It causes parenthesesitis, long lines, obfuscated code,
makes generic modules dependent on Quixote, etc. At least htmltext dictionary
keys match their equivalent string keys. But if you intend to use the
dict as **keyword_args, you'd better str() the keys.
PTL's third annoyance is the import hook. It's "magic", it may break sometime,
it doesn't play well with other import hooks, and it has a failed-import bug.
(The latter two are probably Python's fault rather than PTL's.) The
failed-import bug is that if you import a module that doesn't exist, the
variable is set to None rather than raising an ImportError. This causes a
cascading error later when you try to access an attribute of it, similar to a
null pointer dereference in other languages. You just have to remember that if
a variable is unexpectedly None, it may mean a failed import. (This bug
happens only in some circumstances, but I haven't figured out which.)
When using PTL with ZODB, the Quixote docs warn to import ZODB before PTL.
ZODB has its own import hook, and they must be installed in this order or
you'll get errors. I discovered the same thing happens with Python's fcntl
module on the Macintosh. fcntl doesn't have an import hook, but PTL's hook
has an unexpected interaction that causes fcntl to fail. On Mac OS X 10.3
(Python 2.3.0), fcntl.so is in a separate directory along with other "C"
extensions. After installing PTL, importfcntl finds the deprecated
FCNTL.py due to the Mac's case-insensitive filesystem. This is a dummy module
that has constants but no functions. So you try to do file locking
and blammo!
AttributeError. To get around this you have to import fcntl before PTL, or
put the extension directory at the start of the Python path before importing
fcntl. If you're doing this at the start of your application because a
third-party module later uses fcntl, it can be confusing to future application
maintainers. (Python 2.4 supposedly doesn't have this problem because FCNTL.py
doesn't exist.)
When the import hook works, it works great. But you may be leery of it due to
known or unknown problems. What alternatives are there? PTL creates a *.pyc
file, so once the module has been imported you don't need the hook again unless
the source changes. But *.pyc files aren't compatible between Python versions,
and you may forget to import-with-hook after making changes. So what other
alternatives are there?
PTL is built from components that can also be used standalone in ordinary
Python functions. This is not covered in the Quixote documentation but can be
deduced from the source. Our first example above translates to:
from quixote.html import TemplateIO
def add(a, b):
tio = TemplateIO()
answer = a + b
tio += 'a plus b equals '
tio += answer
return tio.getvalue()
>>> import mymodule
>>> mymodule.add(2, 3)
'2 plus 3 equals 5'
As you can see, it's similar to StringIO but with a cleaner interface. It
also automatically converts the right side to a string. There's a flag to do
HTML escaping:
from quixote.html import TemplateIO, htmltext
def greeting(what):
tio = TemplateIO(html=True)
tio += "&"
tio += htmltext("<strong>Hello, %s!</strong>") % what
return tio.getvalue()
>>> reload(mymodule)
>>> mymodule.greeting("<javascript>")
<htmltext '&<strong>Hello, <javascript>!</strong>\n'>
Here we have to explicitly htmltext() everything we don't want escaped. Is
this better or worse than PTL? Is the TemplateIO syntax better or worse than
PTL? That's for you to decide. I prefer PTL for some modules and TemplateIO
for others. TemplateIO is also better for generic modules that shouldn't
depend on the import hook. The TemplateIO class resides in
quixote/html/_py_htmltext.py. (There's also a faster "C" version,
_c_htmltext.c.) You can copy the module to your own project (check the license
first), or write a simple non-escaping TemplateIO in a few lines of code.
_py_htmltext.py also contains other classes and functions used by PTL and
TemplateIO: htmltext, htmlescape, and stringify. stringify is a
function that converts anything to string or unicode, a kind of enhanced
str(). htmlescape calls stringify, escapes the result, and returns a
htmltext object. But if the argument is already htmltext, htmlescape doesn't
escape it. So when we said htmltext protects a string from being escaped,
we really meant htmlescape treats htmltext specially.
When you use one of htmltext's "string methods", it calls htmlescape on its
arguments. (Actually it inlines the code, but close enough.) So where we used
the % operator in greeting() above, it escaped the right side. This is
a common idiom in programs that use htmltext: put the htmltext wrapper on the
left side of the operator, and let it escape the arguments on the right side:
result = htmltext("<em>%s</em>" % arg) # BAD!!! 'arg' won't be escaped.
It's usually most convenient to put the htmltext() call as close to the
variable definition or import/input location as possible. That way you don't
have to worry about whether it's been wrapped or not. This can be a problem
for generic modules that would suddenly depend on Quixote, but again you can
copy _py_htmltext.py into your project to eliminate that dependency.
But what if you really want your template to be a large string with
placeholders that "looks like" the final output? PTL is fine for templates
with lots of calculations and small amounts of literal text, but it's less
convenient with large chunks of text. You either have large multiline strings
in the function, making the expressions hard to find, or you use global
variables for the literal text. Sometimes you'd just rather use a
traditional-looking template like this:
Cheetah does this. It has a users' guide (which I mostly wrote), so we'll
just complete the example without explaining it in detail:
from Cheetah.Template import Template
t = Template(file="mytemplate.tmpl")
t.title = "Greetings"
t.content = "<em>Hello, world!</em>"
print str(t)
<html><head><title>Greeting</title></head><body>
<strong>Hello, world!</strong>
</body></html>
Cheetah has many features we won't discuss here, but one feature it doesn't
have is smart escaping. You can set a built-in filter that escapes all values,
and you can turn the filter on and off at different points in the template, but
you can't escape certain values while protecting htmltext values.
Well, actually you can if you write your own filter.
[text version]
from Cheetah.Filters import Filter
from quixote.html import htmlescape
class HtmltextFilter(Filter):
"""Safer than WebSafe: escapes values that aren't htmltext instances."""
def filter(self, val, **kw):
return htmlescape(val)
Instantiate the template thus:
t = Template(file="mytemplate.tmpl", filter=HtmltextFilter)
Sometimes you want to put an HTML table in a Cheetah template, but you don't
want to type all the tags by hand. I've written a table module that builds
a table intuitively, using TemplateIO and htmltext. Here's the
source. The
module docstring has the complete usage, but here are a few examples:
import table
# A simple two-column table with headers on the left, no gridlines.
data = [
('First Name', 'Fred'),
('Last Name', 'Flintstone')]
print table.ReportTable.build(data)
# A table with headers at the top.
headers = ['Name', 'Noise Level']
data = [
('Pebbles', 'quiet'),
('Bam-Bam', 'loud')]
print table.Table.build(data, headers)
# A table with custom tags.
data = [
('Fred', 'Flintstone', '555-1212')]
td = htmltag('td')
td_phone = htmltag('td', css_class='phone')
tds = [td, td, td_phone]
t = table.Table()
t.table = htmltag('table', css_class='my_table')
for row in data:
t.row(row, tds) # Match each cell with its corresponding <td> tag.
print t.finish()
The output is a htmltext object, which you can set as a placeholder value for
Cheetah.
quixote.form lets you build forms in a similar way, and the same object
does form display, validation, getting values, and redisplay after errors. I
highly recommend it. Like everything else here, it can be used standalone
without the Quixote publisher.
PTL and Cheetah use a non-tag syntax for replaceable values, so they work
just as well for non-HTML output as HTML. Zope Page Templates (ZPT/TAL) and
Nevow's template system, among others, use XML-style tags for placeholders.
This limits their usability for non-HTML output. I prefer to use one template
system for all my output rather than one for HTML and another for non-HTML, and
I hate XML tags. Those who love XML tags may prefer ZPT or Nevow. Nevow has an interesting way of
building replacement values via callback functions, which literally
"put" the value into the template object. (I wrote about Nevow in a
previous PyCon article.) More ZPT/TAL
information is here.
These all can be used without their library's publishing loop.
I hope this article gave you some ideas on the many ways you can structure a
template in Python.
Mike is a Contributing Editor at Linux Gazette. He has been a
Linux enthusiast since 1991, a Debian user since 1995, and now Gentoo.
His favorite tool for programming is Python. Non-computer interests include
martial arts, wrestling, ska and oi! and ambient music, and the international
language Esperanto. He's been known to listen to Dvorak, Schubert,
Mendelssohn, and Khachaturian too.
The Mac Mini is a very
compact desktop computer designed by Apple. Based on the PowerPC (PPC) G4
CPU, the machine is ideal for those who wish to experiment with GNU/Linux
on a non-Intel platform. In this article, we will examine how to get
Ubuntu Linux up and running on the Mac Mini. Assembly language skills on a
RISC CPU like the PowerPC are very much in demand in the embedded-systems
industry - and we shall use the PPC Linux system to do a bit of assembly
language hacking!
The Mac Mini Hardware
The Mac Mini runs on a PowerPC CPU having
a clock speed of 1.25GHz (a higher-end version is also
available). Figure 2 shows the output of
running 'cat /proc/cpuinfo' on my machine:
There is a 40GB IDE hard disk, two USB ports, one
firewire port, built-in sound and a "slot-loading" CD/DVD drive.
The power supply,
rated at 85W, is provided as an external 'brick'. The unit does not
come with a monitor or keyboard - you have to provide
them yourself. Both the keyboard and the mouse are USB-based.
I had no difficulty getting my Microsoft USB mouse detected,
but I had to try a few different brands before I got my USB keyboard
working.
There are some minor hardware peculiarities - one is the absence
of an 'eject' button for the CD drive. If you are running Linux
or MacOS, software eject will work; otherwise, holding the mouse
button down during the boot process will do the trick. Another
idea is to get into 'OpenFirmware' (similar to the CMOS setup
on the PC) during the boot process by holding down the
Alt-Windows-O-F keys and
then executing the 'eject cd' command. Booting from the CD requires
holding down the 'c' key during powerup.
Installing Ubuntu
Ubuntu Linux has a PowerPC edition; the CD image can be
downloaded from http://ubuntulinux.org. The Mac Mini
comes pre-installed with MacOS X in the single partition which occupies the
whole of the hard disk. The first step, then, is to run the installation CD and
get OS X into a smaller partition (say 20 GB). Once this is
done, you can boot with the Ubuntu installation CD and create
a few partitions for Linux to work with. The rest of the Ubuntu
installation process will proceed very smoothly and you will
have a MacOS X/Linux dual boot system working perfectly.
Tweaking Ubuntu
Ubuntu is a nice end-user distro; but developers will have to
put in some effort to get their favourite tools working.
I had to do an:
apt-get install gcc
to have 'gcc' working. I downloaded the 2.6.8.1 kernel from kernel.org and tried compiling it with
make menuconfig
which failed because the 'ncurses-devel' package was missing. The
problem was solved by getting ncurses-5.4.tgz from a GNU FTP site
and installing it from source.
Once the kernel compilation process is over, you will see
a file called 'vmlinux' under the root of the kernel source tree.
This has to be copied to the '/boot' directory under a different
name, e.g. 'mykernel'. PowerPC systems use the 'yaboot' boot
loader whose configuration file '/etc/yaboot.conf' looks similar
to LILO's config file. Here is what I added to my 'yaboot.conf':
The 'ybin' program has to be executed to install the boot
loader.
Learning PowerPC Assembly
The PowerPC is more of a processor specification rather
than a processor. Originally developed by an Apple-IBM-Motorola
alliance, there are a lot of processors in the market which
can be called PowerPCs; the Mac Mini uses a processor called
7447A. PowerPC chips are often used in embedded devices
as well as in high-end servers.
Understanding the architecture and the assembly language
of a microprocessor is crucial in tasks which involve
low level interaction with the machine - like designing/debugging
operating systems, compilers, embedded applications, etc.
The Mac Mini running GNU/Linux can be used by universities and
engineering colleges to provide computer architecture
education to its students. We shall examine the basics
of PowerPC assembly language programming in the rest of this
article, mostly with a view towards understanding the code which
GCC generates.
Getting Started
The PowerPC is a Reduced Instruction Set Computer (RISC). All instructions
are encoded uniformly in 4 bytes and the only instructions which access
memory are load and store instructions. There is a large register set
consisting of 32 integer registers, 32 floating point registers, a
condition register (CR), a link register (LR) and a few others. Programmers
familiar with the x86 instruction set will note the absence of special
registers like the stack pointer - the idea is that one of the general
purpose registers itself can be used as a stack pointer. An Application
Binary Interface (ABI) defines the conventions to be adopted; the SVR4 ABI,
which ppc32 Linux follows, requires GPR1 (General Purpose Register 1) to be
used as a stack pointer. Also, the ABI requires arguments to a function to
be passed in registers starting with GPR3. A function can freely modify
GPR3 to GPR12 - the caller is expected to save them if necessary.
Listing 1 shows a simple
assembly language program. Let's see what each of the
instructions does.
The instruction:
li 4, 0x10
loads the immediate (constant) value 0x10 to the general purpose register
4; x86 programmers may be bothered by the use of pure numbers to represent
registers rather than more meaningful names like r0, r1 etc. The instruction:
add 4, 4, 5
may be thought of as doing the algebraic operation:
r4 = r4 + r5
That is, sum the contents of general purpose registers 4 and 5 and store the
result in GPR4. The instruction:
addi 4, 4, 5
does the operation:
r4 = r4 + 5
ie, simply add the constant value 5 to contents of register r4.
The 'stwu' (store word and update) instruction is a bit
tricky. The general format is:
stwu rS, d(rA)
The instruction stores the contents of register rS into a memory location
whose effective address has been computed by taking d+rA. At the same time, rA
is updated to become equal to the effective address. Note that the general
purpose register R1 is taken to be the stack pointer, so 'stwu 1, -16(1)'
stores the contents of the stack pointer register to a position at offset
-16 from the current top of stack and decrements the stack pointer by 16.
A sample interaction with 'gdb' shows that this is indeed the case.
What remains is the instruction 'blr' which should be read as
'branch to link register'. The Link Register (LR) is a special
register which holds the return address during a subroutine call.
Our 'main' was called from a standard library 'start' routine; LR
will have the address of the instruction which main should return
to. Doing a 'blr' will result in execution getting transferred
to the address contained in the Link Register.
