Code Inclusion and Partial Classes
Object oriented languages usually support the derivation of new classes by inheriting from existing classes and modifying them. In Sather, the notion of inheritance is split into two separate concepts - type relations between classes and code relations between classes. In this chapter we will deal with the latter (and simpler) concept, that of reusing the code of one class in another. We refer to this as implementation inheritance or code inclusion.
4.1 Include Clauses
The re-use of code from one class in another class is defined by include clauses. These cause the incorporation of the implementation of the specified class, possibly undefining or renaming features with feature modifier clauses. The include clause may begin with the keyword 'private', in which case any unmodified included feature is made private.
| include A a->b, c->, d->private d;
private include D e->readonly f; |
|
Code inclusion permits the re-use of code from a parent concrete class in child concrete class . Including code is a purely syntactic operation in Sather. To help illustrate the following examples, we repeat the interface of EMPLOYEE from page 56.
| class EMPLOYEE is
private attr wage:INT;
readonly attr name:STR;
attr id:INT;
const high_salary:INT := 40000;
create(a_name:STR, a_id:INT, a_wage:INT):SAME is ...
highly_paid:BOOL is ...
end; |
|
Routines that are redefined in the child class over-ride the corresponding routines in the included class. For instance suppose we define a new kind of EMPLOYEE - a MANAGER, who has a number of subordinates.
| class MANAGER is
include EMPLOYEE
create->private oldcreate;
-- Include employee code and rename create to 'oldcreate'
readonly attr numsubordinates:INT; -- Public attribute
create(aname:STR, aid:INT,awage:INT,nsubs:INT):SAME is
-- Create a new manager with the name 'aname'
-- and the id 'aid' and number of subordinates = 'nsubs'
res ::= oldcreate(aname,aid,awage);
res.numsubordinates := nsubs;
return res;
end;
end; |
|
See the EMPLOYEE definition on page 56. The create routine of the MANAGER class extends the EMPLOYEE create routine, which has been renamed to oldcreate (renaming is explained below) and is called by the new create routine.
Points to Note
- The order of inclusion is not significant and cannot affect conflicts.
- External classes may be included if the interface to the language permits this; external Fortran and C classes may not be included.
- Immutable (see page 119) and reference classes cannot be mixed into a single class during inclusion. In the case of arrays (see page 105), there cannot be include paths from reference types to AVAL or from immutable types to AREF i.e. reference types cannot include an immutable array portion and immutable classes cannot include a reference array portion.
- There must be no cycle of classes such that each class includes the next, ignoring the values of any type parameters.
| class A is include B;...
class B is include C;...
class C is include A; .. |
|
- If SAME occurs in included code it is interpreted as the eventual type of the class (as late as possible). We make use of this fact every time we include a create routine that returns SAME
| class FOO is
create:SAME is return new; end;
class SON_OF_FOO is
include FOO;
-- Since create returns SAME, we have create:SON_OF_FOO;
class GRANDSON_OF_FOO is
include SON_OF_FOO; -- Now we have create:GRANDSON_OF_FOO;
a ::= #GRANDSON_OF_FOO; -- Calls GRANDSON_OF_FOO::create:SAME,
-- which returns a GRANDSON_OF_FOO. |
|
4.1.1 Renaming
The include clause may selectively rename some of the included features. It is also possible to include a class and make all routines private, or some selectively public
| class MANAGER is
private include EMPLOYEE;
-- All included features are made private
class MANAGER is
private include EMPLOYEE id->id;
-- Makes the "id" routine public and others stay private |
|
If no clause follows the '->' symbol, then the named features are not included in the class. This is equivalent to 'undefining' the routine or attribute.
| class MANAGER is
include EMPLOYEE id->; -- Undefine the "id" routine
attr id:MANAGER_ID; -- This ' id' has a different type |
|
Points to note
- All overloaded features must be renamed at the same time - there is no way to specify them individually.
- A public routine can be made private by either a private include or by renaming the individual routine to be private
| class MANAGER is
include EMPLOYEE id->private id;
-- Renames both reader and writer routines of the attribute 'id' |
|
- In a private include, renaming a particular feature has the effect of making just that one feature public. For instance
| class MANAGER is
private include EMPLOYEE
name->name; -- only 'name' is made public |
|
- Iterator names may only be renamed as iterator names.
- It is an error if there are no appropriate methods to rename in the included class.
- Both a reader and a writer method must exist if 'readonly' is used in a renaming clause.
| class I_INTERVAL is
private attr first, size:INT;
finish:INT is return first + size - 1 end;
finish(fin:INT) is size := fin - first + 1; end;
...
class LINE_SEGMENT is
include I_INTERVAL
finish->readonly finish;
-- makes private finish(fin:INT)
-- and leaves public finish:INT; |
|
4.1.2 Multiple Inclusion
Sather permits inclusion of code from multiple source classes. The order of inclusion does not matter, but all conflicts between classes must be resolved by renaming. The example below shows a common idiom that is used in create routines to permit an including class to call the attribute initialization routines (by convention, this is frequently called 'init') of parent classes.
| class PARENT1 is
attr a:INT;
create:SAME is return new.init; end;
private init:SAME is a := 42; return self; end;
end; |
|
In the above class, the attributes are initialized in the init routine. The use of such initialization routines is a good practice to avoid the problem of assigning attriutes to the "self" object in the create routine (which is void)
The other parent is similarly defined
| class PARENT2 is
attr c:INT;
create:SAME is return new.init end;
private init:SAME is c := 72 end;
end; |
|
In the child class, both parents are initialized by calling the initialization routines in the included classes
| class DERIVED is
include PARENT1 init-> PARENT_init;
include PARENT2 init-> PARENT2_init; -- Rename init
attr b:INT;
create:SAME is
-- a gets the value 42, b the value 99 and c the value 72
return new.PARENT1_init.PARENT2_init.init
end;
private init:SAME is b := 99; return self;
end; -- class DERIVED |
|
4.1.3 Resolving conflicts
Two methods which are included from different classes may not be able to coexist in the same interface. They are said to conflict with each other. For a full discussion of resolving conflicts, please see page 98. We have to first present the general overloading rule, before discussing when included signatures will conflict and what can then be done about it.
For now, we simply note that if we have signatures with the same name in two included classes, we can simply rename one of them away i.e.
| class FOO is
include BAR bar->; -- eliminate this 'bar' routine
include BAR2; -- Use the 'bar' routine from BAR2 |
|
4.2 Partial Classes and Stub routines
Partial classes have no associated type and contain code that may only be included by other classes. Partial classes may not be instantiated: no routine calls from another class into a partial class are allowed, and no variables may be declared in another class of such a type.
A stub feature may only be present in a partial class. They have no body and are used to reserve a signature for redefinition by an including class. If code in a partial class contains calls to an unimplemented method, that method must be explicitly provided as a stub. The following class is a stub debugging class which checks on the value of a boolean and then prints out a debugging message (preceeding by the class name of 'self')
| partial class DEBUG_MSG is
stub debug:BOOL;
debug_msg(msg:STR) is
-- Prints out the type of "self" and a debugging message
if not debug then
-- Don't print out the message if the debug flag is false
return
end;
type_str:STR;
-- Declared here since used in both branches of the if
if ~void(self) then
type_id:INT := SYS::tp(self);
-- SYS::tp will not work if self is void!
type_str:STR := SYS::str_for_tp(type_id);
else
type_str := "VOID SELF";
end;
#OUT+ "Debug in class:"+type_str +" "+ msg+"\n";
end;
end; |
|
This class can be used by some other class - for instance, a main routine that wants to print out all the arguments to main. The stub routine 'debug' must be filled in using either an attribute (a constant, in this case) or a routine.
| class MAIN is
include DEBUG_MSG;
const debug:BOOL := true; -- Fill in the stub.
main(args:ARRAY{STR}) is
loop arg:STR := args.elt!
debug_msg("Argument:"+arg); -- Print out the argument
end;
end;
end; |
|
Points to note
- Partial classes cannot be used to instantiate parameters of a parametrized class. For example, 'ARRAY{DEBUG_MSG}' would not be legal.
- Create cannot be called on a partial class, nor can a partial class occur as the type of a variable or attribute.
4.2.1 Mixins: A Prompt Example
This code demonstrates the use of partial classes. Each MIXIN class provides a different way of prompting the user; each can be combined with COMPUTE to make a complete program. The stub in COMPUTE allows that class to be type checked without needing either mix-in class. Only COMPUTE_A and COMPUTE_B may actually be instantiated.