Using GDB to trace programs
The GNU Debugger helps us single-step through assembly
language programs; we will also be able to examine the
contents of memory locations and registers after executing
each instruction. First, we have to compile the program
like this:
cc -g listing1.s
and invoke gdb:
gdb ./a.out
Here is a sample interaction with GDB:
Breakpoint 1, main () at listing1.s:5
5 li 4, 0x10
Current language: auto; currently asm
(gdb) s
6 li 5, 0x20
(gdb) s
7 add 4, 4, 5
(gdb) p/x $r4
$1 = 0x10
(gdb) p/x $r5
$2 = 0x20
(gdb) s
8 addi 4, 4, 5
(gdb) p/x $r4
$3 = 0x30
(gdb) s
9 stwu 1, -16(1)
(gdb) p/x $r4
$4 = 0x35
(gdb) p/x $r1
$5 = 0x7ffff8e0
(gdb) x/4xb 0x7ffff8e0-16
0x7ffff8d0: 0x7f 0xff 0xf9 0x44
(gdb) s
main () at listing1.s:10
10 addi 1, 1, 16
(gdb) p/x $r1
$6 = 0x7ffff8d0
(gdb) x/4xb $r1
0x7ffff8d0: 0x7f 0xff 0xf8 0xe0
(gdb) p/x $lr
$7 = 0xfebf100
(gdb) s
main () at listing1.s:11
11 blr
(gdb) s
0x0febf100 in __libc_start_main () from /lib/libc.so.6
The 's' (step) command is used for stepping through one
instruction. We can print the value of a register, say, GPR4
by doing 'print $r4' or 'p/x $r4' (print in hex). The contents of
a memory location can be printed by executing a 'x/4xb' command.
We note that executing the 'blr' instruction resulted in control getting
transferred to the location 0x0febf100 - this is the address
which the Link Register (LR) was holding.
The GDB command 'disas' (short form for 'disassemble') can be used
to view the assembly code in a better way - here is the output
obtained by running 'disas main':
(gdb) disas main
Dump of assembler code for function main:
0x100003d0 <main+0>: li r4,16
0x100003d4 <main+4>: li r5,32
0x100003d8 <main+8>: add r4,r4,r5
0x100003dc <main+12>: addi r4,r4,5
0x100003e0 <main+16>: blr
The 'objdump' command too can be used to disassemble the
machine code.
Subroutine Call
Branching to a subroutine results in the return address being stored in the
Link Register - if this subroutine calls another one, the current address
in LR will be lost, unless it is saved on the stack. Listing 2 shows a simple C program and
Listing 3 is part of its assembly
language translation obtained by running:
gcc -S -fomit-frame-pointer listing2.c
Let's try to work out the code line by line.
The first line of 'main' simply decrements the stack pointer
by 16 and stores the old value at that location. We are
basically building a stack frame to hold the local variables
defined within the function. Let's say the initial value of
the stack pointer is 1000; after the first line, it becomes
984. The next instruction, 'mflr 0' copies the contents of the
link register to general purpose register 0 which is then stored
onto the stack by the 'stw' instruction at a location whose
address is found by adding 20 to the value of the stack pointer
register r1 (ie, location 1004).
The next two lines copy the number 3 to r0 and then stores it
at the location whose effective address is computed by adding
8 to the contents of r1 (ie, location 992); this is the variable 'm' defined
in our C program. The 'load word and zero' (lwz) instruction
loads the register r3 with the value of 'm' and executes a 'branch and
link' to function 'fun'. The 'bl' instruction transfers control to
the function 'fun' and at the same time loads the Link Register with
the address of the instruction immediately after the 'bl' in 'main'.
We note that the old value of LR (which is the address to which
'main' is to return to) is overwritten, but that is not a problem
because we have already saved this value on the stack.
The function 'fun' sets up its own stack frame and copies the
value it received in register r3 onto the stack thereby creating
the local variable 'x'. This is then copied into r9, incremented
and copied to r3 (the instruction 'mr 3, 0' copies the value in
r0 to r3). The function returns by doing a 'blr' - the stack
pointer is adjusted back to its initial value before the return
is executed.
Back in 'main', the value in r3 (the return value) is copied
to the variable 'm' stored on the stack. The old value of the link
register saved on the stack is copied to r0 after which the
'mtlr' (move to link register) instruction transfers it to LR.
The function then returns by doing a 'blr'. The entire sequence
of events can be understood clearly by stepping through the
code using GDB.
Invoking System Calls
The 'arch/ppc/kernel/misc.S' file under the PPC32 Linux kernel source
tree defines a data structure called a 'sys_call_table' which holds
pointers to all the system calls defined in the kernel. Here is a
part of this array:
We note that the address of the fork function is stored in slot 2 of
this array - the system call number of 'fork' is therefore 2. It's possible
to write a simple assembly language program which invokes 'fork' - the idea
is to execute the 'sc' instruction after storing the call number in r0 and
any arguments in r3, r4 etc. Listing
4 demonstrates the idea. The program goes in a loop (by using the
'branch' instruction, 'b') after invoking 'fork'. If we run 'ps ax' on
another console, we would be able to see two copies of 'a.out' running -
proof that 'fork' has indeed been invoked!
Taking the address of a variable
Listing 5 is a simple C program in
which we store the address of a local variable in a pointer and then
dereference the pointer to modify the pointed-to object. Listing 6 is part of the assembly
language translation obtained by calling 'gcc -S -fomit-frame-pointer'. We
see that the assembly code is not doing anything special. The situation is
a bit different when we try to take the address of a global object. The
problem is that because each instruction (opcode + operands) is encoded in
32 bits, it is impossible to store a 32 bit address as part of the operand
of a PowerPC instruction - we will have to split the address into two parts
and add them up in a 32 bit register using two instructions. Listing 7 is part of the assembly
output that we would get if the variable 'i' in Listing 5 had been defined
as a global.
Let's compile the code into an 'a.out' and execute the command:
nm ./a.out
'nm' shows you the names and addresses of all the globally visible symbols
in your program; on my machine, I see that the variable 'i' has been
assigned the address 0x100108a8. Split up into two parts and expressed in
decimal, the most significant 16 bits is 4097 and the least significant
16 bits is 2216. Coming back to the assembly language program, the two lines
we are interested in are:
lis 9, i@ha
la 0, i@l(9)
A disassembled listing of the program displays these lines as:
lis r9, 4097
addi r0, r9, 2216
The assembler has encoded the 'load algebraic' instruction as an 'add'
which has the same effect; this is something very common in PowerPC
assembly programming. The notation 'i@ha' results in the higher 16 bits of
the address of 'i' getting extracted and 'i@l' yields the lower 16 bits.
The 'load immediate shifted' (lis) instruction loads 4097 into the most
significant bits of r9 and the add instruction simply combines it with the
lower 16 bits of the address of 'i'.
Smashing the stack
PowerPC programs too are vulnerable to the same buffer overflow
attacks so common on x86 architectures. A function saves the
contents of the Link Register on the stack if it calls some
other function; it is very easy to overflow a buffer and overwrite
this return address. Listing 8
shows a C program in which we overflow the buffer 'a' - we are adding 12 to
the contents of a[13]. Reading the assembly code produced by doing
cc -S -fomit-frame-pointer listing8.c
tells us that a[13] refers to the memory location where
the Link Register has been saved. Adding 12 to it results in the
function returning back to its caller (main) with the next 3
instructions skipped ('m++' takes 3 instructions and each instruction
is encoded in 4 bytes). So the program prints 57 instead of
58. Listing 9 shows the relevant
assembly code segment.
Further Reading
We have just had a glimpse into the fascinating world of
assembly language programming -
readers interested in Computer Architecture should refer to
the book 'Computer Organization and Design - The Hardware/Software
Interface' by Patterson and Hennessy to get some idea
of the amazing techniques used by microprocessor designers
to convert a slice of silicon to a marvel of engineering.
As a student, I am constantly on the lookout for fun
and exciting things to do with my GNU/Linux machine. As
a teacher, I try to convey the joy of experimentation,
exploration, and discovery to my students. You can read about
my adventures with teaching and learning here.
What does Linux need to do in order to supplant Windows as the
dominant OS on the desktop? This is a legitimate question often
asked, but never answered very well.
Part of this may have to do with the basic makeup of people
working on an OS that is almost designed not to be profitable. Such
individuals often do not think like capitalists. Perhaps it is
time to start thinking that way.
Profit is not necessarily a dirty word. I do not hold Bill Gates
in contempt because he is a millionaire many times over. He got
that way by supplying a product. In that, he is no different from
J. K. Rowling, now the richest woman in England. Why should the
rest of us Muggles not do the same?
Perhaps a better model corporate citizen for us to examine might
be Apple's CEO Steven Jobs. Aside from being somewhat of a
crackpot (in good company, I might add), he too, supplied a
product... and developed a market for that product where there had
not been one earlier. As testimony to his success... how many of
you cut your teeth (pun intended) on an Apple IIe or an early
MacIntosh?
An interesting point about Apple in the early years is the fact
that they designed software to work on one specific set of hardware
products and marketed them both as a single conglomerate product.
Since they did not have an XYZ Corporation's made-in-(insert
country of contemptuous choice) ISA interface holographic display
card in their hardware, they didn't have to worry about some kind
of machine ghost materializing whenever anyone tried to use it with
another manufacturer's tri-D manipulation device.
The Home User Desktop Machine Of the Future (HUDMOF) will be a
conglomerate machine that supports only the hardware in the
conglomeration. While other hardware might work, whoever builds the
HUDMOF has no incentive to support hardware built and sold by a
competitor... though if the Linux kernel is used, such support will
be available at little or no cost. Also, it will WORK with all the
hardware items in the conglomeration.
We, the Linux Community, need to take a leaf from Capitalism's
book and start competing for the desktop market. How would we
compete? Well, price point is one thing. Free is pretty hard to
beat... but there is no reason why we cannot sell it and make a
profit. What is sold is not the OS itself, but rather, customer
service. Having had my head bitten off from time to time asking
dumb questions on various lists (you know who you are), I can say
that we could all improve our people skills.
You sell customer service by either offering it with the price
of the boxed distribution, or the download. You could, I suppose,
offer it as a separate option a la LinuxCare. You could also use the
OS to sell your hardware, with the OS pre-installed on it. What to
sell and how to sell it depends upon the business model you are
shooting for. In any case, as the OS itself is open-source, you
HAVE to sell something else to make a profit.
Another point is reliability, which Linux excels at, once it is
set up. This is something that is a real advantage over Windows. We
should exploit that advantage before it disappears. Remember,
Longhorn is on the horizon. Windows 98 was an improvement over
Windows 95, and Windows 2000 and ME were improvements as well. Most
probably Windows XP followed that trend (I don't own a copy) and
Longhorn will as well.
The HUDMOF will be reliable.
Security... need I even mention that one? I am a paranoid
individual about my own system. I run a Linux Floppy Firewall on a
separate machine. IPTables has instructions to drop everything I do
not specifically request. The Windows machines I maintain in my
house are all behind this firewall as are the Linux boxes... and as
will be the Apple Newton when I get it hooked up. I don't use
wireless. Why give crooks an even break? Physical security consists
of locked doors and a former soldier with a shotgun.
A system that is designed to have separate user accounts is
definitely the way to fly, as far as I am concerned. I don't have
to worry about anyone getting into my email or deleting an
important document, and I don't have bookmarks for Bild Magazine,
Days of Our Lives, Pokemon, or any other websites I never visit
cluttering up my list. Those are in the home directories of other
users where they belong. Others might prefer a single user setup.
To each his own.
For those who prefer separate accounts for each user in the
household, passwords and separate home directories make for good
virtual neighbors. The HUDMOF should have multi-user capability
built-in... and iron-clad security.
Ease of installation/use. Now we have a problem. I've played
with Red Hat, Fedora, Mandrake, Debian, Gentoo, Knoppix, Storm,
DamnSmallLinux, and SmallLinux. Some of these distributions are
extremely easy to use, most notably DamnSmallLinux and Knoppix.
Others, most notably Gentoo and Debian require... hmmm... actual
intelligence.
Now, a true geek might say something like "to Hades with all
those GUI wimps who can't understand how to use fdisk to partition
a hard drive!" This is, however, short-sighted in the extreme.
"Those GUI wimps" are the ones who will be spending their
hard-earned dollars and/or valuable time. They need to be courted,
not snubbed.
Steve Jobs and Bill Gates both supplied a product that met a
demand. They are continuing to do so. That is how to put Linux on
the desktop, by supplying a demand, and a part of that demand is
going to be a certain amount of "hand-holding".
The Linux Community has been trying to sell Linux for more than
a decade now. Ralph Waldo Emerson once said: "Build a better
mousetrap and the public will beat a path to your door."
Dale Raby's Corollary to Ralph's Mousetrap: "If you have to beat
a path to the public's doors, there is something wrong with your
mousetrap."
So what might be wrong with our mousetrap? Why are people not
migrating in droves to an OS that is more reliable, more secure,
and being "sold" at an unbeatable price? What demand are we not
supplying that Bill Gates and Steve Jobs are?
Part of it is simple customer service, as noted earlier in this
article, or rather, the lack thereof, in the case of many Linux
distributions/binaries. Not to point any fingers regarding my
experiences in the early days... aber, sprechen Sie Deutsch?
I once called Apple about a MacIntosh 512K. I got to speak to an
actual person who listened to my questions. She explained that
Apple no longer stocked any parts or software for this fine
antique, but referred me to Sun Remarketing. Microsoft also
answered my questions politely and provided answers. Indeed, they
maintain a vast database of solutions to problems... even with
legacy hardware/software.
The HUDMOF should have first-rate customer service.
Even better than customer service would be quality control. If
your quality control is up to snuff, you don't have to worry about
customer service nearly as much. Ever had an application not do
what it is supposed to do? Quality control issue. Applications
should work as soon as they are installed with no tweaking. Many
Linux applications DO NOT work without some CLI voodoo.
Mutt is a prime example of a potentially great binary that
doesn't work as it should... "right out of the box". Before you can
even start, you have to create a .muttrc file. This is not
necessarily a bad thing as it allows the user to configure Mutt to
behave exactly as he wants it to. But would it be too much to ask
for a default ./muttrc with commented out instructions on what has
to be entered where?
Then there are other applications that must work with Mutt in
order to make a usable email package. You need to have Exim,
Sendmail, Fetchmail and/or other MTA up and properly configured on
your system in order to send and receive mail. Mutt documentation
does not help with these very much... and the user manuals for
these applications are definitely all in GeekSpeak.