Now suppose that we have a 'COMPUTE' class that requires a prompt for some input data. It can leave the prompt routine as a stub, which will later be filled in by some prompt class
| partial class COMPUTE is
stub prompt_user:STR;
main is
res ::= prompt_user;
-- Convert it to an integer and do something with it
i:INT := res.cursor.get_int;
#OUT+" I'm going to compute with this number, now:"+i+"\n";
....
end;
end; -- partial class COMPUTE |
|
We can now create different computation classes by mixing an arbitrary prompt style with the main computation partial class.
| class COMPUTE_A is
include COMPUTE;
include PROMPT_STYLE_A;
end; -- class COMPUTE_A
class COMPUTE_B is
include COMPUTE;
include PROMPT_STYLE_B;
end; -- class COMPUTE_B |
|
Abstract Classes and Subtyping
Abstract class definitions specify interfaces without implementations. Abstract class names must be entirely uppercase and must begin with a dollar sign '$' ; this makes it easy to distinguish abstract type specifications from other types, and may be thought of as a reminder that operations on objects of these types might be more expensive since they may involve dynamic dispatch. In order to motivate the notion of abstract classes, we will start by considering different implementations of a data structure.
5.1 Abstracting over Implementations
We will illustrate the need for abstraction by considering the implementation of a classic data structure, the stack. Objects are removed from a stack such that the last object to be inserted is the first to be removed (Last In First Out). For the sake of simplcity, we will define our stack to hold integers.
5.1.1 Implementing a Stack using an Array
The obvious implementation of a stack is using an array and a pointer to the top of the stack. When the stack outgrows the original array we allocate, we double the size of the array and copy the old elements over. This technique is known as amortized doubling and is an efficient way to allocate space for a datastructure whose size is not known when it is created.
| class ARR_STACK is
private attr elems:ARRAY{INT};
private attr index:INT; -- Points to the next location to insert
create:SAME is
res::=new; res.elems:=#ARRAY{INT}(5); res.index := 0; return res;
end;
push(e:INT) is
if index > elems.size then
new_elems:ARRAY{INT} := #ARRAY{INT}(index * 2);
-- copy over the old elements
loop new_elems.set!(elems.elt!) end;
elems := new_elems;
end;
elems[index] := e;
index := index + 1;
end;
pop:INT is index := index - 1; return elems[index]; end;
is_empty:INT is return index = 0 end;
end; |
|
It would be appropriate to also shrink the array when elements are popped from the stack, but we ignore this complexity for now.
5.1.2 A Stack Calculator
The stack class we defined can now be used in various applications. For instance, suppose we wish to create an calculator using the stack
| class RPN_CALCULATOR is
private attr stack:ARR_STACK;
create:SAME is res ::=new; res.stack := #ARR_STACK; return res; end;
push(e:INT) is stack.push(e) end;
add:INT is
-- Add the two top two eleemnts
if stack.is_empty then empty_err; return 0; end;
arg1:INT := stack.pop;
if stack.is_empty then empty_err; return 0 end;
arg2:INT := stack.pop
return arg1 + arg2;
end;
private empty_err is #ERR+"No operands available!" end;
end; |
|
. This corresponds to a H-P style reverse polish notation calculator (RPN) where you first enter operands and then an operator.
5.1.3 A Linked List Representation of a Stack
An alternative implementation of a stack might make use of a chain of elements i.e. a linked list representation. Each link in the chain has a pointer to the next element
| class STACK_ELEM_HOLDER is
readonly attr data:INT;
attr next:INT_STACK_ELEM;
create(data:INT):SAME is
res ::= new; res.data := data; res.next := void; return res;
end;
end; |
|
The whole stack is then constructed using a chain of element
| class LINK_STACK is
private attr head:STACK_ELEM_HOLDER;
create:SAME is res ::= new; return res; end;
push(e:INT) is
elem_holder ::= #STACK_ELEM_HOLDER(e);
elem_holder.ext := head;
head := elem_holder;
end;
pop:INT is
res:INT :+ head.data;
head := head.next;
end;
is_empty:BOOL is return void(head) end;
end; |
|
holders
5.1.4 Switching Representations:Polymorphism
Each of these stack implementations has advantages and disadvantages (the trade-offs are not very significant in our example, but can be quite considerable in other cases). Either of these stacks could be used in our calculator. To use the linked list stack we would need to replace ARR_STACK by by LINK_STACK. wherever it is used.
It would be nice to be able to write code such that we could transparently replace one kind of stack by the other. If we are to do this, we would need to be able to refer to them indirectly, through some interface which hides which particular implementation we are using. Interfaces of this sort are described by abstract classes in Sather. An abstract class that describes the stack abstraction is
| abstract class $STACK is
create:SAME;
push(e:INT);
pop:INT;
is_empty:BOOL;
end; |
|
Note that the interface just specifies the operations on the stack, and says nothing about how they are implemented. We have to then specify how our two implementations conform to this abstraction. This is indicated in the definition of our implementations. More details on this will follow in the sections below.
| class ARR_STACK < $STACK is ... same definition as before ...
class LINK_STACK < $STACK is ... same definition as before ... |
|
The calculator class can then be written as follows
| class RPN_CALCULATOR is
private attr stack:$STACK;
create(s:$STACK):SAME is res::= new; res.stack:=s; return res; end;
... 'add' and 'push' behave the same
end; |
|
In this modified calculator, we provide a stack of our choice when creating the calculator. Any implementation that conforms to our stack abstraction my be used in place of the array based stackt
| s:LINK_STACK := #LINK_STACK;
calc:RPN_CALCULATOR := #RPN_CAlCULATOR(s);
calc.push(3); calc.push(5);
#OUT+calc.add; -- Prints out 8 |
|
5.2 Abstract Class Definitions
The body of an abstract class definition consists of a semicolon separated list of signatures. Each specifies the signature of a method without providing an implementation at that point. The argument names are required for documentation purposes only and are ignored.
| abstract class $SHIPPING_CRATE is
destination:$LOCATION;
weight:FLT;
end; -- abstract class $SHIPPING_CRATE |
|
Due to the rules of subtyping, which will be introduced on page 87, there is one restriction on the signatures - SAME is permitted only for a return type or out arguments in an abstract class signature.
Abstract types can never be created! Unlike concrete classes, they merely specify an interface to an object, not an object itself. All you can do with an abstract type is to declare a variable to be of that type. Such a variable can point to any actual object which is a subtype of that abstract class. How we determine what objects such an abstract variable can point to is the subject of the next section.
Note that we can, of course, provide a create routine in the abstract class
| abstract class $SHIPPING_CRATE is
create:SAME; ... |
|
However, we can never call this creation routine on a void abstract class i.e. the following is prohibited
crate:$SHIPPING_CRATE := #$SHIPPING_CRATE; -- ILLEGAL
In fact, all class calls (:: calls) are prohibited on abstract classes
f:FLT := $SHIPPING_CRATE::weight; -- ILLEGAL
Since abstract classes do not define objects, and do not contain shared attributes or constants, such calls on the class are not meaningful.
Example: An abstract employee
$EMPLOYEE illustrates an abstract type. EMPLOYEE and MANAGER are subtypes. Abstract type definitions specify interfaces without implementations.. Below, we will illustrate how the abstract type may be used.
| abstract class $EMPLOYEE is
-- Definition of an abstract type. Any concrete class that
-- subtypes from this abstract class must provide these routines.
name:STR;
id:INT;
end; |
|
This abstract type definition merely states that any employee must have a name and an id.
More abstract class examples
Here's an example from the standard library. The abstract class $STR represents the set of types that have a way to construct a string suitable for output. All of the standard types such as INT, FLT, BOOL and CPX know how to do this, so they are subtypes of $STR. Attempting to subtype from $STR a concrete class that didn't provide a str method would cause an error at compile time.
| abstract class $STR is
-- Ensures that subtypes have a 'str' routine
str:STR; -- Return a string form of the object
end; |
|
In this illegal abstract class, A and B do not conflict because their arguments are concrete and are not the same type. However, because the argument of C is abstract and unrelated it conflicts with both A and B. D does not conflict with A, B or C because it has a different number of parameters.
| abstract class $FOO is
foo(arg:INT); -- method A
foo(arg:BOOL); -- method B
foo(arg:$FOO); -- method C
foo(a, b:INT) ; -- method D
end; |
|
5.3 Subtyping
As promised, here is the other half of inheritance, subtyping. A subtyping clause ('<' followed by type specifiers) indicates that the abstract signatures of all types listed in the subtyping clause are included in the interface of the type being defined. In the example, the subtyping clause is
abstract class $SHIPPING_CRATE< $CRATE is ...
The interface of an abstract type consists of any explicitly specified signatures along with those introduced by the subtyping clause.
Points to note about subtyping:
- Every type is automatically a subtype of $OB
- Only abstract types can be mentioned in the subtyping clause
- When a subtyping clause is used in a partial class, it enforces the basic subtyping rule using the stub routine.
- There must be no cycle of abstract types such that each appears in the subtype list of the next, ignoring the values of any type parameters but not their number.
- A subtyping clause may not refer to SAME.
- SAME is only permitted as a return type or on out arguments in abstract class signatures.