Mutt is only being picked on as an example because of my
never-ending frustration with training it. Realistically, it will
not likely be found on many home user workstations. It will forever
be a geek's favorite pet. Compared with the ease of use built-in
with clients like Evolution, Sylpheed, and Pine, though, Mutt has
much ground to cover in this specific area.
I have a long-time friend who runs a dairy farm in North-Eastern
Wisconsin. He is still using a 486 PC running Windows 3.1. Why, one
might ask, has he not updated his system?
The answer is not lack of intelligence. He and I played chess on
the same high school team and took third at state. Considering the
fact that we had the national champions in our conference, that was
quite an accomplishment. He runs a profitable business with more in
assets than the average computer store... and at a much smaller
margin.
He is also not a Luddite. While you will find an occasional
piece of antique machinery on his farm, the ones in use every day
are modern and efficient. No Ford 9N tractor with a spark-ignition
engine pulling a 2-bottom plow, but rather an Allis-Chalmers
four-wheel-drive Diesel pulling a very large chisel plow. I
recently helped to install an air suspension seat in the
air-conditioned cab of one of these machines.
He also has on his farm several tools that date from his
father's time, his grand-father's time, and even his
great-grand-father's time. They range from hammers to shovels to
blacksmithing tools to tractors and other farm implements.
Why has the milking stool not been replaced? How 'bout a
carpenter's claw hammer? Maybe the Marlin model 1895 deer rifle in
44-40 WCF? Same reason the computer has not been replaced: they
just work.
Windows 3.1 and MS-DOS, despite their limitations, were
extremely robust operating systems. How often have you out there
picked up a roadside scrounge machine and upon bringing it home and
booting it up found Windows 3.1 happily rising to the occasion for
whatever use you had for it? I've never had a 3.1 machine die on
me... they all survived long enough to be either given away or
parted out. A large portion of the reason for this, I suspect, was
the fact that they were fairly simple and designed to run on a
small subset of hardware components.
The aforementioned farmer, Greg will come in late at night after
milking 80 cows, maybe delivering a calf or two, and fixing a
broken manure spreader outdoors in below freezing temperatures
while his wife holds the flashlight and hands him tools. It might
be that his foot hurts because a 1200 pound animal stepped on it.
Quite possibly he skinned his knuckles when a bolt-head broke off
in the wrench. Almost certainly he got a bill earlier in the mail
for fuel, feed, or veterinary services.
If, when he comes in late and wants to use his computer for some
reason, (or just as likely, Diane, the long-suffering, frost-bitten
farmer's wife) he wants to push a button, wait for it to boot, and
then have it do the task he has set for it with no complaining. He
isn't interested in excuses from a customer service rep or a
computer tech at the local distribution point. (My favorite was
always "Well, that's Windows!" ) He certainly does not want to be
bothered with having to learn C, Ruby, Perl or Python in order to
tweak some application and/or recompile a kernel from source.
Greg is a farmer. He knows how to get cows to produce milk. He
can deliver calves even when they come out backwards. We once
delivered one where the cow ended up with a prolapsed uterus and
had to hold the cow down until the vet arrived. (Go ahead and try
to hold a thousand pound plus animal down some day while her uterus
is hanging out on the ground! It is an enlightening experience to
anyone who thinks himself physically strong.) He knows how to plant
seeds and rotate crops. He knows about manure management. What? You
think manure manages itself? It's a commodity just like any other...
and it has to be managed such that it produces maximum fertilizer
and little, if any, runoff.
Now, I am sure that Greg could learn how to initiate all the
tricks that Linux can do with a command line on a Bourne Again
Shell. I am also sure he won't bother... he just doesn't have the
time or the inclination. I'm quite certain that the rest of us
would also rather that Greg keep on milking cows so that we don't
have to have a milk-cow in the back yard, (remember, manure
management on a small scale involves the use of a shovel and a
wheelbarrow) though if you want one, I'm sure that Greg will sell
you one!
Most home users are like Greg in some way or another. We use our
computers for web-browsing, email, word-processing, scheduling ,
and finance management. Each of us might have other tasks we put it
to... maybe video production, or, as in Greg's case, the lineage of
his herd.
Most of us also have children. Educational software has its
place, and there needs to be more of it ported for Linux. In the
main, however, the Internet will be supplying more and more
information for the education of our children.
Some children will take to a CLI and a green or amber screen
like a duck to water... but most of them will not. They'll want the
machine to do what they want it to, i.e.: allow them to compose a
book-report. They aren't going to be interested in learning how to
use Tex for that purpose.
One other difficulty has been buying a turn-key system. Now,
until recently, one could not just go out and buy a computer with
Linux installed on it. It is much easier to do so now than it once
was... case in point: machines marketed by Wal-Mart running Linare Linux
(for UNDER $200.00!) and IBM desktop machines offered with Red Hat Linux
installed.
In order for Linux to be the desktop machine of choice for
somebody like Greg the Dairy Farmer, it had better be available as
a turn-key system. He has never installed an operating system, and
really doesn't want to learn how. Thanks to IBM, Wal-mart, and a
few others, this is now a viable option. The HUDMOF will be a
turn-key system.
Updates are a practical necessity. Of late, one can avoid the
dependency nightmares I used to encounter by the use of tools like
YUM. To download updates, one should be able to click one button or
enter one simple command. The HUDMOF will have that feature built
in.
Likewise installing new applications should also be just that
easy. Nobody likes to hunt down obscure packages that may or may
not work properly with a certain flavor of Linux. Synaptic and Yum
are great tools for package installation... but they are not
complete. Try entering "YUM install newtonlink" into your command
line.
Fedora's latest set of binaries cannot always be downloaded from
certain mirrors because of compatibility problems. This really
sucks. Quality control, Fedora! Standards!
Much has been written in the trade journals regarding
"disk-less" systems. With the price of disk drives having huge
storage capacities falling like Michael Jackson's popularity, this
is not considered as necessary as it once was. It is still a viable
model, however.
For small businesses, one only need purchase a single "big
muscle" machine that acts as a file server, and runs applications.
This machine can be networked with lesser machines... disk-less
PC's or what are being called "thin clients"... and operated
remotely using SSH or any one of several other remote desktop
clients. The big muscle machine can run pretty much any
distribution that meets the prime needs; Red Hat or Fedora, Debian,
or name your favorite flavor. In the case of a home-user, the big
muscle machine may not even be necessary.
The disk-less machines in this model need not be anything
special, and any of them could serve the home user as the sole
element, though there is no real reason not to have a full-featured
machine in the basement other than expense. Now, obviously, one
need not have a hard drive for this "disk-less" machine, by
definition. One need not even have a CD/DVD drive. Modern flash
memory, and probably other technologies on the horizon can easily
handle the storage needs of most general users. Actual RAM is
getting cheaper by the minute, and it is already quite inexpensive
enough to easily build machines sporting more than a GB of memory.
This is quite enough to load the entire OS into a ramdisk. Can you
say "fast"?
The exception might be home video & sound production. Video
requires huge storage and processing capacity, and if the end
result is a DVD, then obviously a DVD-RW drive will be necessary.
Even these difficulties could be managed with remote storage, or
even home storage devices that are not in the machine.
If one can get away without any physical drives, one is well on
the way to an engineer's dream; a machine without moving parts.
There is no disk to spin up to speed, thus no extra power
requirements for that, nor is there the need for a CPU fan in many
cases or a cooling fan in the power supply. A simple radiator type
cooling system with heat fins like a Briggs & Stratton
lawn-mower engine has will suffice.
It is also quite evident that such a machine will be able to run
with very low power requirements. I no longer drive an '82 Olds
Ninety-Eight, I drive a '91 Ford Escort. I am considering
converting my house to run on LEDs for illumination. My RCA tube
radio is in the garage on a shelf while the solid-state electronic
devices have taken over. Anybody see a trend? Look for that trend
to continue.
The HUDMOF will be energy efficient.
Two Linux distributions really stand out in the disk-less model;
Knoppix, and DamnSmallLinux. Both of these distributions are
live-CD, Debian-based, and DamnSmallLinux could be considered a
"hack" of Knoppix, though the principal developer would dispute
that claim... and justifiably so. (Note: the latest Knoppix
distributions will have an option for live CD and another intended
for HD installation.)
One need only put the CD for each of them into the CD-ROM drive
and turn the "damn" thing on. In most cases, all hardware is
detected and configured properly during the initial boot process
with no digital complaining of any kind. The one issue that seems,
in my own experience, to be not so smooth with both of these
distributions is that of printer setup. All peripherals should be
detected and configured properly during the boot process... and
that includes the printer. Now, it is fairly unusual for me to
print anything these days, going paperless makes a lot of sense...
but that is another issue to be dealt with later.
Most PCs can run either of these distributions, though there are
greater memory requirements with Knoppix which is really quite
full-featured compared to DamnSmallLinux. Also, the latest release
of Knoppix will not run on some of my older hardware that the
earlier version will. If you only have basic needs for a disk-less
system, DSL will serve you quite well, and with a minimum of fuss.
If you want more packages get the latest Knoppix live CD
distribution.
Wyse makes one of their Winterm Thin Clients, the S50, available
running Wyse Linux V6. I have no experience with Thin Clients, and
am unsure if this machine would serve a home user or not. I suspect
that it would under many circumstances. One would have to provide
storage devices for it... either USB Iomega Zip drives or pen
drives, other storage media, or, even better, an on-line server in
a remote location equipped with high-end RAID devices, regular
backups, and security administration.
I recently cobbled up a system for a neighbor running
DamnSmallLinux on an IBM Pentium 100 machine. This machine has a
web browser, an email client, a word-processor, and several other
common applications. I installed the OS onto a hard drive I had
laying around, but I would not have needed that if it had an Ethernet
NIC installed. The machine will meet the needs of this man and his
family for years to come, I suspect, and it was already an obsolete
machine when delivered.
Had I wished, I could have made this a highly-efficient
disk-less system with multiple interface ports in a physical size
smaller than O'Reilly's book, Running Linux. As neither I nor my
neighbor has any money, I decided to recycle hardware I was no
longer using.
If a device could be built, in quantity, with item-specific
off-the-shelf components, perhaps with an OS either on an old-fashioned ROM
chip or a Flash memory module running a pared-down Linux kernel without
superfluous drivers that would no longer be necessary, the dream of a
computer in every home could at last be realized. Indeed, using cutting
edge hardware such as that produced by Gumstix, with further development, it is
conceivable that even a dirt-poor third-world slash-and-burn subsistence
farmer could one day afford to purchase and run a solar-powered machine to
expand his world and give some level of hope to his children that they
might not presently have.
All computers need some kind of monitor. The latest trend seems
to be LCD monitors, though many of us still use the old CRT
monitors. I even have one made by Zenith capable of full color,
amber, or green screens. CRT monitors are on the way out. They are
stable, inexpensive, and as they are a mature technology, quite
reliable. They take far too much power to operate, however, and
they are too large and heavy.
LCD monitors are less expensive to operate, but more expensive
to purchase initially. They can be made flat and take up far less
space on the desk top. One of their problems is that children love
to touch the screen... often damaging it. Autistic children
especially like to see the weird patterns when they push their
fingers against the screen.
A relatively recent technology is e-paper, which has to
potential to supplant all the previous display technologies... at
least until holographic display leaves the realm of science fiction
and joins us in the real word. Sony, among others, has been
developing this technology... and even using Linux in the
process.
The HUDMOF will use an e-paper display.
Printers are crude and need to be replaced as soon as possible.
There will, for the foreseeable future, still be a need for printed
documents, but this is more and more to soothe the worries of the
user than any other purpose. Printers are expensive to buy,
expensive to operate, expensive to repair, and none too reliable
due to the need to manipulate physical media with
electro-mechanical devices.
Within a very short time, comparatively speaking, there will no
longer be a demand for conventional printed matter. Newspapers and
magazines will change to a subscription web site. Books will become
e-books... though there will still be printed books for some time
to come.
The last letter I ever actually wrote and snail-mailed was
composed on a Tandy 600 and printed with an Epson dot-matrix
printer. This will give you some idea of how long ago that was.
Since that time, all my letters have been emailed. I almost never
print physical documents any longer. All my writing is handled
electronically and distributed that way as well. About the only
things I still print are shipping labels for books I sell on Ebay.
Now what was it I said about books in the previous paragraph?
The HUDMOF will eventually be without an interface for a
printer. The few occasions where a printed document is needed will
be supplied by on-line providers and snail-mailed out. The only
exception might be, for a while, shipping labels for packages.
Probably the HUDMOF will be a conglomerate of many features
mentioned here... and very likely several others I didn't mention.
It will be:
a turn-key system.
extremely reliable.
inexpensive.
networked.
simple to setup and use with readily available customer
support.
physically compact.
upgradeable to some degree.
efficient to run.
a hardware/software conglomeration.
without a printer port.
with an e-paper display.
Now, nobody has reached that ideal as of yet, but Sony, Wyse,
Knoppix, Gumstix, and DamnSmallLinux represent some of the best
implementations in this direction I have seen thus far. High end
bloat-ware from Microsoft running on innumerable hardware platforms
and even higher-end Apple products will not fit into this niche...
though if Apple were to revitalize development on the Newton OS,
and reduce the price, they might have something eventually. The
Newton was truly the closest to the HUDMOF that has ever been
actually produced... though the designers of the early Macs had the
right idea as well.
I now lay down the gauntlet and challenge the manufacturers.
This, I decree, will be the recipe for Linux conquering the
desktop... and making somebody somewhere richer than Gates. All.
You. Have. To. Do. Is. Build. It.
If you build it, they will come. IBM? Sony? Wyse? Gumstix? Klaus
Knopper? John Andrews? You guys all listening? Steve Jobs? Bill
Gates? Somebody build me a HUDMOF! Now just wait for the public to beat
the path to your door, for you have fixed the mousetrap.
Dale A. Raby is an ornery old man who started out on the original IBM PC back
in the day of running MS-DOS programs while convalescing in Ireland Army
Community Hospital and working for Captain James. Upon release from that
particular episode of his military service, he bought a Tandy 600 laptop
which still works after a fashion.
He picked up a more "modern" computer in 1998 and began publishing a general
interest webzine, The Green Bay Web. Quickly discovering that Wind0ws 95 was
about as reliable as a drunken driver with sleep deprivation, he made the
conversion to Linux over the protestations of every member of his household. He
now uses Fedora Core and since discovering Yum, has managed to keep his systems
relatively up to date.