5.3.1 The Type Graph
We frequently refer to the Sather type graph, which is a graph whose nodes represent Sather types and whose edges represent subtyping relationships between sather types. Subtyping clauses introduce edges into the type graph. There is an edge in the type graph from each type in the subtyping clause to the type being defined. The type graph is acyclic, and may be viewed as a tree with cross edges (the root of the tree is $OB, which is an implicit supertype of all other types).
| abstract class $TRANSPORT is ...
abstract class $FAST is ...
abstract class $ROAD_TRANSPORT < $TRANSPORT is ...
abstract class $AIR_TRANSPORT < $TRANSPORT, $FAST is ...
class CAR < $ROAD_TRANSPORT is ...
class DC10 < $AIR_TRANSPORT is ... |
|
Since it is never possible to subtype from a concrete class (a reference, immutable or external class), these classes, CAR and DC10 form the leaf nodes of the type graph.
5.3.2 Dynamic Dispatch and Subtyping
Once we have introduced a typing relationship between a parent and a child class, we can use a variable of the type of the parent class to hold an object with the type of the child. Sather supports dynamic dispatch - when a function is called on a variable of an abstract type, it will be dispatched to the type of the object actually held by the variable. Thus, subtyping provides polymorphism.
An example: Generalizing Employees
To illustrate the use of dispatching, let us consider a system in which variables denote abstract employees which can be either MANAGER or EMPLOYEE objects. Recall the defintions of manager and employee
| class EMPLOYEE < $EMPLOYEE is ...
-- Employee, as defined earlier
class MANAGER < $EMPLOYEE is ...
-- Manager as defined earlier on page 56 |
|
The above defintions can then be used to write code that deals with any employee, regardless of whether it is a manager or not
| class TESTEMPLOYEE is
main is
employees:ARRAY{$EMPLOYEE} := #ARRAY{$EMPLOYEE}(3);
-- employees is a 3 element array of employees
i:INT := 0; wage:INT := 0;
loop until!(i = employees.size);
emp:$EMPLOYEE := employees[i];
emp_wage:INT := emp.wage;
-- emp.wage is a dispatched call on "'age'
wage := wage+emp_wage;
end;
#OUT+wage+"\n";
end;
end; |
|
The main program shows that we can create an array that holds either regular employees or managers. We can then perform any action on this array that is applicable to both types of employees. The wage routine is said to be dispatched. At compile time, we don't know which wage routine will be called. At run time, the actual class of the object held by the emp variable is determined and the wage routine in that class is called.
5.4 Supertyping
Unlike most other object oriented languages, Sather also allows the programmer to introduce types above an existing class. A supertyping clause ('>' followed by type specifiers) adds to the type graph an edge from the type being defined to each type in the supertyping clause. These type specifiers may not be type parameters (though they may include type parameters as components) or external types. There must be no cycle of abstract classes such that each class appears in the supertype list of the next, ignoring the values of any type parameters but not their number. A supertyping clause may not refer to SAME.
If both subtyping and supertyping clauses are present, then each type in the supertyping list must be a subtype of each type in the subtyping list using only edges introduced by subtyping clauses. This ensures that the subtype relationship can be tested by examining only definitions reachable from the two types in question, and that errors of supertyping are localized.You define supertypes of already existing types. The supertype can only contain routines that are found in the subtype i.e. it cannot extend the interface of the subtype.
| abstract class $IS_EMPTY > $LIST, $SET is
is_empty:BOOL;
end; |
|
5.4.1 Using supertyping
The main use of supertyping arises in defining appropriate type bounds for parametrized classes, and will be discussed in the next chapter (see Supertyping and Type Bounds on page 109).
5.5 Type Conformance
In order for a child class to legally subtype from a parent abstract class, we have to determine whether the signatures in the child class are consistent with the signatures in the parent class. The consistency check must ensure that in any code, if the parent class is replaced by the child class, the code would continue to work. This guarantee of substuitability which is guaranteed to be safe at compile time is at the heart of the Sather guarantee of type-safety.
5.5.1 Contravariant conformance
The type-safe rule for determining whether a signature in a child class is consistent with the definition of the signature in the parent class is referred to as the conformance rule[1]. The rule is quite simple, but counter-intuitive at first. Assume the simple abstract classes which we will use for argument types
| abstract class $UPPER is ...
abstract class $MIDDLE < $UPPER is...
abstract class $LOWER < $MMIDDLE is ... |
|
If we now have an abstract class with a signature
| abstract class $SUPER is
foo(a1:$MIDDLE, out a2:$MIDDLE, inout a3:$MIDDLE):$MIDDLE;
end; |
|
What are the arguments types of foo in a subytpe of $SUPER? The rule says that in the subtype definition of foo
- Normal arguments (with the mode in) must have the same type or a supertypes
- out arguments and return values must have the same type or a subtype
- inout arguments must have the same type
Thus, a valid subtype of $SUPER is
| abstract class $SUPER is
foo(a1:$MIDDLE, out a2:$MIDDLE, inout a3:$MIDDLE):$MIDDLE;
end; |
|
We will explain this rule and its ramifications using an extended example.
Suppose we start with herbivores and carnivores, each of which are capable of eating
| abstract class $HERBIVORE is
eat(food:$PLANT);
abstract class $CARNIVORE is
eat(food:$MEAT);
abstract class $FOOD is ...
abstract class $PLANT < $FOOD is...
abstract class $MEAT < $FOOD is...
 | |
|
What does not work
It would appear that both herbivores and carnivores could be subtypes of omnivores.
| abstract class $OMNIVORE is eat(food:$FOOD);
abstract class $CARNIVORE < $OMNIVORE is ..
abstract class $HERBIVORE < $OMNIVORE is ... |
|
However, subtyping conformance will not permit this! The argument to eat in $HERBIVORE is $PLANT which is not the same as or a supertype of $FOOD, the argument to eat in $OMNIVORE.
To illustrate this, consider a variable of type $OMNIVORE, which holds a herbivore.
| cow:$HERBIVORE := -- assigned to a COW object
animal:$OMNIVORE := cow;
meat:$MEAT;
animal.eat(meat); |
|
This last call would try to feed the animal meat, which is quite legal according to the signature of $OMNIVORE::eat($FOOD), since $MEAT is a subtype of $FOOD. However, the animal happens to be a cow, which is a herbivore and cannot eat meat. 
What does work
When contravariance does not permit a subtyping relationship this is usually an indication of an exceptional case or an error in our conceptual understanding. In this case, we note that omnivores are creatures that can eat anything. But a herbivore really is not an omnivore, since it cannot eat anything. More importantly, a herbivore could not be substuted for an omnivore. It is, however, true that an omnivore can act as both a carnivore and a herbivore.
| abstract class $CARNIVORE is eat(food:$MEAT); ...
abstract class $HERBIVORE is eat(food:$PLANT);...
abstract class $OMNIVORE < $HERBIVORE, $CARNIVORE is
eat(food:$FOOD); ... |
|
The argument of eat in the omnivore is $FOOD, which is a supertype of $MEAT, the argument of eat in $CARNIVORE. $FOOD is also a supertype of $PLANT which is the argument of eat in $HERBIVORE. 
5.5.2 Subtyping = substitutability
A key distinction is that between is-a and as-a relationships. When a class, say $OMNIVORE subtypes from another class such as $CARNIVORE, it means that an omnivore can be used in any code which deals with carnivores i.e. an omnivore can substitute for a carnivore. In order for this to work properly, the child class omnivore must be able to behave as-a carnivore. In many cases, an is-a relationship does not satisfy the constraints required by the as-a relationship. The contravariant conformance rule captures the necessary as-a relationship between a subtype and a supertype.
5.6 The typecase statement
It is sometimes necessary to bypass the abstraction and make use of information about the actual type of the object to perform a particular action. Given a variable of an abstract type, we might like to make use of the actual type of the object it refers to, in order to determine whether it either has a particular implementation or supports other abstractions.
The typecase statement provides us with the ability to make use of the actual type of an object held by a variable of an abstract type.
| a:$OB := 5;
... some other code...
res:STR;
typecase a
when INT then -- 'a' is of type INT in this branch
#OUT+"Integer result:"+a;
when FLT then -- 'a' is of type FLT in this branch
#OUT+"Real result:"+a
when $STR then -- 'a' is $STR and supports '.str'
#OUT+"Other printable result:"+a.str;
else
#OUT+"Non printable result";
end; |
|
t
The typecase must act on a local variable or an argument of a method.On execution, each successive type specifier is tested for being a supertype of the type of the object held by the variable. The statement list following the first matching type specifier is executed and control passes to the statement following the typecase.
Points to note
- It is not legal to assign to the typecase variable within the statement lists.
- If the object's type is not a subtype of any of the type specifiers and an else clause is present, then the statement list following it is executed.
- It is a fatal error for no branch to match in the absence of an else clause.
- If the value of the variable is void when the typecase is executed, then its type is taken to be the declared type of the variable. In the above example, the declared type of a is $OB , which does not match any of the branches, so the else clause is taken
- The variable of the typecase must be a local variable or a method argument.
- If the typecase appears in an iterator, then the mode of the argument must be once; otherwise, the type of object that such an argument holds could change.
- The typecase does not search for the branch with the tightest match - it goes down the first branch that matches.
- After a branch has been selected, the typecase tries to cast the variable to as narrow a type as possible - if the declared type of the variable is actually stronger than (a subtype of) the chosen branch, then the variable will keep the stronger, declared type. For instance
| a:$SET{INT};
typecase a
when INT then ... -- a will never get here, INT is not < $SET{INT}
when $OB then ...
-- a has the type of $SET{INT} which is stronger than $OB |
|
Typecase Example
For instance, suppose we want to know the total number of subordinates in an array of general employees.
| peter ::= #EMPLOYEE("Peter",1); -- Name = "Peter", id = 1
paul ::= #MANAGER("Paul",12,10); -- id = 12,10 subordinates
mary ::= #MANAGER("Mary",15,11); -- id = 15,11 subordinates
employees:ARRAY{$EMPLOYEE} := |peter,paul,mary|;
totalsubs:INT := 0;
loop employee:$EMPLOYEE := employees.elt!; -- yields array elements
typecase employee
when MANAGER then
totalsubs := totalsubs + employee.numsubordinates;
else end;
end;
#OUT+"Number of subordinates:"+totalsubs+"\n"; |
|
Within each branch of the typecase, the variable has the type of that branch (or a more restrictive type, if the declared type of the variable is a subtype of the type of that branch).
5.7 The Overloading Rule
We mentioned an abridged form of the overloading rule in the chapter on Classes and Objects. That simple overloading rule was very limited - it only permitted overloading based on the number of arguments and the presence or absence of a return value. Here, it is generalized.
As a preliminary warning:the overloading are flexible, but are intended to support the coexistance of multiple functions that have the same meaning, but differ in some implementation detail. Calling functions that do different things by the same name is wrong, unwholesome and severely frowned upon! Hence, using the function name times with different number of arguments to mean
5.7.1 Extending Overloading
Overloading based on Concrete Argument Types
However, we often want to overload a function based on the actual type of the arguments. For instance, it is common to want to define addition routines (plus) that work for different types of values. In the INT class, we could define
| plus(a:INT):INT is ...
plus(a:FLT):INT is ... |
|
We can clearly overload based on a the type of the argument if it is a non-abstract class - at the point of the call, the argument can match only one of the overloaded signatures.
Overloading based on Abstract Argument Types
Extending the rule to handle abstract types is not quite as simple. To illustrate the problem, let us first introduce the $STR abstract class
| abstract class $STR is
str:STR;
end; |
|
The $STR absraction indicates that subtypes provide a routine that renders a string version of themselves. Thus, all the common basic types such as INT, BOOL etc. are subtypes of $STR and provide a str: STR routine that returns a string representation of themselves.
Now consider the interface to the FILE class. In the file class we would like to have a general purpose routine that appends any old $STR object, by calling the str routine on it and then appending the resulting string. This allows us to append any subtype of $STR to a file at the cost of a run-time dispatch. We also want to define more efficient, special case routines (that avoid the dispatched call to the str routine) for common classes, such as integers
| class FILE is
-- Standard output class
(1) plus(s:$STR) is ....
(2) plus(s:INT) is ... |
|
.
The problem arises at the point of call
| f:FILE := FILE::open_for_read("myfile");
a:INT := 3;
f+a; |
|
Now which plus routine should we invoke? Clearly, both routines are valid, since INT is a subtype of $STR. We want the strongest or most specific among the matching methods, (2) in the example above. Though the notion of the most specific routine may be clear in this case, it can easily get murky when there are more arguments and the type graph is more complex.
The Demon of Ambiguity
It is not difficult to construct cases where there is no single most specific routine. The following example is hypotheical and not from the current Sather library, but illustrates the point. Suppose we had an abstraction for classes that can render a binary versions of themselves. This might be useful, for instance, for the floating point classes, where a binary representation may be more compact and reliable than a decimal string version
| abstract class $BINARY_PRINTABLE is
-- Subtypes can provide a binary version of themselves
binary_str:STR;
end; |
|
Now suppose we have the following interface to the FILE class
| class FILE is
(1) plus(s:$STR) is ..
(2) plus(s:$BINARY_STR) is ...
(3) plus(s:INT) is ... |
|
Now certain classes, such as FLT could subtype from $BINARY_STR instead of from $STR. Thus, in the following example, second plus routine would be seletected
Everything is still fine, but suppose we now consider
| class FLTD < $BINARY_STR, $STR is
binary_str:STR is ... binary version
str:STR is ... decimal version |
|
The plus routine in FILE cannot be unambiguously called with an argument of type FLTD i.e. a call like 'f+3.0d' is ambiguous. None of the 'plus' routines match exactly; (1) and (2) both match equally well.
The above problem arises because neither (1) nor (2) is more specific than the other - the problem could be solved if we could always impose some ordering on the overloaded methods, such that there is a most specific method for any call.
We could resolve the above problem by ruling the FILE class to be illegal, since there is a common subtype to both $STR and $BINARY_STR, namely FLTD. Thus, a possible rule would be that overloading based on abstract arguments is permitted, provided that the abstract types involved have no subtypes in common.
However, the problem is somewhat worse than this in Sather, since both subtyping and supertyping edges can be introduced after the fact. Thus, if we have the following definition of FLTD
| class FLTD < $BINARY_STR is
binary_str:STR is ...
str:STR is ... |
|
the file class will work. However, at a later point, a user can introduce new edges that cause the same ambiguity described above to reappear!
| abstract class $BRIDGE_FLTD < $STR > FLTD is end; |
|
Adding this new class introduces an additional edge into the type graph and breaks existing code.
The essense of the full-fledged overloading rule avoids this problem by requiring that the type of the argument in one of the routines must be known to be more specific than the type of the argument in the corresponding position in the other routine. Insisting that a subtyping relationship between corresponding arguments must exist, effectively ensures that one of the methods will be more specific in any given context. Most importantly, this specificity cannot be affected by the addition of new edges to the type graph. Thus, the following definition of $BINARY_STR would permit the overloading in the FILE class to work properly
| abstract class $BINARY_STR < $STR is
binary_str:STR;
end; |
|
When the 'plus' routine is called with a FLTD, the routine 'plus($BINARY_STR)' is unambiguously more specific than 'plus($STR)'. 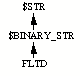
5.7.2 Permissible overloading
Two signatures (of routines or iterators) can overload, if they can be distinguised in some manner- thus, they must differ in one of the following ways
Overload 1.: The presence/absence of a return value
Overload 2.: The number of arguments
Overload 3.: In at least one case corresponding arguments must have different marked modes (in and once modes are not marked at the point of call and are treated as being the same from the point of view of overloading).
Overload 4.: In at least one of the in, once or inout argument positions: (a) both types are concrete and different or (b) there is a subtyping relationship between the corresponding arguments i.e. one must be more specific than the other. Note that this subtyping ordering between the two arguments cannot be changed by other additions to the type graph, so that working libraries cannot be broken by adding new code.
Note that this definition of permissible permissible coexistance is the converse of the definition of conflict in the specification. That is, if two signatures cannot coexist, they conflict and vice-versa.
| abstract class $VEC is ...
abstract class $SPARSE_VEC < $VEC is ...
abstract class $DENSE_VEC < $VEC is...
class DENSE_VEC < $DENSE_VEC is ...
class SPARSE_VEC < $SPARSE_VEC is .... |
|
Given the above definitions of vectors, we can define a multiply and add routine in the matrix class
| abstract class $MATRIX is
(1) mul_add(by1:$VEC, add1:$SPARSE_VEC);
(2) mul_add(by2:$DENSE_VEC, add2:$VEC);
-- (1) and (2) can overload, since the arg types can be ordered
-- by2:$DENSE_VEC < by1:$VEC,
-- add2:$VEC > add1:$SPARSE_VEC
(3) mul_add(by3:DENSE_VEC, add3:SPARSE_VEC);
-- (3) does not conflict with the (1) and (2) because there
-- is a subtyping relation between corresponding arguments.
-- (vs 1) by3:DENSE_VEC < by1:$VEC ,
-- add3:SPARSE_VEC < add1:$SPARSE_VEC
-- (vs 2) by3:DENSE_VEC < by2:$DENSE_VEC ,
-- add3:SPARSE_VEC < add2:$VEC |
|
While any of the above conditions ensures that a pair of routines can co-exist in an interface, it still does not describe which one will be chosen during a call.