Dale is a graduate of the University of Wisconsin-Green Bay with a background
in photography and print journalism. He is also a shade tree blacksmith who can
often be seen beating red-hot iron into shape in his driveway. He has been
known to use hammers and other Big Tools to "repair" uncooperative computers.
He is a conservative WASP, abhors political correctness, and... not to be too
cliché... enjoys hunting and shooting. Yes, that is a shotgun. No,
it is not a rifle. Yes, there is a difference.
Network Intrusion is an important aspect of network security. There's a
wide variety of Intrusion Detection Systems (IDSes) out there. While these
are extremely useful to gather information about an attack, or the
beginnings of an attack, e.g., a port scan, they can only inform us that
an attack has occurred. What would be really useful is a system that
actually blocks these attacks in real time. snort_inline is a system
designed to do just that.
This article describes how to compile, install, and test snort_inline.
snort_inline is a modification of the freely available snort package to
allow inspection and subsequent rejection of network packets, assuming
they meet certain predefined criteria. This constitutes an Intrusion
Prevention System (IPS), instead of just Intrusion Detection.
So, how does an IPS actually work? The system loads a large array of
signatures. These signatures take the form of a string of data
characteristic of some particular type of attack. When a data packet
enters the network, the IDS/IPS examines that data against its database
of signatures. If the data match, then the IDS/IPS takes appropriate
action. In the case of an IDS, the intrusion attempt will be logged,
whereas, in the case of an IPS, the system can drop the data packet, or
even sever the offending machine's connection.
To begin with, if you are running a Red Hat/Fedora system, you may need
the source code for your system's installed kernel. This may be true of
other systems, too; please see below for more information on why this is
required. It is also useful to have a Web server running, as this
article uses the Web service to validate snort_inline's behaviour. You
should not attempt this on a production server - at least not the first
time that you try this procedure.
snort_inline requires four packages to be installed in order to
configure it on a Fedora Core 3/4 box. This may be true of other systems,
too; please see below for more detail, later in the topic. We will assume
all files are downloaded into /home/snort/; please replace this with your
own download directory.
To begin with, you need the iptables source code. For reference, I used iptables-1.3.1
for this article. Once you have the source tarball, move it to
/usr/src/, untar it, cd into its tree, and run 'make' with the
install-devel option:
mv /home/snort/iptables-1.3.1.tar.tar /usr/src/
cd /usr/src
tar xjvf iptables-1.3.1.tar.tar
cd /usr/src/iptables-1.3.1
make install-devel
This will install the libipq library, allowing snort_inline to
communicate with iptables. iptables is responsible for accepting or
rejecting packets on the network interface.
Next, you need to build and install libnet, which is a high-level API
allowing snort to construct and inject packets into the network. The
version of libnet I used was libnet-1.0.2a,
as specified in snort_inline's docs. The newer version of libnet is, as
yet, incompatible with snort. Follow the instructions below, once you have
downloaded libnet-1.1.0.tar.gz:
mv /home/snort/libnet-1.0.2a.tar.gz /usr/src/
cd /usr/src
tar xzvf libnet-1.0.2a.tar.gz
cd /usr/src/Libnet-1.0.2a
./configure
make
make install
Providing there are no errors, you can proceed to the next section. If
at this stage you do find errors, you may need to install other
packages. The third package required is pcre, the Perl-Compatible
Regular Expressions library. For reference, I used pcre-6.1.tar.gz.
Once you have this file downloaded, follow the steps below, to install
pcre:
mv /home/snort/pcre-6.1.tar.gz /usr/src/
cd /usr/src
tar xzvf pcre-6.1.tar.gz
cd /usr/src/pcre-6.1
./configure
make
make install
Providing there are no errors, you can proceed to the next section.
Important: On Red Hat/Fedora systems, you will need to
perform an extra step before you can compile snort_inline. This has not
been tested on other systems, but, if your build fails later with the
error shown below...
In file included from /usr/include/linux/netfilter_ipv4/ip_queue.h:10,
from /usr/include/libipq.h:37,
from ../../src/inline.h:8,
from ../../src/snort.h:38,
from spo_alert_fast.c:51:
/usr/include/linux/if.h:59: redefinition of `struct ifmap'
/usr/include/linux/if.h:77: redefinition of `struct ifreq'
/usr/include/linux/if.h:126: redefinition of `struct ifconf'
make[3]: *** [spo_alert_fast.o] Error 1
make[3]: Leaving directory
`/usr/src/snort_inline-2.3.0-RC1/src/output-plugins'
make[2]: *** [all-recursive] Error 1
make[2]: Leaving directory `/usr/src/snort_inline-2.3.0-RC1/src'
make[1]: *** [all-recursive] Error 1
make[1]: Leaving directory `/usr/src/snort_inline-2.3.0-RC1'
make: *** [all] Error 2
...you may need to perform the corrective steps below: The build fails
because your glibc headers need to be updated [1], and this is why the kernel source is
required, as stated above. To temporarily fix this problem, please make the
following adjustments. This step assumes you have your kernel's source
installed, and that it resides in linux-2.6.9. This directory is likely to
change, depending on your kernel/distro version.
cd /usr/include
mv linux linux.orig
ln -s /usr/src/redhat/SOURCES/linux-2.6.9/include/linux/ linux
This step can always be reversed at a later date, should problems arise.
You now need to obtain the latest snort_inline package. For reference, I used
snort_inline-2.3.0-RC1.tar.gz
in this guide. Now, perform the steps outlined below.
mv /home/snort/snort_inline-2.3.0-RC1.tar.gz /usr/src/
cd /usr/src
tar xzvf snort_inline-2.3.0-RC1.tar.gz
cd snort_inline-2.3.0-RC1
./configure
make
make install
If there are no errors, then congratulations: You have just successfully
compiled and installed snort_inline.
Initial Configuration
We need to perform just a few more tweaks to the snort_inline
configuration, before it is ready to be run. To begin with, we need to
modify snort_inline's configuration file, making it point to the correct
path in order to obtain its rules. These rules tell snort_inline which
packets are malicious, and which are normal traffic. A quick workaround
is to move the classification and reference rule files to the rules
folder, like so:
Save the file and exit. Eventually, we are going to set up snort_inline
to run as a daemon, i.e., as a background process, although it is
perfectly conceivable that you may prefer to run it as a normal process.
In fact, to begin with, we won't be running it as a background service,
either: running non-daemon mode will let us view snort_inline's output,
and ensure that it is running as expected, without any errors. We must
now check /etc/snort_inline/snort_inline.conf to ensure that the rules
pathspec is as required below. Load the file in your favourite text
editor, and modify the line
var RULE_PATH /etc/snort_inline/drop_rules
to
var RULE_PATH /etc/snort_inline/rules
We now need to create a directory for snort_inline, to log the malicious
activity.
mkdir /var/log/snort_inline
By default, all traffic flowing to the kernel and back to user space must
be intercepted by snort_inline, to check for malicious network packets.
The kernel accomplishes this by pushing the data into a queue using the
ip_queue module. You can load ip_queue and verify its presence as follows:
modprobe ip_queue
lsmod | grep ip_queue
Providing you get see a line similar to the one below, ip_queue is
running and ready to interface with snort_inline.
ip_queue 9945 0
Next, iptables must be configured to send the traffic to ip_queue. You
accomplish that redirection using the following line, which redirects
all network packets destined for port 80 to the ip_queue module. If the
server is running a Web daemon, then this is an easy way to verify that
iptables is working. It is not recommended that you test this on a
production server, as your Web users WILL experience downtime.
iptables -I INPUT -p tcp --dport 80 -j QUEUE
If you now try browsing a Web site hosted on the server from a different
machine, you should notice that your browser hangs. This is because all
packets are being routed to the ip_queue, and are awaiting release by
iptables. Once snort_inline is running in background, all that traffic
will be released to the Web server, which will reply to the user's
request in the usual manner.
Testing snort_inline
The snort_inline installation can now be tested using the command below:
snort_inline should begin to process the packets being held in the
ip_queue, and hence resume normal network activity.
You should see some text flash by, and snort_inline should present a
message similar to:
__== Initialisation Complete ==__
If so, congratulations; snort_inline is now running. Try making that
connection via your Web browser again, and you should now see the Web
page you expected.
If you get a message similar to that below, then you forgot to load the
ip_queue module:
Reading from iptables
Running in IDS mode
Initializing Inline mode
InitInline: : Failed to send netlink message: Connection refused
Back on the snort_inline box, hit [ctrl+c] to end the current
snort_inline process. It is now time to add a test rule so that you can
see if snort_inline is actually working. In this example we are going to
drop all port 80 activity. To do this, you need to edit
/etc/snort_inline/rules/web-attacks.rules. Open it using your favourite
editor, and add the following line before the first "alert" statement,
but below the comments.
drop tcp any any -> any 80 (classtype:attempted-user; msg:"Port 80 connection initiated";)
Note that all other lines in this file start with the word "alert". This
means that snort_inline will only log and alert malicious packets: it
WILL NOT DROP them. This will be addressed in a short while. Re-run
snort_inline again with the following command:
Try once more to make that Web page connection. You may be required to
hit [ctrl+F5] to force page refresh and prevent your browser using a
cached version. Your request should now fail. Let us now quickly check
the logs, to see if snort_inline captured the "malicious attempt." Back
on the snort_inline box, hit [ctrl+c] once more to stop the snort_inline
process, and use the following command:
cat /var/log/snort_inline/snort_inline_full
You should be presented with an output sequence similar to the following.
If so, congratulations for the third time; snort_inline has successfully
used your rule to drop the packets. The string "Port 80 connection
Initiated" was the line you entered into web-attacks.rules, above. We
can also view a more-abridged version, by issuing the command
cat /var/log/snort_inline/snort_inline_fast
This should provide output similar to that shown below:
07/03-16:56:24.401627 [**] [1:0:0] Port 80 connection initiated [**] [Classification:
Attempted User Privilege Gain] [Priority: 1] {TCP} 192.168.16.68:2433 -> 192.168.16.7:80
07/03-16:56:27.341326 [**] [1:0:0] Port 80 connection initiated [**] [Classification:
Attempted User Privilege Gain] [Priority: 1] {TCP} 192.168.16.68:2433 -> 192.168.16.7:80
[root@localhost 20050625]#
In order to use snort_inline effectively, you must now remove the drop
rule inserted earlier. Edit the file
/etc/snort_inline/rules/web-attack.rules, and prepend # to the line you
added earlier, making;
drop tcp any any -> any 80 (classtype:attempted-user; msg:"Port 80 connection initiated";)
become
#drop tcp any any -> any 80 (classtype:attempted-user; msg:"Port 80 connection initiated";)
The last step is to modify all the rule files, turning alert rules into
drop rules. This can be done with a simple command, which must be typed
out exactly. If you are unsure, please make a backup of the rules folder
before you type this command, something that should be done as a matter
of practice.
cd /etc/snort_inline/rules/
for file in $(ls -1 *.rules)
do
sed -e 's:^alert:drop:g' ${file} > ${file}.new
mv ${file}.new ${file} -f
done
The last thing to do is run snort_inline as a daemon with the line
below, the only difference being the presence of the "-D":
Congratulations: you have just installed a working IPS. For
completeness's sake, the following instructions demonstrate how to stop
snort_inline and return your system to normal operation. Be advised that
you can alternatively accomplish this by simply rebooting the machine.
To stop snort, as it is now running in daemon mode, we need to find its
process ID number, and then issue a kill signal. To do this, run the
following command;
ps aux | grep snort_inline
This should present you with output similar to that below; the number we
are looking for is the "15705":
You can now go ahead and issue the kill command, as follows, where the
number following kill is the one obtained in the previous step.
kill 15705
This will exit snort, but ip_queue will still be receiving packets and
disrupting network traffic flow. As previously stated, in this example,
all port 80 traffic will be disabled. To re-enable this traffic, we must
remove the iptables rule with the following command:
iptables -D INPUT -p tcp --dport 80 -j QUEUE
Your server should now resume normal network activity on port 80.
Where Do We Go from Here?
This article has been a primer on the world of snort_inline. Next
month's piece will be dedicated to updating snort_inline's rules,
writing your own custom rules, and creating a snort_inline startup
script to enable it at boot-up.
[1] Rick Moen comments: I advise caution about fooling with
one's kernel headers. The old advice to do this by fetching new
kernel source and unpacking it to /usr/src/linux was always problematic,
and has now been obsoleted by better and less breakage-prone ways.
Short explanation: Your kernel header files used in compilation
need to always be compatible with the installed libc; therefore, you
should never fool with them, except by installing a new libc package
that furnishes new, matching headers.
Long explanation: Some kernel header files get invoked from locations
within /usr/include/linux, during compiles. Early in the history of
Linux, someone implemented the seemed-good-at-the-time notion of
not carrying such headers inside /usr/include/linux, but
rather -- to save disk space, perhaps? -- to symlink from there to those
same header files' locations within a kernel source code tree unpacked at
/usr/src/linux. Unfortunately, as you maintained your system over time,
newer kernel source trees' header files inevitably accumulated subtle
incompatibilities with the installed C library's entry points.
Eventually, compiles begin to fail for mysterious reasons.
The cause of this syndrome was understood early on, but the habit of
symlinking headers to /usr/src/linux locations became so ingrained
that it took until about 1999 to eradicate it from Linux
distributions, despite
Torvalds's repeated urgings and
exhaustive analysis
from the Answer Gang.
What the author calls "updating glibc headers" looks to this
commentator like an instance of the "symlink madness" Torvalds and others
tried for eight years to stamp out. I personally wouldn't go there. If
"the build fails" because of header problems, I'm betting you induced those
problems yourself through prior fooling with /usr/include/linux contents,
and your real cure is to stop doing that and let your system header files
remain the way your glibc package wrote them.
Pete has been programming since the age of 10 on an old Atari 800 XE.
Though he took an Acoustical Engineering degree from the world-renowned
ISVR in Southampton UK, the call of programming brought him back and he
has been working as a Web developer ever since. He uses both Linux and
Windows platforms. He still lives in the UK, and is currently living
happily with his wife.
Design Awareness: For Prince Henry and St. Brendan!
This was supposed to be a month in which I did
some navigating of my own (I'm currently awaiting a hiring decision which
will require me to, hopefully, relocate to the same port of call as the
editor of this very publication), so I thought we'd look at navigation on
the internet.
To get to this page, of course, you already had to click on a link from
the table of contents for this issue of Linux Gazette. That required
clicking on another link from the LG home page itself. That home page was
acquired either by a bookmark from within your browser, or a prompting link
displayed in an email.
These chains of links are so common now that we hardly notice them; I
get dozens of emails a week from friends with URLs embedded in them and, if
the context seems interesting, click on them without even reading the HTTP
address.
[ This is, of course, very dangerous behavior - but
it's very common as well. URLs can very easily be used as traps for the
unwary: e.g, the HTML version where the link text is completely different
from the link target; the "misspelled" URL that's one letter off from a
bank site - and LOOKS exactly like that bank site as well; the "trick" URL
such as
http://microsoft.com\important\free\download\no\really@3515134258
(most, but not all browsers these days are too smart for this; when opened
with, e.g. "links" or many version of Internet Explorer, the above will
take you to http://redhat.com); etc. Caveat
emptor... -- Ben ]
But it's when we finally arrive at a page whose contents we intend to
explore, that internet navigation really takes over. The distinction is so
significant that I'm going to assay some jargon creation here:
internavigation is what you do to get to a page or pages of
interest (clicking on URLs or icons or text links, in an email or on some
other site) in a particular site
intranavigation is what you do once you get there
These are examples of internavigation we see every day:
Hey, go check out the latest stuff at the Apple store!
Because of the commonly-accepted convention that blue text, especially
when underlined, is intended as a link to Somewhere
Else, we immediately roll our mouse over it and click without
pondering what will happen: if it's blue and/or it's underlined, it had
better take us somewhere when we click on it, right? But when
nothing happens (because the linkage is broken or the designer
underlined and/or made blue the text without intending it to be a link), we
get startled, and then usually get pissed off. (The little gloved hand icon
is a good indicator that something, blue or not, is a link, but it doesn't,
alas, work on all browsers and all operating systems and all pages.)
But now you've internavigated to a particular page, like this one, and
you want to move about, not only within the displayed page but among the
pages of the site.
Anchors are a simple way of navigating a single page; you will often see
the word Top or the phrases Back to
top or Top of page used to bring you back up from a
long descent into a page's content. (If you click any of these, you
will go to the top of the page.) Text linked to anchors can also
provide a way to move quickly to related material, whether on the same page
or another page.
The reason to return to the start of the page, of course, is to provide
access to navigation tools. Internavigation tools are typically
icons or text buttons, which represent links to pages within the site or on
other sites. Intranavigation tools, unfortunately, often look
exactly the same; making them look different (especially from tools that
take you out of the site) is tricky, but worthwhile.
Even if they don't have any graphic quality to them, linked-text tools
are really buttons (these are just examples and don't really go anywhere,
so don't bother clicking them, even though they're blue and
underlined):
Home
About us
Contact us
Legalisms
With some modest formatting, they begin to look more like 'real'
navigation tools (don't click these either):
Home
About us
Contact us
Legalisms
But what should they look like? Are they part of the 'design', or are
they just HTML-generated buttons like these?
The other problem that comes up is, where to put them? Do you just run
them across the top of the page, as these might be? What then happens when
you want to add more (or, more properly, the client wants you to add more,
a lot more, like maybe a dozen more)? Do you make them smaller? Run them in
two lines? (Don't laugh, you'll see that farther along.)
Or do you start to stack them down the left side of the page? If so,
should they be in their own frame, so that they always stay visible as you
scroll down the page?
Home
About us
Contact us
Legalisms
A non-scrolling frame has its own awkwardness, of course, and seems to
have fallen out of favor with many designers. But a list of buttons down
the left side is almost a universal solution these days, as shown in these
(half-size) examples (none of which are in non-scrolling frames, by the
way):
The same issues apply to navigation bars at the top of the page, as shown in these examples (see, two lines!):
Running out of room everywhere else, sites are beginning to wrestle with
navigation at the bottom of the page:
But for a look at some really exciting navigation issues, let's
try weather.com (click here to go to a full-size version
or to the actual
page):
Now there's some visual complication! You've got (roughly, from
the top) blue underlined links, button links, a data-entry box, a pop-up
requiring a 'go' button, a reversed underlined page link, radio buttons, a
selection list, a clickable image, blue underlined links, another selection
list, another date-entry box with its 'go' button, blue underlined links in
an unnumbered list, blue underlined links with clickable images, yet more
blue underlined links, a data-entry search box with yet another 'go'
button, and bottom navigation using many black underlined links, reversed
underlined links, and blue underlined (though not in blue, just to be
different) links. Whew.
This shows what we've grown accustomed to as 'conventions', even for
links to other pages: traditional (and now almost quaint) blue underlined
text, buttons, images, and text of varying colors and underlining. You can
tout your ability to do CSS and 'handcoding' all you want, but if you can't
decide what a link should look like better than that, I don't want to hear
about it.
Oddly enough, we've gotten so used to information overload that (most of
the time) we can focus on what's important to us, even in a page as complex
as this one. On the other hand, why should we have to? Why does
every page have to have access to every other possible page in the site? By
my count, there are links to over one hundred other internal pages on that
one weather.com page. That's like putting the entire table of contents on
every page of a book, just in case...
If the two header bars shown above, after being carefully introduced on
an earlier page, were merely used as links at the bottom to 'jump' pages
carrying a list of the 80-odd other pages they represent, not only would it
save a lot of page room (hey, every bit helps when you're paying for
transmission or waiting for bandwidth), but reduce eye irritation
immensely.
Okay, we're looked at several 'professional' web layouts, and seen a few
constants:
navigation is difficult to keep simple while still allowing access to a broad and deep site
navigation can (though perhaps it shouldn't) be found all across a given page
navigation tools have lost whatever conventions the web started with, and can look like anything on a page
My advice for internavigation and intranavigation tools is
this: determine your internal conventions early and stick to
them.
Some rules, for those who like rules:
distinguish between internavigation tools (you're going to some
other site entirely if you click here or
click www.somewhere-else.com) and
intranavigation tools (you're going to some other page on this site
if you click here and you're going
somewhere else on this page if you click here) on the landing page (and as many 'early'
pages as necessary to cover all eventualities) and never vary them
if blue underlined text defines a link for you, make it so all the time, design be damned
if you must break that rule, announce it some other way: "Click here to go Somewhere Else"
keep buttons to themselves
don't sprinkle navigation all across the page; the user got used to
where you put it on the early landing pages
don't make the user scroll a long way up and down (or side to side) to
get to the buttons; if your pages have to be really long to fit your
content, park an occasional Top button that takes
them back to the tool area
make buttons look like buttons; most HTML applications have button
generators, but you can make your own in GIMP or Photoshop just as easily,
with better results. Using words (even if defined early on as above) as
buttons without some 'button-ness' to them only makes the user work harder;
the standard words-in-a-line solution like this one is better than nothing,
but just barely (I think it's lazy, but it might be necessary in a big site
with constant changes):
you can't have too many ways for the user to get where they want to go;
if you have images next to linked text, link the images, too. (Banging away
at an image that represents where they want to go, with nothing happening
as a result, sends users elsewhere in a hurry.) But if you have text next
to linked images, be sure to link some portion of the text as well; some
users like images and some users like text, so give them both.
put a "Click here to go to the beautiful and
helpful map of this site" link or button (and make sure the
user knows what it is if you use a button; a cute little map image is fine
if you defined it earlier) on every page. A properly designed site map will
quickly solve any user confusion and reduce the number of navigational
tools you need on every page
So, you hate rules. If you're not going to follow any of my rules, make
damn sure you define your links early on: "Links on this site are
indicated by flashing green elves and/or tiny red bullets and/or photos of
my dog". (Make sure you have good behavior tracking software
installed, too, so you can watch users departing your site at high
velocity...) If you're creating some totally 'personal' site, it may not
matter. If you expect users to enjoy using your site, buy things from you,
tell their friends about you (you have heard of viral marketing, right?),
and come back again, better come up with your own rules that work.
Remember, all anyone expects of your site is exactly what they want
to do, not what your design wants them to do. Make it easy for them.
If you've gotten this far, you're probably wondering about the title of
this month's column. Besides being a swipe of a line from one of my
favorite speeches in Shakespeare ("...for Harry, England, and Saint
George!" from the battlefield scene in Henry V), it
recognizes two people, either of whom ought to be the patron saint
of web designers, Prince Henry the Navigator and St. Brendan the Navigator.
(Are we seeing a navigation theme here?)
Prince Henry, the son of the King of Portugal in the
fifteenth century, organized and bankrolled numerous expeditions which
expanded both Portuguese influence and maritime knowledge along the western
edge of Africa, ultimately leading to Bartolomeu Dia's voyage at the start
of the sixteenth century that finally rounded the Cape of Good Hope and
opened the ocean route to the riches of the East.
St. Brendan was, if the stories are true (and if you
think they're not, I suggest you have some more whisky until you do), the
first person to reach the Western Hemisphere from Europe in the sixth
century (well before that other guy whose Day we celebrate merely for doing
it a thousand years later), traveling west in a hide boat from Ireland. He
is the patron saint of navigators, and with the right PR behind him
might well have become the patron saint of the internet instead of this
guy:
St. Isidore, the front-runner in the race to become the
saint's medal on the dashboard of the Web,
beating out the Archangel Gabriel and St. Bernadine of Siena (the patron
saint of public relations) and St. Rita of Cascia (the patron saint of
impossible causes) in a proposal to the Vatican by an all-Italian internet organization. (Go
figure why they like some Italian guy over a nice Irish boy like St.
Brendan...)
No matter who ends up being the patron saint of your internet, if you
want me to write about some specific aspect of design, you gotta email me
and let me know.
I started doing graphic design in junior high school, when it was still
the Dark Ages of technology. Bill Gates and Steve Jobs were both eleven
years old, and the state of the art was typing copy on Gestetner masters.
I've worked on every new technology since, but I still own an X-acto knife
and know how to use it.
I've been a freelancer, and worked in advertising agencies, printing
companies, publishing houses, and marketing organizations in major
corporations. I also did a dozen years [1985-1997] at Apple Computer; my
first Macintosh was a Lisa with an astounding 1MB of memory, and my current
one is a Cube with a flat screen.
I've had a website up since 1997, and created my latest one in 2004. I'm
still, painfully, learning how web design is different from, but not
necessarily better than, print.
Part computer programmer, part cartoonist, part Mars Bar. At night, he runs
around in a pair of colorful tights fighting criminals. During the day... well,
he just runs around. He eats when he's hungry and sleeps when he's sleepy.
The Ecol comic strip is written for escomposlinux.org (ECOL), the web site that
supports es.comp.os.linux, the Spanish USENET newsgroup for Linux. The
strips are drawn in Spanish and then translated to English by the author.
These images are scaled down to minimize horizontal scrolling.
To see a panel in all its clarity, click on it.
These cartoons are copyright Javier Malonda. They may be copied,
linked or distributed by any means. However, you may not distribute
modifications. If you link to a cartoon, please notify Javier, who would appreciate
hearing from you.
Shawn is an American spelling of Sean (which is not an English name, by
the way, it's Irish. It does appear in Scotland, but IIRC, the Gaelic
version is Ian).
[Sluggo]
Ian means Sean??? I thought Ian meant John. Or does Sean mean John too?
The latter. Sean is an Irish mispronunciation of John
[Breen]
Bingo.
Also Seamus == Hamish == James.
Give the man a "Do Unspeakable Things To Me, I'm Irish (For a Given
Value of 'Irish')" t-shirt!
[Breen]
Here in the States, my surname is always considered Irish. I'm well
aware that in Ireland they'll tell you that it's English.
Nah. I thought it was Irish.
[Breen]
It's Anglo-Norman in origin -- Moleyns (as in Moulin) making it a
cognate of Miller.
[Sluggo]
Is that like the "My weiner is lucky" T-shirts that appeared right before
St Patrick's Day?
A friend in Dublin sent me a great St Patrick's Day card. It showed two
businessmen with shamrocks and green and other "lucky" things all over
their briefcases and suits, but they had "bah humbug!" expressions in
spite of that.
Note: yanks don't send St Patrick's Day cards. At least none that I've
ever heard of.
Um... that's the first time I've ever heard of a St. Patrick's Day card.
Will those Hallmark fiends stop at nothing?
The article talks mostly about the cultural differences between Unix and
Windows; it says Raymond gets this wrong because he doesn't understand
Windows culture, but still recommends the book for its general insights.
'I have heard economists claim that Silicon Valley could never be
recreated in, say, France, because the French culture puts such a high
penalty on failure that entrepreneurs are not willing to risk it. Maybe
the same thing is true of Linux: it may never be a desktop operating
system because the culture values things which prevent it. OS X is the
proof: Apple finally created Unix for Aunt Marge, but only because the
engineers and managers at Apple were firmly of the end-user culture (which
I've been imperialistically calling "the Windows Culture" even though
historically it originated at Apple). They rejected the Unix culture's
fundamental norm of programmer-centricity. They even renamed core
directories -- heretical! -- to use common English words like
"applications" and "library" instead of "bin" and "lib."'
[Rick]
Yeah, they're not people who senselessly put up with endless churn and
mind-numbing complexity at the behest of a monopolist vendor; they're
just plain folks working to help Aunt Marge in contrast to those
luftmenschen Unix (especially Linux) people who aspire to actually be in
charge of their computing. Joel and Co. are so tragically
misunderstood I'm getting all misty-eyed, just thinking about it.
Yeah, Aunt Marge will never be able to figure out her TiVo or use
Google, right, Joel?
You'll have to wade through a large amount of tedious and irrelevant
argumentum ad hominem, probably included as filler because Spolsky has
otherwise so little to say -- and, of course, none of even that residuum
about (in contrast to Raymond's work) the key issue of where control
resides, as Spolsky's crowd gave that up long ago without much thought.
I don't really mind the four minutes I wasted on that review, but in an
ideal world I'd really rather have them back.
[Jimmy]
Um... where? I see a lot of general arguments against the Unix
approach, but not against Raymond personally. The closest to an ad
hominem argument I saw was this:
"Whenever he opens his mouth about Windows he tends to show that his
knowledge of Windows programming comes mostly from reading newspapers,
not from actual Windows programming. That's OK; he's not a Windows
programmer; we'll forgive that."
and, uh... that's true from what I remember of the text in question.