Finding matching signatures
When the time comes to make a call, some of the coexisting routines will match - these are the routines whose arguments are supertypes of the argument types in the call. Among these matching signatures, there must be a single most specific signature. In the example below, we will abuse sather notation slightly to demonstrate the types directly, rather than using variables of those types in the arguments
| f:$MATRIX;
f.mul_add(DENSE_VEC, SPARSE_VEC); -- Matches (1), (2) and (3)
f.mul_add($DENSE_VEC, $SPARSE_VEC); -- Matches (1) and (2)
f.mul_add($DENSE_VEC, $DENSE_VEC); -- Matches (2)
f.mul_add($SPARSE_VEC, SPARSE_VEC); -- Matches (1) |
|
Finding a most specific matching signature
For the method call to work, the call must now find an unique signature which is most specific in each argument position
| f:$MATRIX;
f.mul_add(DENSE_VEC, SPARSE_VEC) -- (3) is most specific
f.mul_add($DENSE_VEC, $DENSE_VEC); -- Only one match
f.mul_add($SPARSE_VEC, $SPARSE_VEC); -- Only one match |
|
The method call 'f.mul_add($DENSE_VEC, $SPARSE_VEC)' is illegal, since both (1) and (2) match, but neither is more specific.
More examples
Let us illustrate overloading with some more examples. Consider 'foo(a:A, out b:B);'
All the following can co-exist with the above signature
| foo(a:A, out b:B):INT -- Presence return value (Overload 1)
foo(a:A) -- Number of arguments (Overload 2)
foo(a:A, b:B) -- Mode of second argument (Overload 3)
foo(a:B, out b:B) -- Different concrete types in
-- the first argument (Overload 4a) |
|
The following cannot be overloaded with foo(a:A,out b:B):INT;
| foo(a:A,b:B):BOOL; -- Same number, types of arguments,
-- both have a return type.
-- Difference in actual return type cannot be used to overload |
|
For another example, this time using abstract classes, consider the mathematical abstraction of a ring over numbers and integers. The following can be overloaded with the 'plus' function in a class which describes the mathematical notion of rings
| abstract class $RING is
plus(arg:$RING):$RING;
abstract class $INT < $RING is
plus(arg:$INT):$RING;
-- By Overload 4 since he type of arg:$INT < arg:$RING
abstract class $CPX < $RING is
plus(arg:$CPX):$RING;
-- By Overload 4b, since the type of arg:$CPX < arg:$RING |
|
The overloading works because there is a subtyping relationship between the arguments 'arg' to 'plus' The following overloading also works
| abstract class $RING is
mul_add(ring_arg1:$RING, ring_arg2:$RING);
abstract class $INT < $RING is
mul_add(int_arg1:$INT, int_arg2:$INT);
-- int_arg1:$INT < ring_arg:$INT and
-- int_arg2:$INT < ring_arg2:$INT |
|
Now there is a subtyping relationship between $INT::mul_add and $RING::mul_add for both 'arg1' and 'arg2', but there is no subtyping
This somewhat complex rule permits interesting kinds of overloading that are needed to implement a kind of statically resolved, type-safe co-variance which is useful in the libraries, while not sacrificing compositionality. Externally introducing subtyping or supertyping edges into the typegraph cannot suddenly break overloading in a library.
5.7.3 Overloading as Statically resolved Multi-Methods
For the curious reader, we would like to point out a connection to the issue of co and contra-variance. It was this connection that actually motivated our overloading rules. The first point to note is that overloading is essentially like statically resolved multi-methods i.e. methods that can dispatch on more than one argument. Overloaded methods are far more restricted than multi-methods since the declared type must be used to perform the resolution. The second point to note is that multi-methods can permit safe 'covariance' of argument types. For instance, consider the following abstractions
| abstract class $FIELD_ELEMENT is
add(f:$FIELD_ELEMENT):$FIELD_ELEMENT;
abstract class $NUMBER < $FIELD_ELEMENT is
add(f:$NUMBER):$NUMBER
abstract class $INTEGER < $NUMBER is
add(f:$INTEGER):$INGEGER |
|
Note that all the above definitions of the 'plus' routines safely overload each other. As a consequence, it is possible to provide more specific versions of functions in sub-types.
5.7.4 Conflicts when subtyping
When we described subtyping earlier, we said that the interface of the abstract class being defined is augmented by all the signatures of the types in the subtyping clause. But what if some of these supertypes contain conflicting signatures?
It is important to note that a conflict occurs when two signatures are so similar that they cannot co-exist by the over-loading rules. This happens when there is not even one argument where there is a sub- or supertyping relationship or where both arguments are concrete. As a consequence, you can always construct a signature that is more general than the conflicting signatures
| abstract class $ANIMAL is ...
abstract class $PIG < $ANIMAL is ...
abstract class $COW < $ANIMAL is ...
abstract class $COW_FARM is has(a:$COW); end;
abstract class $PIG_FARM is has(a:$PIG); end;
abstract class $ANIMAL_FARM < $COW_FARM, $PIG_FARM is
-- The signatures for has(a:$COW) and has(a:$PIG) must
-- be generalized
has(a:$ANIMAL);
-- $ANIMAL is a supertype of $COW and $PIG, so this 'has'
-- conforms to both the supertype 'has' signatures
end; |
|
In the above example, when we create a more general farm, we must provide a signature that conforms to all the conflicting signatures by generalizing the in arguments. If the arguments in the parent used the out mode, we would have to use a subtype in the child. A problem is exposed if the mode of the arguments in the parents is inout
| abstract class $COW_FARM is processes(inout a:$COW); end;
abstract class $PIG_FARM is processes(inout a:$PIG); end;
-- ILLEGAL! abstract class $ANIMAL_FARM < $COW_FARM, $PIG_FARM is
-- No signature can conform to both the 'processes' signatures
-- in the $COW_FARM and $PIG_FARM |
|
5.7.5 Conflicts during code inclusion
Since Sather permits inclusion from mulitple classes, conflicts can easily arise between methods from different classes. The resolution of inclusion conflicts is slightly different for attributes than it is for methods, so let us consider them separately.
Conflicting Methods
- 1. First, let us consider the resolution method for routines. Conflicts can occur between methods in different classes that have been included and must be resolved by renaming the offending feature in all but one of the included classes.
| class PARENT1 is foo(INT):INT;
class PARENT2 is foo(INT):BOOL; -- conflicts with PARENT1::foo
class PARENT3 is foo(INT):FLT; -- would similarly conflict
class CHILD is
include PARENT1 foo -> parent1_foo;
-- Include and rename away the routine 'foo'
include PARENT2 foo -> parent2_foo;
-- Include and rename away the routine 'foo'
include PARENT3;
-- Use the routine from this class |
|
- 2. The other way to resolve method conflicts is to explicitly define a method in the child class that will then over-ride all the parent methods.
| class CHILD is
include PARENT1;
include PARENT2;
include PARENT3;
foo(INT):BOOL is
-- over-rides all the included, conflicting routines. |
|
Conflicting Attributes
With conflicting attributes (including shareds and consts), the offending attributes must be renamed away, even if they are going to be replaced by other attributes i.e. Method 2 described above is not allowed for attributes:
| class PARENT is
attr foo:INT;
class CHILD is
foo:BOOL; -- ILLEGAL!
-- Conflicts with the included reader for 'foo' i.e. foo:INT |
|
Also the implicit reader and writer routines of attributes defined in the child must not conflict with routines in a parent
| class PARENT is
foo(arg:INT);
class CHILD is
include PARENT;
-- ILLEGAL! attr foo:INT;
-- the writer routine foo(INT) conflicts
-- with the writer for the include attribute foo(INT) |
|
In other words, as far as attributes are concerned, they must always be explicitly renamed away - they are never silently over-ridden.
5.7.6 Points to note
- It is not possible to overload based based solely on out or inout arguments (by the pre-condition for applying the overload rule 4a and 4b)
- When a class explicitly defines a signature and includes a conflicting signature from another class, the included signature is over-ridden. This might lead to included signatures unexpectedly disappearing, instead of overloading.
- In certain special cases, subtyping from two classes with conflicting signatures that use out or inout arguments might not be possible, since the conflict cannot be resolved.
5.7.7 Overloading in Parametrized Classes
The overloading rule for parametrized classes is discussed on page 112
5.7.8 Why not use the return type to resolve conflicts?
According to the current overloading rules, the type of the return value and out arguments cannot be used to differentiate between methods in the interface. There is no theoretical reason to disallow this possibility. However permitting overloading based on such return values involves significant implementation work and was not needed for the usages we envisaged. Thus, overloading is not permitted based on differences in the return type (or out arguments, which are equivalent to return types) of a method
5.8 When Covariance Ails You
In some cases, however, one type can substitute for the other type but with a few exceptions. There are several ways to deal with this problem when it occurs.
[This section attempts to provide some insight into dealing with covariance. It is not essential to understanding the language, but might help in the design of your type hierarchy.]
5.8.1 But don't animals eat food?
We will consider the definition of an animal class, where both herbivores and carnivores are animals.
| abstract class $ANIMAL is eat(food:$FOOD); ....
abstract class $HERBIVORE < $ANIMAL is...
abstract class $CARNIVORE < $ANIMAL is... |
|
The problem is similar to that in the previous section, but is different in certain ways that lead to the need for different solutions
5.8.2 Solution 1: Refactor the type hierarchy
The ideal solution would be to do what we did in the previous section - realize the conceptual problem and rearrange the type hierarchy to be more accurate. There is a difference in this case, though. When considering omnivores, the 'eat' operation was central to the definition of the subtyping relationship. In the case of animals, the eat operation is not nearly as central - the subtyping relationship is determined by many other features, completely unrelated to eating. It would be unreasonable to force animals to be subtypes of carnivores or herbivores.
5.8.3 Solution 2: Eliminate the offending method
A simple solution would be to determine whether we really need the 'eat' routine in the animal class. In human categories, it appears that higher level categories often contain features that are present, but vary greatly in the sub-categories. The feature in the higher level category is not "operational" in the sense that it is never used directly with the higher level category. It merely denotes the presence of the feature in all sub-categories.
Since we do not know the kind of food a general animal can eat, it may be reasonable to just omit the 'eat' signature from the definition of $ANIMAL. We would thus have
5.8.4 Solution 3: Dynamically Determine the Type
Another solution, that should be adopted with care, is to permit the 'eat($FOOD)' routine in the animal class, and define the subclasses to also eat any food. However, each subclass dynamically determines whether it wants to eat a particular kind of food.
| abstract class $ANIMAL is eat(arg:$FOOD); ...
abstract class $HERBIVORE < $ANIMAL is -- supports eat(f:$FOOD);
class COW < $HERBIVORE is
eat(arg:$FOOD) is
typecase arg
when $PLANT then .. -- eat it!
else raise "Cows only eat plants!"; end;
end;
end; |
|
The 'eat' routine in the COW class accepts all food, but then dynamically determines whether the food is appropriate i.e. whether it is a plant.
This approach carries the danger that if a cow is fed some non-plant food, the error may only be discovered at run-time, when the routine is actually called. Furthermore, such errors may be discovered after an arbitrarily long time, when the incorrect call to the 'eat' routine actually occurs during execution.
This loss of static type-safety is inherent in languages that support co-variance, such as Eiffel. The problem can be somewhat ameliorated though the use of type-inference, but there will always be cases where type-inference cannot prove that a certain call is type-safe.
Sather permits the user to break type-safety, but only through the use of a typecase on the arguments. Such case of type un-safety uses are clearly visible in the code and are far from the default in user code.
5.8.5 Solution 4: Parametrize by the Argument Type
Another typesafe solution is to parametrize the animal abstraction by the kind of food the animal eats.
Parametrized Classes and Arrays
All Sather classes may be parametrized by one or more type parameters. Type parameters are essentially placeholders for actual types; the actual type is only known when the class is actually used. The array class, which we have already seen, is an example of a parametrized class.Whenever a parameterized type is referred to, its parameters are specified by type specifiers. The class behaves like a non-parameterized version whose body is a textual copy of the original class in which each parameter occurrence is replaced by its specified type.
6.1 Parametrized concrete types
As an example of a parametrized class, consider the class PAIR, which can hold two objects of arbitrary types. We will refer to the types as T1 and T2:
| class PAIR{T1,T2} is
readonly attr first:T1;
readonly attr second:T2;
create(a_first:T1, a_second:T2):SAME is
res ::= new;
res.first := a_first;
res.second := a_second;
return res;
end;
end; |
|
We can use this class to hold a pair of integers or a pair of an integer and a real etc.
| c ::= #PAIR{INT,INT}(5,5); -- Holds a pair of integers
d ::= #PAIR{INT,FLT}(5,5.0); -- Holds an integer and a FLT
e ::= #PAIR{STR,INT}("this",5);-- A string and an integer
f:INT := e.second;
g:FLT := d.second; |
|
Thus, instead of defining a new class for each different type of pair, we can just parametrize the PAIR class with different parameters.
6.1.1 Why Parametrize?
Parametrization is normally presented as a mechanism for achieving efficiency by specializing code to use particular types. However, parametrization plays an even more important conceptual role in a language with strong typing like Sather.
For instance, we could define a pair to hold $OBs
| class OB_PAIR is
readonly attr first,second:$OB;
create(a_first, a_second:$OB):SAME is
res ::= new;
res.first := a_first;
res.second := a_second;
return res;
end;
end; -- class OB_PAIR |
|
There is no problem with defining OB_PAIR objects; in fact, it looks a little simpler.
| c ::= #OB_PAIR(5,5); -- Holds a pair of integers
d ::= #OB_PAIR(5,5.0); -- Holds an integer and a FLT |
|
However, when the time comes to extract the components of the pair, we are in trouble:
-- f:INT := e.second; ILLEGAL! second is declared to be a $OB
We can typecase on the return value:
| f_ob:$OB := e.second;
f:INT;
typecase f_ob when INT then f := f_ob end; |
|
The above code has the desired effect, but is extremely cumbersome. Imagine if you had to do this every time you removed an INT from an ARRAY{INT}! Note that the above code would raise an error if the branch in the typecase does not match.
The parametrized version of the pair container gets around all these problems by essentially annotating the type of the container with the types of the objects it contains; the types of the contained objects are the type parameter.
6.2 Support for Arrays
Arrays (and, in fact, most container classes) are realized using parametrized classes in Sather. There is language support for the main array class ARRAY{T} in the form of a literal expressions of the form
In addition to the standard accessing function, arrays provide many operations, ranging from trivial routines that return the size of the array to routines that will sort arbitrary arrays. See the array class in the container library for more details. There are several aspects to supporting arrays:
- Support for accessing array elements
- Support for objects which represent arrays
- Support for initializing these arrays using literals
6.2.1 Array Access
The form 'a[4]:=..' is syntactic sugar for a call of a routine named aset' with the array index expressions and the right hand side of the assignment as arguments. In the class TRIO below we have three elements which can be accessed using array notation
| class TRIO is
private attr a,b,c:FLT;
create:SAME is return new end;
aget(i:INT):FLT is
case i
when 0 then return a
when 1 then return b
when 2 then return c
else raise "Bad array index!\n"; end;
end;
aset(i:INT, val:FLT) is
case i
when 0 then a := val;
when 1 then b := val;
when 2 then c := val;
end;
end; |
|
.
The array notation can then be used with objects of type TRIO
| trio:TRIO := #TRIO; -- Calls TRIO::create
trio[2] := 1;
#OUT+trio[2]; -- Prints out 1 |
|
See the section on operator redefinition (page 118) for more details.
6.2.2 Array Classes: Including AREF and calling new();
Sather permits the user to define array classes which support an array portion whose size is determined when the array is created. An object can have an array portion by including AREF{T}.
| class POLYGON is
private include AREF{POINT}
aget->private old_aget, aset->private old_aset;
-- Rename aget and aset
create(n_points:INT):SAME is
-- Create a new polygon with a 'n_points' points
res:SAME := new(n_points); -- Note that the new takes
-- as argument of the size of the array
end;
aget(i:INT):POINT is
if i > asize then raise "Not enough polygon points!" end;
return old_aget(i);
end;
aset(i:INT, val:POINT) is
if i > asize then raise "Not enough polygon points!" end;
old_aset(i,val);
end;
end; |
|
Since AREF{T} already defines 'aget' and 'aset' to do the right thing, we can provide wrappers around these routines to, for instance, provide an additional warning message. The above example makex use of the POINT class from page 35. We could have also used the PAIR class defined on page 103. The following example uses the polygon class to define a triangle.
| poly:POLYGON := #POLYGON(3);
poly[0] := #POINT(3,4);
poly[1] := #POINT(5,6);
poly[2] := #POINT(0,0); |
|
AREF defines several useful routines:
| asize:INT -- Returns the size of the array
aelt!:T; -- Yields successive array elements
aelt!(once beg:INT):T; -- Yields elements from index 'beg'
aelt!(once beg,once num:INT):T; -- Yields 'num' elts from index 'beg'
aelt!(once beg,once num,once step:INT):T;
-- Yields 'num' elements, starting at index 'beg' with a 'step'
... Analgous versions of aset! ..
acopy(src:SAME); -- Copy what fits from 'src' to self
acopy(beg:INT,src:SAME); -- Start copying into index 'beg'
acopy(beg:INT,num:INT,src:SAME);
-- Copy 'num' elements into self starting at index 'beg' of self
aind!:INT; -- Yields successive array indices |
|
When possible, use the above iterators since they are built-in and can be more efficient than other iterators.