"NT has file attributes in some of its file system types. They are
used in a restricted way, to implement access-control lists on some
file systems, and don't affect development style very much."
Umm.... that's kinda true, for given values of 'true'.
NT doesn't use attributes in the POSIX sense, it uses separate file
streams. Each file on NTFS is more like its own directory, and
arbitrary streams can be added to each file without restriction
(xattrs on Linux are restricted to 64k, BTW). Heck, they could even
add automatic versioning and really show NT's VMS roots if they
wanted.
"Most programs cannot be scripted at all. Programs rely on complex,
fragile remote procedure call (RPC) methods to communicate with each
other, a rich source of bugs."
Again, true for a given value of true.
Most programs can't be scripted in the Unix way - by parsing the
output - but can be scripted using OLE Automation. This is where that
RPC confusion comes in: it's actually a C++ vtable on the local
machine, with an extra part that describes the type information for
each function (like Java's reflection API), which removes the need to
write a wrapper for each programming language as you have to do in
Unix land. Windows comes with a DCE RPC implementation, and will
automatically marshal OLE interfaces across RPC for free if you decide
to call a remote machine, but otherwise there is no overhead for
compiled languages, and a little for interpreted.
If the amount of times Unix has been cloned is a testament to how good
an idea it was, bear in mind that COM has been cloned several times
(OOo's UNO, Mozilla's XPCOM, GNOME's Bonobo, KDE's (now discarded)
original component system, etc.)
[Rick]
1. Otherwise irrelevant swipe about "idiotarianism", a term
Raymond had briefly attempted to popularise in the context of
his politics blog.
2. Reference to "the frequently controversial Eric S. Raymond".
Note: Passive-aggressives in the technical community have been
lately falling back on the term "controversial" to denote
someone whom you wish to suggest is somehow unsuitable and
doubtful without actually presenting any honest argument as
to why. I caught a business-school professor from San Jose
State University recently trying to pull that bit of gutter
rhetoric on the OSI license-discuss mailing list against
outgoing OSI general counsel Lawrence Rosen. It was
a disreputable bit of trickery there, and it is here, too.
3. The juvenile, thrown-in inclusion of a hyperlink to Raymond's 1999
"Surprised by Wealth" slightly inarticulate burblings about
(temporarily, as it turns out) having paper-only winnings in
the stock market from the VA Linux Systems IPO. Even the
Slashdot trolls eventually got tired of cruelly waving the
"Gee, you thought you were going to get rich, huh?" line at
Raymond, but Spolsky hasn't.
All of that gratuitous personal nastiness formed part of what Spolsky
lead with in his initial paragraphs. You might not have noticed it,
but I did -- and it both distracted from the distinctly limited merits
of his review's real content and sufficed to convince me that the
man's a raving jerk.
[Kapil]
The analogy Japan<->
America = Windows/Mac<->
Unix is flawed.
There are cultural differences between the users for whom the
Mac/Windows/Gnome/KDE folks design interfaces and the users for whom
the Unix interface is designed.
However, it is possible and indeed imperative(*) for users of the first
kind (whom Spolsky calls non-programmers) to make the transition (at
their own pace) to the users of the second kind (programmers). (**)
The difference between Gnome/KDE and Windows is that in the latter
case the interface puts up barriers to this transition.(***)
(*) But there is no such imperative for people from one part of the
world to adapt/adopt food habits from another part of the world.
(**) The logic of the world as it currently works is that those who do
not (slowly but) steadily improve their understanding/usage of the tools
they use will soon become incapable.
(***) I cannot decide exactly where to put Mac OS X.
[Jimmy]
I have to admit here that I didn't bother following the links from
that paragraph, and going by the text, I thought it was a favourable
review:
"The frequently controversial Eric S. Raymond has just written a long
book about Unix programming called The Art of UNIX Programming
exploring his own culture in great detail."
[snip cultural differences....]
"on the whole, the book is so full of incredibly interesting insight
into so many aspects of programming that I'm willing to hold my nose
during the rare smelly ideological rants because there's so much to
learn about universal ideals from the rest of the book. Indeed I would
recommend this book to developers of any culture in any platform with
any goals, because so many of the values which it trumpets are
universal."
Aside from your third point, though, I think you're reading a bit too
much into it: the guy is writing for an audience who have either not
heard of Raymond, or who would most likely have an unfavourable
impression that he's referring to -- "Don't be put off the book
because of its author".
[Rick]
That's a generous interpretation, and it speaks well for you, but not
for Spolsky.
All of those three points, however, have been popular standbys of a
certain Slashdot-type ad hominem squad that's been showing up --
invariably relying on anonymous postings -- in pretty much any
discussion of Raymond, his writings, or his software or the last seven
or eight years: Spolsky gives every appearance of having cribbed his
"amusing", take-the-subject-down-a-peg-or-two references directly from
the gossipers.
Those gossipers had a field day with Raymond for promoting the
"idiotarian" concept on his politics blog, and then more so when he made
the mistake of listing that in the Jargon File (which entry he later
removed, upon reflection). And there's no conceivable reason to cite
that in a book review, other than to serve as a personal swipe.
[Jimmy]
OK, I'm conviced, especially since I went back to the article and
noticed the date.
While we're on the topic, I went by Wikipedia's article
(http://en.wikipedia.org/wiki/Eric_S._Raymond) after I sent that last
mail, my PC crashed, I went back, and... the section titled
'Criticism' had changed to 'Trivia' -- it seems there has been a very
slow edit war going on over the past few days.
[John]
Attacks of ESR aside, one slightly off-color aspect I noticed in the
review was a cited quote from an exec at Red Hat, taken from Nov 2003,
which stated that Linux was not yet ready to be considered as being on
equal footing with that other OS in the regard of ease of install and
use by non-tech savvy types.
...............
So here we are, 20 years after Unix developers started trying to
paint a good user interface on their systems, and we're still at
the point where the CEO of the biggest Linux vendor is telling
people that home users should just use Windows.
...............
I followed his link to the source of the quote, and saw that it was
published in Nov 2003, and that the article went on to say:
...............
Szulik gave an example of his 90-year-old father going to a
local retailer in order to purchase a computer with Linux: "We
know painfully well what happens. He will try to get it
installed and either doesn't have a positive experience or
puts a lot of pressure on your support systems," he said.
However, Szulik expects Linux to be ready in a couple of years
after it has had time to mature.
...............
I don't mean to assert that the more ubiquitous platform doesn't maintain
the advantage for wide OEM support, but depending on the apps that the
user is going to run, the gap has been narrowing steadily over time, and
for an ever increasing number of home users, Linux makes a very adequate
replacement for MSW.
The citation of that quote also seems a bit misleading, in that it's quite
easy to assume that it was more contemporaneous, rather than nearly two
years old, and in the context of technological advances, nearly two years
is a long time.
[Jimmy]
Erm... that review was published a month after the quote in question.
(As I said in my last mail in this thread, I didn't notice the date
either
.
[John]
Oops, missed it both places - could be time for the semi-annual cleaning
of the spectacles.
I say X-GOOGLE-VERHOEVEN and thought "what the heck is that?". I googled
(Admittedly not a very good way to find something if this a huge
conspiracy. <grin>
for it on the web and on Google groups, but that
only turned up mailing list archive posts where people were posting the
output of fetchmail -v in an effort to get their mail working.
My next step was to see if the extension introducted any obviously named
commands:
I tried several other permutations: X-GOOGLE, GOOGLE, GOOGLE-VERHOEVEN.
Each one returned the same error code.
So I wonder: What is this thing? Is it just some tag saying "Yes, this
is Google's mail service"?
[Sluggo]
Should've yahoo'd or msn'd it. That'll show them.
Actually, I tried Yahoo, which didn't return any hits. I'd forgotten
about MSN. It didn't return anything either. It's indicative of
something (Google's massive market share? Forgetfulness? I don't
know.) that I couldn't think of any non-Google search engines other than
Yahoo.
[Ben]
It's that X-GOOGLE-VERHOEVEN extension. It sets a default state for
search_engine_lookup() in your brain... you're doomed, doomed I tell
you.
[Jimmy]
Well, they are the only search engine with a moon mapping facility
(http://moon.google.com - today's the anniversary of the first manned
moon landing, but you guys knew that, right?)
[Breen]
I certainly did. (You have zoomed all the way in on google's moon,
right?)
[Jimmy]
Nah, I'm on dial-up. I'll be sure to do so tomorrow when I get a
chance to go to a 'net cafe, but I think I can guess what I'll see.
Heather pointed me to your site, including your photos.
[Sluggo]
Are you going to bait us all and not give us the URL?
Nah, just you. I emailed the URL to every single other person on
the list privately - in fact, everyone else in the world - just to leave
you out of the loop and watch you do this jumping up and down act; it's
far too amusing to miss. So, everybody except you is in on the joke.
Perhaps we'll all take pity on you if you do it long enough.
[Sluggo]
Grumble, what do you expect from a guy who lives on a boat so he can make
a fast getaway anytime.
"Fast getaway". On a 37' sailboat. Riiiight.
FYI:
Average speed for non-planing hulls = sqrt(waterline_length)
Top speed -"- : sqrt(waterline_length) * ~1.3
Ulysses' LWL: ~32 feet.
HINT: Sailboats do not have afterburners, ramscoops, or braking jets.
Reentry speeds are whatever the crane operator feels is safe - i.e.,
somewhere around 1 ft./minute (no heat-resistant tiles required.) Andy
Green and Thrust SSC have nothing to fear from wind-driven machines, and
Chuck Yeager in his X-1 never got to experience being outrun and
outmaneuvered by a schooner or a yawl.
We do, however, make trans-oceanic passages - something that 99% of
powerboaters will never be able to do aboard their boat - and burn zero
to minimal fuel in the process. We also don't have to rely on
bad-tempered machinery that could leave us stranded at any second.
There's also the fact that wind is free... and with the cost of gas
nowadays, that speaks to a lot of people.
[Sluggo]
Not a peep from you about hurricanes this time. I take it you were
unaffected?
I'll be sure to let you know if one of them kills me.
...
Eventually.
[Sluggo]
Or is your computer sending preprogrammed posthumous
messages?
[Sluggo]
On a similar line, from another James Hogan book Voyage from Yesteryear ,
chapter 11. A human is talking to a robot.
...............
-- What kind of machine are you? I mean, can you think like a person? Do
you know who you are?
-- Suppose I said I could. Would that tell you anything?
-- I guess not. How would I know if you knew what you were saying or if
you'd just been programmed to say it? There's no way of telling the
difference.
-- Then is there any difference?
Driscoll frowned, thought about it, then dismissed it with a shake of his
head.
...............
Mike, if you're trying to tell us a) that you're a robot, and b) that we
won't be able to tell the difference, you're way behind the curve. I
mean, look at that mechanistic Python language thing you use: obviously
robot-only fare. I mean, good *grief!* The thing treats whitespace as
if it was significant. What else would you have to know to say "Yep,
this guy is a Venusian Zombie Killer Robot - run for your lives!"
What a lovely,
perfectly English cottage (including the satellite dish!) - and what a
magnificently malevolent-looking cat! I hope you don't mind me keeping a
copy of that pic; he represents a certain visually-unambiguous ideal.
))
[Thomas]
Hehehe. Not at all, you're quite welcome. It's a she, as it happens.
"Mildred" is her name. She likes to hunt rabbits, mice, birds, and
squirrels. I have seen twice now, while I have been here, two
de-headed squirrels. :/ Yuck.
She isn't ferocious. She meaows
a lot, and takes a shining to me, as all animals seem to do. She has
sharp claws though, so watch out.
Continuing on the photo theme, I have more of the coast (a mere mile
and a half walk away, across the farmland) that I will try and upload
to Heather -- but I am putting together a more coherent website with
these images on, providing a running commentary. I'm hoping Mike Orr
will appreciate it as well. I've hopefully done him a favour (I do not
mean for it to be patronising or condescending in anyway) and taken a
picture of a Caravan and a static-caravan for him to compare. (Mike
knows what I'm rabbitting on about.)
[Sluggo]
I've already forgotten what a static-caravan is. A trailer that's not
built to be moved very often?
(This was from a word discussion. Apparently a trailer is called a
caravan in England. Here a caravan is a mode of travel ("several
vehicles travelling together"), not a type of vehicle. The Dodge
Caravan notwithstanding.
http://www.dodge.com/caravan
[Thomas]
This connection I'm on now relies on tin cans,
string, and some sort of goat sacrifice...
[Brian]
That it requires goat sacrifice is one thing, that it requires "some
sort" of goat sacrifice implies more than one type of goat sacrifice
possibly necessary for certain 'net connections through BT (one
presumes). That you KNOW that there's more than one type of goat
sacrifice has me slightly concerned.
.brian (who's also glad to know you weren't in the wrong place that day...)
I find that curried goat makes for quite a good sacrifice - especially
if I'm the one being sacrificed to. A touch of scotch bonnet sauce and
perhaps a squeeze of "sower orange", and it will ameliorate my wrath and
charm my savage breast...
[Thomas]
Ah, a man that speaks from experience.
[Thomas]
The route to the sea also follows the river Brad, which has lots of
fish in. I want to go fishing now.
[Sluggo]
Tell Brad hi when you meet it. Britian has such interesting place
names, starting with the river Thames. And in bonnie Scotland: Lost,
Wick, Tongue, John o' Groats, Thurso. Oh, and here's an interesting
one, Baile an Or. (Is that the Gold Town? Or something named after me?
BTW, Vancouver has a skytrain station called Braid.
[Brian]
That must have been one wicked track design...
[Jimmy]
Heh. You need to get a copy of "The Meaning of Liff" by Douglas Adams
and... erm... someone else. They took several place names from around
Britain and provided definitions for them
A lurid facial bruise which everyone politely omits to mention because
it's obvious that you had a punch-up with your spouse last night - but
which was actually caused by walking into a door. It is useless to
volunteer the true explanation because nobody will believe it.
...............
[Rick]
Which reminds me: My sweetie Deirdre Saoirse Moen and I will be
visiting the place "The Meaning of Liff" defines thus...
...............
GLASGOW (n.)
The feeling of infinite sadness engendered when walking through a place
filled with happy people fifteen years younger than yourself.
...............
via a very brief sojourn in the familiar spot alluded to inside here...
...............
AIRD OF SLEAT (n. archaic)
Ancient Scottish curse placed from afar on the stretch of land now
occupied by Heathrow Airport.
Alas, we will not have time to wander elsewhere in the UK.
[Sluggo]
Or as Forsyth's film That Sinking Feeling , which is set in Glasgow, says:
...............
The characters in this film are entirely fictitious.
There is no such place as Glasgow.
...............
The film with that memorable line, "There must be something more to life
than committing suicide."
The flash in the pan has fizzled out...
From Rick Moen
Quoting Benjamin A. Okopnik (ben@linuxgazette.net):
> It's *possible* that [foo] acted in what he thought was good faith.
(Name elided from the quotation to stress that I'm mounting the soapbox
to make a general point that I hope will enligh^Wentertain.)
It costs nothing to postulate good faith about people one is talking
about; in my opinion doing so is both good manners and superior
tactics.
In the hypothetical edge case of having stone-hard evidence, ready to
post and likely to be understood, it is still usually much more
damning to cite the evidence without comment, and let listeners reach
obvious conclusions on their own. Why? Because of an odd rhetorical
effect.
If I tell you "X is an irredeemable jerk, and I'm going to prove it to you",
you will tend to unconsciously set your mind to resist the sales pitch
and dream up any possible reasons why you might remain unpersuaded.
It's human nature; if we're pushed, we lean the other way, out of habit.
By contrast, if I just start talking in a matter-of-fact fashion without
apparent axe-grinding about various uncontested facts about X's doings,
and you're moved to comment "What a wanker!", you'll tend to hold that
conviction pretty firmly because (or so you think) you arrived at it on
your own. In fact, you might dig in and start trying to convince me
*I'm* being too kind.
So, next time you see me being nice about someone, or even protesting
other people's too-hasty condemnation of him, please remember that
generosity of spirit might have nothing to do with it: It might be a
devilishly clever Machiavellian intrigue in disguise.
Sent in my usability article. I finished it last night but my Internet
access went kaput. Both the ISP and Qwest said everything's fine. I'm
wondering if it's a bad modem or bad Ethernet card. The light on the
Ethernet card and modem blinks like there's no tomorrow, even after I turn
the computer off, until I unplug it. Some new kind of hardware hackery?
"Do you know what your Ethernet card is doing?"
[Heather]
It's 10 pm, do you know where all 10 of your Mb are...
So I'll be semi-offline for a while. If you need to contact me for
anything, call [phone number].
Song of the month: "On Any Other Day", The Police
...............
My wife has burned the scrambled eggs
The dog just pissed my leg
My teenage daughter ran away
My fine young son has turned out gay
... AND IT WOULD BE OKAY ON ANY OTHER DAY!!!
...............
[Jimmy]
And quote of the day, from Mil Millington's mailing list: "Fiona Walker
is the only best-selling romantic novelist who has ever started talking
to me in a bar about buying horse sperm off the Internet. (That's not
really relevant, but I sensed you'd what (sic) to know it anyway.)"
[Heather]
The fortune cookie of the moment was the lyrics from Dark Side of the Moon.
"...as a matter of fact, it's all dark."
Heather "still crunching and munching yes I know we're late" grabs my
white-rabbit type hat and races back down the rabbithole again.
I had to go to the library to upload the article. Since I didn't have a
floppy drive I was about to buy a USB stick, then I thought, "My camera is
a mass storage device. Maybe I can upload an arbitrary file to it." And
it worked.
[Jimmy]
Yeah, I've done that with my camera, and the smart media card from my
brother's portastudio. (Which reminds me -- I have to replace that.
Turns out these things don't cope well with power failure
[Ben]
The Geek Resurgens, ne plus ultra! Can't kill 'im with a stick!
Well done, Mike. Me, I'd have had to wind a bunch of wire on some iron
cores, and hope that the library computer would accept a pair of car
battery clamps as serial input.
[Jimmy]
And heck, if the librarians have a problem with that, they can also
double as a means of persuasion.
I finally got the chance to read this months edition of the LG and saw
this interesting discussion about Playboy hosting mirror.
I had noticed it last year when I was trying to download something off
cpan. I took a screenshot of it since I didn't expect anyone to believe
me without it. If you are curious here's a link to that blog entry:
[Jimmy]
[ Sharp intake of breath ]
You mean it set your desktop background for you too? That's what I call service!
Yup. If you want a copy of the background let me know.
BTW if you trying to get to the above site right now, you won't get
through. 'cause some unknown reason my LVS (Linux Virtual Server)
decided to reset to its default blank settings. I am trying to get in
touch with the Tech Support but so far havn't heard anything yet.
So As a side note, does anyone know any reliable web hosting service? I
want PHP, MySQL, Perl on the server with SSH access and a decent
transfer limit. If anyone knows a good hosting service let me know.
Naive comparison is a real problem, and even things that seem to be
"apples to apples" -- say, a comparison between the vendor-announced
vulnerability counts of Microsoft Windows XP SP1 vs. Redhat Linux 9 --
fall apart the moment you compare what's in the box for both. XPSP1
ships with no databases, while Redhat ships with at least MySQL and
PostgreSQL. Should Redhat be penalized for warning customers of
potential problems that might be experienced on their platform,
despite the fact that they didn't even write the software to begin
with? When Oracle on XP has a vulnerability, Microsoft does not need
to put out an advisory, instead Oracle does. Should Microsoft be
referred to as a more secure platform because standard disclosure
policies do not extend to announcing problems in software acquired
entirely from a third party? Would Redhat suddenly become more secure
if you had to download MySQL and PostgreSQL from their respective
authors, with the requisite advisories coming from those authors and
thus not counting from Redhat itself?
Bad metrics encourage bad decisions. Those that compare naively
encourage naive security. It's 2005; it's a little late for that.
...............
rms vs. Harry Potter
From Jimmy O'Regan
Amusing, and topical:
...............
Don't Buy Harry Potter Books
Canadians have been ordered not to read books that were sold to them
"by mistake" . Read that article, then don't buy any Harry Potter
books. Everyone who participated in requesting, issuing, enforcing, or
trying to excuse this injunction is the enemy of human rights in
Canada, and they all deserve to pay for their part in it. Not buying
these books will at least make the publisher pay.
Unlike the publisher, who demands that people not read these books, I
simply call on people not to buy them. If you wish to read them, wait,
and you will meet someone who did get a copy. Borrow that copy--don't
buy one. Even better, read something else--there are plenty of other
books just as good, or (dare one suggest) even better.
Making Canada respect human rights will be hard, but a good first step
is to identify the officials and legislators who do not support them.
The article quotes a lawyer as saying, "There is no human right to
read." Any official, judge, or legislator who is not outraged by this
position does not deserve to be in office.
[Neil]
Sending out spoilers on mailing lists is guaranteed to upset someone. I assume
RMS included it to make people who read it less likely to buy. I think it's
an unpleasant tactic and it makes me less inclined to support him on this.
If any of the gang want to redistribute this article further, please snip the
spoilers.
Whoops. Time of morning: I c 'n' p'd from the wrong tab.
[Brian]
Interesting. The paragraph with the spoilers in it isn't on the page
referenced in the URL. Did RMS self-censor (unlikely), or ???
[Jay]
RMS is a shithead, and now I believe it.
And no, I don't blame Jimmy for this.
[Sluggo]
He's right though. When did reading become a "human right" like, oh,
the right to practice your religion and not be killed?
Redneck Texan: what in tar-nation are they talkin about, "human right to
read"? Next thing y'all know they'll be askin for the right to a
mansion on the beach. And that other thing they keep harpin about, that
loonie-versal health care whatsit. In my father's day people never
asked for a handout, they worked and provided for themselves like God
intended.
[Neil]
Yep. One quote I agree with. Elevating reading to a human right seems
excessive, so unlike RMS, I am not enraged by that particular quote.
I would support the idea of a right to sufficient education to be able to
read. I would also support the idea that people have a right to enjoy a book
that they have purchased legally and in good faith, but a right to read any
book or document you want, regardless of whether it not it's published or
confidential is another matter. What would a "right to read" cover and in
what circumstances, I would like to know?
If the injunction really orders them not to read the books they have
purchased, that strikes me as wrong, but hey, we all know the law is an ass,
even in Canada. If I'd bought a book and got an injunction like this, I'd
still read it, I just wouldn't tell them
[Ben]
...and if we extend that line of reasoning just a bit further, it brings
us to (what I think is) RMS' original point. How much of a right do we
grant to our governments to declare arbitrary actions illegal, no matter
how trivial or harmless?
The cynic in me says that governments love having their citizens buy
into a belief that they (the citizens) are guilty of something; people
with something to hide are likely to keep their heads down and be good
little sheep lest they be noticed and shorn. As the saying in Russia
went, "nobody ever asks 'why' when the KGB takes them away." The KGB, of
course, had a matching expression: "if we have the man, we'll make the
case."
If the government is allowed to control trivial aspects of people's
lives, then they will do so. Not in all cases, but... oh, the
"opportunities" that arise. Perhaps this case is not as black-and-white
as it could be, but I surely do see it as a very steep and well-greased
slippery slope - with its entry point just under a hidden trap door.
[Sluggo]
... which comes back to my original point, that there is also a slippery
slope / trap door on the other side. In order to get a diverse
coalition of people (the whole world) to agree to and enforce something,
it has to be narrowly focused and not arbitraily "reinterpreted". It
has long been recognized internationally that people have a right to not
be imprisoned/tortured/killed for their ethnicity, religion, or
participating in political protests. That's what's normally considered
"human rights", and it's why China is under so much scrutiny. Canada
and the EU have more inclusive definitions of basic rights, but those
apply only in those countries and cannot be summarily exported to the
rest of the world as "human rights". China's censorship of the Internet
is deplorable but is not (yet) a "human rights violation".
[Ben]
[blink] Since when is getting the entire world to ratify something a
rational goal? I don't think it's possible - except by the method
employed by US politicians and so aptly described by Dave Barry.
...............
We make presidential candidates go through a lengthy and highly
embarrassing process that a person with even the tiniest shred of
dignity would never get involved in. It's analogous to the ice-breaking
party game "Twister," wherein somebody spins a pointer, and the players
have to put their hands and feet on whatever colored circles it points
to, thus winding up in humiliating positions. And the people who want
to be president have to play. If the spinning pointer of political
necessity points to SUCK UP TO UNIONS, they have to put their left hands
over on that circle; if the spinner points to SUCK UP TO RELIGIOUS NUTS,
they have to put their right feet in that circle; and so on, month
after month, with candidates dropping out one by one as the required
contortions become too difficult, until finally there's only one
candidate left--some sweaty, exhausted, dignity-free yutz in a
grotesquely unnatural pose, with his tie askew and his shirt untucked
and his butt crack showing.
-- Dave Barry
...............
The effect is that nobody gets what they want, and whatever agreement
is reached is so watered down that it's meaningless - and, as a
result, is ignored by everyone. E.g., UN's decisions about Iraq, and
damn near everything else since then (and about half of everything since
UN's inception.)
[Sluggo]
Better to try than to throw up your hands and say it's impossible.
[Ben]
Better to try something different and effective (assuming there is
such an option) than keeping on with something that has long lost its
force.
[Sluggo]
So
creating the UN and its human rights commission and Geneva convention
and ICC et al was a waste of time? I disagree.
[Ben]
I would too, if somebody had said what you're implying I've said. The UN
was very useful at the time of its creation - despite Russia managing to
wangle two seats instead of the one they should have had - but these
days, it's a debating society with damn near no force or effect. I've
known several people - Canadians who had been with their peacekeeping
force - and the strong impression that I got from them was that of
despondency, of rolling that same useless rock up that same useless
mountain, only to have it roll back down again.
At this point, the Big Guys - US and Russia, and to some lesser degree
everyone else - has found their own ways to circumvent or bypass (and in
case of serious disagreement, simply ignore) the UN. My contention is
that it is no longer useful as a vehicle for maintaining peace or a
round table for mediation/negotiation - all of that now goes on at
high-level conferences, which were rarer and more difficult to arrange
in the days when the UN was created.
[Sluggo]
And what were the
alternatives? At least the UN has prevented World War III so far (with
NATO), which was its main purpose.
[Ben]
I think you're giving the UN far too much credit. For one thing, the
projections for WWIII are pretty horrific - at least the ones that we
had when I was in Military Intelligence - and they're not likely to have
improved (<black_humor>except in the kill ratios</black_humor>.) Nuclear
deterrent would be the number one cause, in my mind - not in the number
of people that are likely to die (why would the politicians care? They
never did before), but in the fact that the high-level decision makers -
despite their bunkers, etc. - are much more likely to, or are far less
likely to survive the aftermath.
Nukes make it personal for them. That, to my mind, is the only thing
that will stop them from issuing those orders.
[Sluggo]
The UN has been ineffective in stopping the genocides in
Rwanda/Bosnia/Somalia/Sudan -- but so were its critics.
[Ben]
Errr... so, if I say that a radio doesn't work, my inability to repair
it makes my observation false? Please reconsider what you're saying
here, Mike.
Amy Chua in "World on Fire" describes, in fine detail, how the US
exportation of (some screwed-up version of) democracy plus the
free-market system leads to civil wars and murder of
economically-dominant minorities. It's damn near impossible to disagree
with her data, or the conclusions she draws from it - the lady is
quite sharp. However, she doesn't say "...and here's how to fix it!"
Does that make her observations inaccurate, or her book of no value? I
sincerely doubt it.
[Sluggo]
Re Iraq, I can't comment further without the missing piece -- what you
think the UN did wrong and should have done. You think they should have
supported the US intervention? I think not.
[Ben]
I think that the UN did what they could. The overriding issue is that
they could do nothing effective, except make their statement for the
world to hear - something that is done just as effectively by a protest
march in DC. That's not saying a lot for the UN.
Just to add a personal viewpoint here: I find it sad that this is the
state of the UN, and wish with all my heart that it did have more
effect. But when a rabbit mediates a disagreement between two bears, the
effect of that mediation is not likely to be much - and the rabbit is
likely to get eaten for his trouble.
[Ben]
US and China, for example, have many mutually incompatible goals,
long-term plans, and cultural imperatives. Expecting China to agree with
the US on human rights is a waste of time - particularly since China is
strong enough to not worry about the US in military terms. The human
rights issue between the two is, therefore, at a standstill - but
Walmart still buys 80%+ of what they sell in China.
Remind me again why China should care about anything the US says?