6.2.3 Standard Arrays: ARRAY{T}
The class ARRAY{T} in the standard library is not a primitive data type. It is based on a built-in class AREF{T} which provides objects with an array portion. ARRAY obtains this functionality using an include, but chooses to modify the visibility of some of the methods. It also defines additional methods such a contains, sort etc. The methods aget, aset and asize are defined as private in AREF, but ARRAY redefines them to be public.
| class ARRAY{T} is
private include AREF{T}
-- Make these public.
aget->aget,
aset->aset,
asize->asize;
...
contains(e:T):BOOL is ... end
...
end; |
|
The array portion appears if there is an include path from the type to AREF for reference types or to AVAL for immutable types.
Array Literals
Sather provides support for directly creating arrays from literal expressions
| a:ARRAY{INT} := |2,4,6,8|;
b:ARRAY{STR} := |"apple","orange"|; |
|
.
The type is taken to be the declared type of the context in which it appears and it must be ARRAY{T} for some type T. An array creation expression may not appear
- as the right hand side of a '::=' assignment
- as a method argument in which the overloading resolution is ambiguous
- as the left argument of the dot '.' operator.
a:INT := |1,2,3|.size -- ILLEGAL
The types of each expression in the array literal must be subtypes of T. The size of the created array is equal to the number of specified expressions. The expressions in the literal are evaluated left to right and the results are assigned to successive array elements.
6.2.4 Multi-dimensional Arrays
Special support is neither present nor needed for multi-dimensional arrays. The 'aget' and 'aset' routines can take multiple arguments, thus permitting multiple indices. The library does provide ARRAY2 and ARRAY3 classes, which provide the necesary index computation. All standard array classes are addressed in row-major order. However, the MAT class is addressed in column major order for compatibility with external FORTRAN routines[2] . Multi-dimensonal array literals may be expressed by nesting of standard array literals
| a:ARRAY{ARRAY{INT}} := ||1,2,3|,|3,4,5|,|5,6,7||; |
|
6.3 Type Bounds
When writing more complex parametrized classes, it is frequently useful to be able to perform operations on variables which are of the type of the parameter. For instance, in writing a sorting algorithm for arrays, you might want to make use of the "less than" operator on the array elements.If a parameter declaration is followed by a type constraint clause ('<' followed by a type specifier), then the parameter can only be replaced by subtypes of the constraining type. If a type constraint is not explicitly specified, then '< $OB' is taken as the constraint. A type constraint specifier may not refer to SAME'. The body of a parameterized class must be type-correct when the parameters are replaced by any subtype of their constraining types this allows type-safe independent compilation.
For our example, we will return to employees and managers. Recall that the employee abstraction was defined as:
| abstract class $EMPLOYEE is
name:STR;
id:INT;
end; |
|
We can now build a container class that holds employees. The container class makes use of a standard library class, a LIST, which is also parametrized over the types of things being held.
| class EMPLOYEE_REGISTER{ETP < $EMPLOYEE} is
private attr emps:LIST{ETP};
create:SAME is res ::= new; res.emps := #; return res; end;
add_employee(e:ETP) is emps.append(e); end;
n_employees:INT is return emps.size end;
longest_name:INT is
-- Return the length of the longest employee name
i:INT := 0;
cur_longest:INT := 0;
loop
until!(i=n_employees);
employee:ETP := emps[i];
name:STR := employee.name;
-- The type-bound has the ".name" routine
if name.size > cur_longest then
cur_longest := name.size;
end;
end;
return cur_longest;
end;
end; |
|
The routine of interest is "longest_name". The use of this routine is not important, but we can imagine that such a routine might be useful in formatting some printout of employee data. In this routine we go through all employees in the list, and for each employee we look at the "name". With the typebound on ETP, we know that ETP must be a subtype of $EMPLOYEE. Hence, it must have a routine "name" which returns a STR.
If we did not have the typebound (there is an implicit typebound of $OB), we could not do anything with the resulting "employee"; all we could assume is that it was a $OB, which is not very useful.
6.3.1 Why have typebounds?
The purpose of the type bound is to permit type checking of a parametrized class over all possible instantiations. Note that the current compiler does not do this, thus permitting some possibly illegal code to go unchecked until an instantiation is attempted.
6.3.2 Supertyping and Type Bounds
The need for supertyping clauses arises from our definitition of type-bounds in parametrized types. The parameters can only be instantiated by subtypes of their type bounds.
You may, however, wish to create a parametrized type which is instantiated with classes from an existing library which are not under the typebound you require. For instance, suppose you want to create a class PRINTABLE_ SET, whose parameters must support both hash and the standard string printing routine str. The library contains the following abstract classes.
| abstract class $HASH < $IS_EQ is hash:INT; end;
abstract class $STR is str:STR; end; |
|
However, our PRINTABLE_SET{T} must take all kinds of objects that support both $HASH and $STR, such as integers, floating point numbers etc. How do we support this, without modifying the distributed library?
| abstract class $HASH_AND_STR > INT, FLT, STR is
hash:INT;
str:STR;
end;
class PRINTABLE_SET{T < $HASH_AND_STR} is ...
-- Set whose elements can be printed
str:STR is
res:STR := "";
loop res := res+",".separate!(elt!.str); end;
return res;
end; |
|
The PRINTABLE_SET class can now be instantiated using integers, floating point numbers and strings. Thus, supertyping provides a way of creating supertypes without modifying the original classes (which is not possible if the original types are in a different library).
Note that this is only useful if the original classes cannot be modified. In general, it is usually far simpler and easier to understand if standard subtyping is used.
A more complicated example arises if we want to create a sorted set, whose elements must be hashable and comparable. From the library we have.
| abstract class $HASH < $IS_EQ is hash:INT; end;
abstract class $IS_LT{T} < $IS_EQ is -- comparable values
is_lt(elt:T):BOOL;
end; |
|
However, our SORTABLE_SET{T} must only take objects that support both $HASH and $IS_LT{T}
| abstract class $ORDERED_HASH{T} < $HASH, $IS_LT{T} is end;
class ORDERED_SET{T < $ORDERED_HASH{T}} is ...
-- Set whose elements can be sorted
sort is
-- ... uses the < routine on elements which are of type T
end; |
|
The above definition works in a straightforward way for user classes. For instance, a POINT class as defined below, can be used in a ORDERED_SET{POINT}
| class POINT < $ORDERED_HASH{POINT} is ....
-- define hash:INT and is_lt(POINT):BOOL |
|
But how can you create an ordered set of integers, for instance? The solution is somewhat laborious. You have to create dummy classes that specify the subtyping link for each different parametrization of $ORDERED_HASH
| abstract class $DUMMY_INT > INT < $ORDERED_HASH{INT} is end;
abstract class $DUMMY_STR > STR < $ORDERED_HASH{STR} is end;
abstract class $DUMMY_FLT > FLT < $ORDERED_HASH{FLT} is end; |
|
Note that the above classes are only needed because we are not directly modifying INT and FLT to subtype from $ORDRED_HASH{T}. In the following diagram , recall that since there is no relationship between different class parametrizations, it is necessary to think of them as separate types.
6.4 Parametrized Abstract Classes
Abstract class definitions may be parameterized by one or more type parameters within enclosing braces; in the example, the type parameter is 'T'. There is no implicit type relationship between different parametrizations of an abstract class. Parameter names are local to the abstract class definition and they shadow non-parameterized types with the same name. Parameter names must be all uppercase, and they may be used within the abstract type definition as type specifiers. Whenever a parameterized type is referred to, its parameters are specified by type specifiers. The abstract class definition behaves like a non-parameterized version whose body is a textual copy of the original definition in which each parameter occurrence is replaced by its specified type. Parameterization may be thought of as a structured macro facility
Sather abstract classes may be similarly parametrized by any number of type parameters. Each type parameter may have an optional type bound; this forces any actual parameter to be a subtype of the corresponding type bound. Given the following definitions,
| abstract class $A{T < $BAR} is
foo(b:T):T;
end; -- abstract class $A{T}
abstract $BAR is end;
class BAR < $BAR is end; |
|
we may then instantiate an abstract variable a:$A{BAR}. BAR instantiates the parameter T and hence must be under the type bound for T, namely$BAR. If a type-bound is not specified then a type bound of $OB is assumed.
How are different parametrizations related?
It is sometimes natural to want a $LIST{MY_FOO} < $LIST{$MY_FOO}. Sather, however, specifies no subtyping relationship between various parametrizations. Permitting such implicit subtyping relationships between different parametrizations of a class can lead to type safety violations.
6.5 Overloading
There are two aspects to the use of overloading in a parametrized class - one aspect is the behavior of the interface of the parametrized class itself, and the other aspect is calls within the parametrized class where one or more arguments have the type of one of the type parameters, or is related to the type parameters through static type inference (see .