[Sluggo]
The slippery slope is that the more things you pack into this
definition, the less willing a lot of people will be to accept the whole
thing. For instance, the US administration is reinterpreting free trade
and property rights to include perpetual copyrights, anti-circumvention
provisions, and software patents.
[Ben]
Therefore making itself that much less relevant to the world market.
[shrug] If the idiots wielding the broom don't watch out, the tide will
sweep them out to sea.
[Sluggo]
Now, one could make a case that these
should be property rights and included, but instead the administration
is bypassing the debate and arguing these are self-evidently property
rights. Not surprisingly, there is much resistance in other countries,
fears about whether free trade is a synonym for US corporate hegemony,
and wonderings about why countries should harm their own vitality to
benefit foreign patents. Likewise, there is much resistance in the US
to the "right" to living quarters, health care, welfare etc -- this is
seen as the foot in the door for socialism, 90% taxation, and burnt work
ethic. (Didn't you say something about the KGB?) So, do you want to
support basic human rights, or do you want to throw other things in and
weaken support for the basic rights?
[Ben]
If I thought that was a valid question, it would certainly be a dillema.
As it is, I don't see them as mutually exclusive.
[Sluggo]
Stallman has made a good case over the years that the right to read
anything is fundamental. Obviously, not being able to study holy texts
would significantly impact people's practice of religion. So would not
having access to news or commentary. And fiction books often express a
political view or framework, sometimes more valuable than the author
realizes. So it's impossible to censor non-essential texts while
excepting essential, because inevitably you will misclassify an
essential text.
Still, the extremes to which "free speech" and "free reading" can be
taken are ridiculous. Exactly how does suppressing Harry Potter for
two days harm Canadians' access to an adequate variety of
information?
[Ben]
That's not the grounds on which I find the court's decision to be less
than intelligent. Trying to enforce something that is fundamentally
unenforceable - arrogating to themselves the right to decide that you
should voluntarily surrender the value of that for which you have paid -
those are the things which set off all sorts of alarms for me. With
regard to the adequate information issue, I agree with you - I don't
think that this has been violated, or was even involved.
[Rick]
It does seem quite an overreaction. Judges in (to my knowledge) almost
all countries tend to be a bit sweeping in their application of court
orders -- being demigods in their sphere -- and a little sloppy. But,
as you say, it was just a two-day featherweight decree, anyway.
Unlike Richard, I decline to pass judgement on our esteemed Canadian
neighbours' legal doings, and simply state that I've been quick to help
Canadian friends circumvent what they regarded as judicial
overreaching in the past, e.g., by sending them US and European news
coverage of the Karla
Homolka trial.
I happened to be in Alberta recently when Homolka was released from a
Quebec prison at the end of her ten-year sentence. The tedious excess of
news coverage even in good papers like the Globe and Mail was enough
to give even the most stalwart free-press advocate misgivings.
[Sluggo]
How does viewing porn -- another example of "free
speech/reading" -- enable one to make a better decision on election day
or to support a cause?
[Ben]
Since when are those the ultimate ends, and why is personal pleasure
held to be less important those things? You may have to use words of two
syllables or less to explain; I lack the Puritanical programming that
most Americans have absorbed, and can't make those connections
automatically.
[Jimmy]
Now, maybe it's because I witnessed first hand the sort of social
improvements that came from pornography being decriminalised, but I
find it absurd that anyone who is as interested as you are in things
like civil liberties and social equality can even question the
importance of porn.
In my teens (and I'm 2 weeks away from my 26th birthday, BTW -- we're
only talking about one decade) Ireland had a very heavy-handed
Censor's office, which was heavily under the influence of the Church.
Anything vaguely pornographic or 'heretical' was illegal[1].
Part of the downfall of this was technology (satellite TV was becoming
cheaper[2] and put TV out of the censor's hands), another part was
that they went too far -- they banned a newspaper (one of the British
tabloids, "The Daily Sport". In fairness, it did have at least one
picture of a topless women on every other page, but it also had the
best sports coverage of any of the daily newspapers at the time, as
well as covering aspects of the news that none of the other papers
did).
To come to your point: pornography isn't just something you watch,
words can be judged pornographic too. It can help you make a better
decision at election time if you can read an uncensored account of
what the issues are.
[1] "Life of Brian" was found to be both, among other films. I can't
say for certain whether or not there was a direct link between the
two, but (IIRC, which is highly unlikely) after the BBC showed that
film uncensored, the Irish government started blocking British TV
broadcasts, which most people in Ireland had been able to receive.
[2] Every Friday and Saturday night, two of the German channels had
porn -- 'Benny Hill'-type stuff with full frontal nudity, but
'shocking' enough for the priests, enticing enough that the price of
satellite TV halved within a year.
VCRs were still rare around this time.
[Sluggo]
And of course, what does that idiot judge think
he's doing forbidding people from reading the books they've purchased?
Telling them not to talk about it may be reasonable, perhaps, --
there's no right (in the US) to talk about what you hear on police radio
bands -- but telling them they can't read a book that's in front of them
is... paranoia. Hopefully other Canadian courts will view this as an
aberration. Canada has been good about supporting people's rights in
general: crypto importing/exporting, recording CDs, and watching foreign
commercial satellite broadcasts. And gay marriage and marijuana....
Hopefully they aren't about to turn this around.
What about bomb-making materials? Is there a right to read/publish
about those?
[Ben]
Why not? It's the locksmith principle: the people who want that access
will have it. The only ones who will lose out on the knowledge are the
people who can do something positive with it - e.g., the pharmacy clerk
who may recognize that someone is buying materials for bomb-making and
act appropriately.
...............
"In respect to lock-making, there can scarcely be such a thing as
dishonesty of intention: the inventor produces a lock which he
honestly thinks will possess such and such qualities; and he
declares his belief to the world. If others differ from him in
opinion concerning those qualities, it is open to them to say so;
and the discussion, truthfully conducted, must lead to public
advantage: the discussion stimulates curiosity, and curiosity
stimulates invention. Nothing but a partial and limited view
of the question could lead to the opinion that harm can result:
if there be harm, it will be much more than counterbalanced by good."
-- Charles Tomlinson's Rudimentary Treatise on the Construction of
Locks, published around 1850.
...............
[Sluggo]
Let's not forget companies' (self-proclaimed) free-speech "right" to
send you spam.
[Jay]
But let's be clear here. The right to exploit commercially the effort
which was put into that novel belongs to the author and her publisher,
and I see no reason why they should be forced to exercise that right in
any way other than the way they want.
And leaking the spoiler, assuming that was really in RMS's original
(which wouldn't surprise me in the least, given RMS's behavior in the
past), was simply childish.


![[BIO]](misc/cover/nasa.png)
![[BIO]](misc/cover/earth2.png) xplanet
follows the tradition of xearth but using real imagery. I've
prepared this picture using the following options:
xplanet
follows the tradition of xearth but using real imagery. I've
prepared this picture using the following options:
![[BIO]](../gx/2002/note.png) Heather got started in computing before she quite got started learning
English. By 8 she was a happy programmer, by 15 the system administrator
for the home... Dad had finally broken down and gotten one of those personal
computers, only to find it needed regular care and feeding like any other
pet. Except it wasn't a Pet: it was one of those brands we find most
everywhere today...
Heather got started in computing before she quite got started learning
English. By 8 she was a happy programmer, by 15 the system administrator
for the home... Dad had finally broken down and gotten one of those personal
computers, only to find it needed regular care and feeding like any other
pet. Except it wasn't a Pet: it was one of those brands we find most
everywhere today...
 Digital camera audio files
Digital camera audio files

 Greetings from Heather Stern
Greetings from Heather Stern
 Patents
Patents
![[Picture]](../gx/2002/tagbio/conry.jpg) Originally hailing from Ireland, Michael is currently living in Baden,
Switzerland. There he works with ABB Corporate Research as a
Marie-Curie fellow, developing software for the simulation and design
of electrical power-systems equipment.
Originally hailing from Ireland, Michael is currently living in Baden,
Switzerland. There he works with ABB Corporate Research as a
Marie-Curie fellow, developing software for the simulation and design
of electrical power-systems equipment.

![[BIO]](../gx/authors/dyckoff.jpg) Howard Dyckoff is a long term IT professional with primary experience at
Fortune 100 and 200 firms. Before his IT career, he worked for Aviation
Week and Space Technology magazine and before that used to edit SkyCom, a
newsletter for astronomers and rocketeers. He hails from the Republic of
Brooklyn [and Polytechnic Institute] and now, after several trips to
Himalayan mountain tops, resides in the SF Bay Area with a large book
collection and several pet rocks.
Howard Dyckoff is a long term IT professional with primary experience at
Fortune 100 and 200 firms. Before his IT career, he worked for Aviation
Week and Space Technology magazine and before that used to edit SkyCom, a
newsletter for astronomers and rocketeers. He hails from the Republic of
Brooklyn [and Polytechnic Institute] and now, after several trips to
Himalayan mountain tops, resides in the SF Bay Area with a large book
collection and several pet rocks.
 Mike is a Contributing Editor at Linux Gazette. He has been a
Linux enthusiast since 1991, a Debian user since 1995, and now Gentoo.
His favorite tool for programming is Python. Non-computer interests include
martial arts, wrestling, ska and oi! and ambient music, and the international
language Esperanto. He's been known to listen to Dvorak, Schubert,
Mendelssohn, and Khachaturian too.
Mike is a Contributing Editor at Linux Gazette. He has been a
Linux enthusiast since 1991, a Debian user since 1995, and now Gentoo.
His favorite tool for programming is Python. Non-computer interests include
martial arts, wrestling, ska and oi! and ambient music, and the international
language Esperanto. He's been known to listen to Dvorak, Schubert,
Mendelssohn, and Khachaturian too.

![[BIO]](../gx/authors/raby.jpg)

















 But for a look at some really exciting navigation issues, let's
try weather.com (click here to go to a
But for a look at some really exciting navigation issues, let's
try weather.com (click here to go to a 

 Prince Henry
Prince Henry St. Brendan
St. Brendan St. Isidore
St. Isidore![[BIO]](../gx/authors/seymour.jpg)
![[cartoon]](misc/collinge/182superior.jpg)
![[cartoon]](misc/collinge/529versions.jpg)
![[cartoon]](misc/ecol/ecol-201-e.png)
![[cartoon]](misc/ecol/ecol-202-e.png)
![[cartoon]](misc/ecol/ecol-208-e.png)

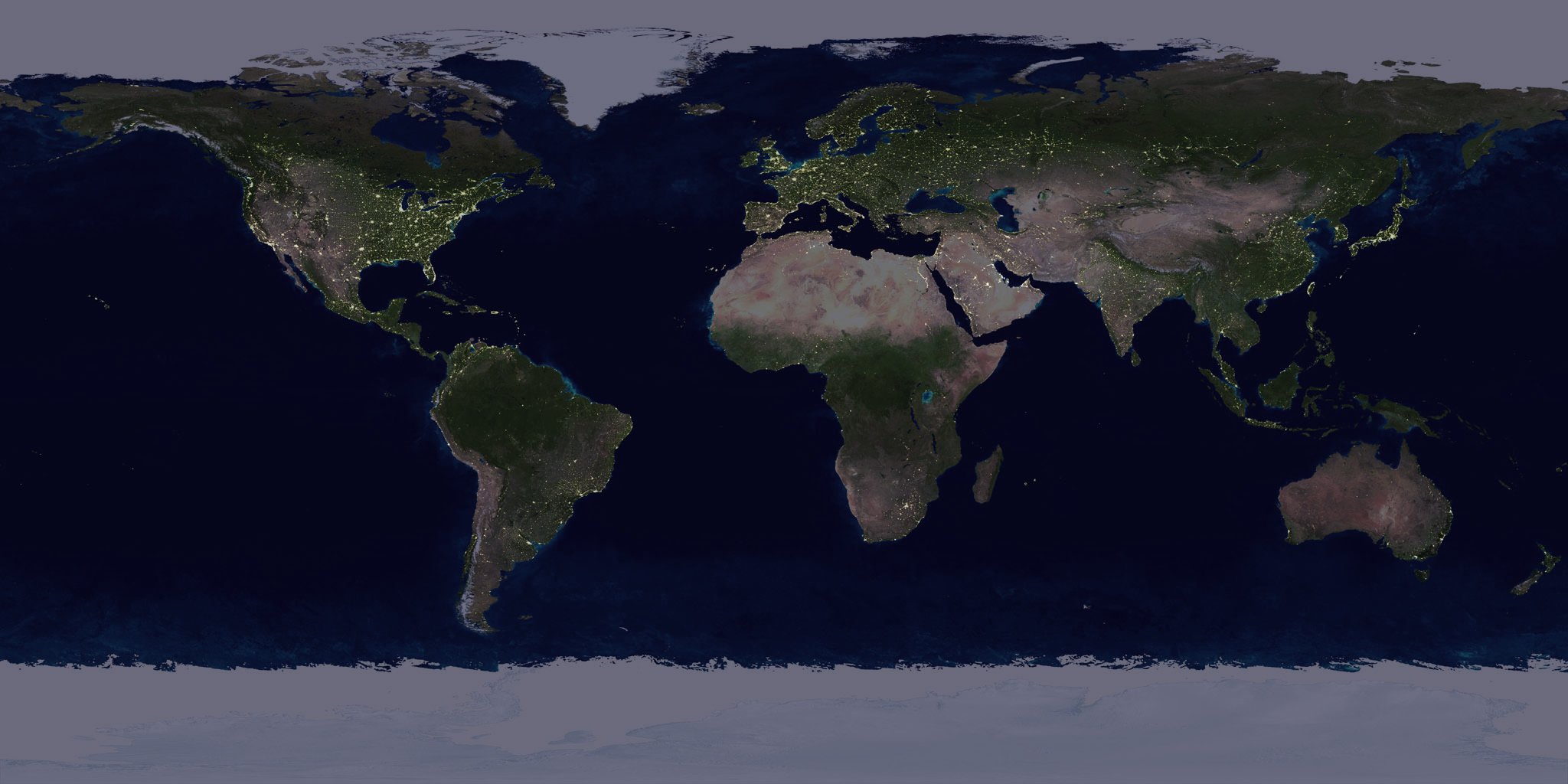{kind=link}
{kind=link}
{kind=link}