6.5.1 Overloading In the Parametrized Class Interface
Argument with the type of a class parameter cannot be used to resolve overloading (such an argument is similar to an 'out' argument or a return type in this respect).
| class FOO{T1<$STR ,T2<$ELT} is
(1) bar(a:T1);
(2) bar(a:T2); |
|
Even though the type bounds for T1 and T2 are distinct and one is more specific than the other, this is not a sufficient constraint on the actual instantiation of the parameter. In a class such as
FOO{ARRAY{INT}, ARRAY{INT}}
for instance, the two versions of 'bar' will essentially be identical.
6.5.2 Overloading Resolution within the Parametrized Class
Note: The current ICSI compiler does not yet have this behaviour implemented. In the current compiler, overloading resolution is based on the actual instantiated class.
For all calls within the parametrized class, the resolution of overloading is done with respect to the type bounds of the parameters. Consider a class that makes use of output streams
| abstract class $OSTREAM is plus(s:$STR); end; |
|
A parametrized class can then write to any output stream
| class FOO{S < $OSTREAM} is
attr x,y:INT;
describe(s:S) is
s+"Self is:"; s+x; s+",";s+y;
end;
end; |
|
Now, suppose we instantiate the class FOO with a FILE
| class FILE < $OSTREAM is
(1) plus(s:$STR) is ...
(2) plus(s:INT) is ...
a:FOO{FILE} := ..
f:FILE := FILE::open_for_read("myfile");
a.describe(f) |
|
Only '(1) plus($STR)' will be called in FOO{FILE}, even though the more specific '(2) plus(INT)' is available in FILE.
The reason for this behavior is to preseve the ability to analyze a stand alone class, which is needed for separate compilation of parametrized classes - this requires that the behavior of the parametrized class be completely determined by the typebounds and not based on the existance of specialized overloaded routines in particular instantiations.
Operator Redefinition
7.1 Method Names for Operators
It is possible to define operators such as + and * to work with objects of arbitrary classes. These operators are transformed into standard routine calls in the class. Thus, if a class defines the routine 'plus' you can then apply the + operator to objects from that class. For instance, the complex number class POINT could define the plus routine to mean pairwise addition
| class POINT is
readonly attr x,y:INT;
create(x,y:INT):SAME is ... -- same as before
plus(s:POINT):POINT is return #POINT(x + s.x, y + s.y); end; |
|
we can now use the plus routine on two points
| p1:POINT := #POINT(3,5);
p2:POINT := #POINT(4,6);
p3:POINT := p1 + p2; -- p3 is set to the point 7,11 |
|
Most of the standard operators may be redefined; in some cases, redefining one operator such as the < operator implicitly redefines the associated >, >= and <= operators. These operators are meant to be used together in a consistent manner to indicate the mathematical notion of complete or partial ordering. They are not intended to be used as a convenient short-hand for other purposes.
7.2 Operator expressions
The following table shows how the standard operators are directly converted into routine calls
Binary Operators
| Operator | Routine | Operator | Routine |
| expr1 + expr2 | expr1.plus(expr2) | expr1 ^ expr2 | expr1.pow(expr2) |
| expr1 - expr2 | expr1.minus(expr2) | expr1 % expr2 | expr1.mod(expr2) |
| expr1 * expr2 | expr1.times(expr2) | expr1 < expr2 | expr1.is_lt(expr2) |
| expr1 / expr2 | expr1.div(expr2) | expr1 = expr2 | expr1.is_eq(expr2) |
.
Below are the routines that correspond to unary operators, for arithmetic and logical negation
Unary Operators
| Unary Operator | Routine |
| - expr | expr.negate |
| ~ expr | expr.not |
.
In addition to the unary and binary operators, there are additional operators that are defined in terms of a combination of the unary and binary operators
Compound Operators
| Operator | Translation | Operator | Translation |
| expr1 <= expr2 | expr2.is_lt(expr1).not | expr1 /= expr2 | expr1.is_eq(expr2).not |
| expr1 >= expr2 | expr1.is_lt(expr2).not | expr1 > expr2 | expr2.is_lt(expr1) |
[3].
The form '[expression list]' is translated into a call on the routine aget. For instance,
| a := [3,5]; -- Equivalent to a := aget(3,5); Used in the array class
f := arr[2]; -- Equivalent to f := arr.aget(2); Used outside the array |
|
This is described in more detail later.
Grouping
In addition to the above mentioned operators, it is possible to group expressions using plain parentheses, which have the highest precedence.
7.2.1 Operator precedence
The precedence ordering shown below determines the grouping of the syntactic sugar forms. Symbols of the same precedence associate left to right and parentheses may be used for explicit grouping. Evaluation order obeys explicit parenthesis in all cases.
| Strongest | . :: [] () |
| | ^ |
| | ~ Unary - |
| | * / % |
| | + Binary - |
| | < <= = /= >= > |
| Weakest | and or |
Points to note
- The >, >= and /= operators are not directly translated into their own routine. Rather, they are defined in terms of is_lt and is_eq.
- Each of these transformations is applied after the component expressions have themselves been transformed.
- 'out' and 'inout' modes may not be used with the syntactic sugar expressions.
- The '<=' and '>' expressions do not reverse the original left to right order of argument evaluation.
- and' and or' are not listed as syntactic sugar for operations in BOOL'; this allows short-circuiting the evaluation of subexpression.
- The aget and aset routines are meant to support array like indexed access and require at least one index argument.
Syntactic sugar example
Here's a formula written with syntactic sugar and the calls it is textually equivalent to. It doesn't matter what the types of the variables are; the sugar ignores types.
| -- Written using syntactic sugar
r := (x^2 + y^2).sqrt;
-- Written without sugar
r := (x.pow(2).plus(y.pow(2))).sqrt |
|
7.3 Array Access Routines
Sather supports the standard array access syntax of square brackets. For instance:
| a:ARRAY{INT} := |1,2,3|;
a[2] := 5; -- Sets the third element of the array to 5
#OUT+a[0]; -- Prints out '1'
c:ARRAY2{INT} := ||1,2,3|,|4,5,6|,|7,8,9||;
#OUT + c[2,2]; -- Prints out '9' |
|
However, the array bracket notation is not built into the array class. It is just a short hand for the routines aget and aset
| a[2] := 5; -- equivalent to a.aset(2,5);
#OUT+a[1]; -- equivalent to #OUT+a.aget(1); |
|
Thus, classes which are not arrays can make use of the array notation as they please:
| class INT is
-- The standard integer class
aget(i:INT):BOOL is -- returns the 'i'th bit of the integer
end; |
|
In order for a class to actually have an array portion, it must inherit from AREF{T} (if it is a reference class) or AVAL{T} if it is a value class. The array setting notation is not as useful for immutable classes, since any modification of an immutable class must return a whole new object.
Immutable Classes
Sather has special support for classes that define immutable objects. Such objects cannot be modified after they have been created, and are said to have value semantics. Many of the basic types such as integers and floating point numbers (the INT and FLT classes) are implemented using immutable classes. This chapter illustrates how immutable classes may be defined, and highlights the peculiarities in their usage that may trip up a beginning user.
At a fundamental level: immutable classes define objects which, once created, never change their value. A variable of an immutable type may only be changed by re-assigning to that variable. When we wish to only modify some portion of an immutable class, we are compelled to reassign the whole object. For experienced C programmers the difference between immutable and reference classes is similar to the difference between structs (immutable types) and pointers to structs (reference types). Because of that difference, reference objects can be referred to from more than one variable (aliased), while immutable objects cannot.
This section illustrates the definition of immutable types using a simple version of the complex number class, CPX. We also describe the benefits of immutable classes and when they should be used. Finally, we close with a description of a how to transparently replace in immutable class by a standard reference class which implements value semantics.
8.1 Defining Immutable Classes
In most ways, defining and using immutable classes is similar to defining and using reference classes. Immutable classes consist of a collection of attributes and functions that can operate on the attributes. Since we have already described reference classes in considerable detail, we will describe immutable classes in terms of their differences from reference classes.
8.1.1 Immutable Class Example
We illustrate the use of immutable classes through the example of the complex class CPX. The version shown here is a much simplified version of the library class. The key point to note is the manner in which attribute values are set in the create routine.
| immutable class CPX is
readonly attr real,imag:FLT;
create(re,im:FLT):SAME is
-- Returns a complex number with real and imaginary parts set
res:SAME;
res := res.real(re);
res := res.im(im);
return res;
end;
plus(c:SAME):SAME is
-- Return a complex number, the sum of 'self' and c'.
return #SAME(real+c.real,imag+c.imag);
end;
end; -- immutable class CPX |
|
The complex class may then be used in the following manner.
| b:CPX := #(2.0,3.0);
d:CPX := #(4.0,5.0);
c:CPX := b+d; |
|
8.1.2 Creating a new object
Unlike reference classes, instances of an immutable class are not explicitly allocated using the 'new' expression. A variable of an immutable class always has a value associated with it, from the point of declaration. In the example above, the return variable of the create routine ,'res' simply has to be declared.
8.1.3 Initial value of immutable objects
The initial value of an immutable object is defined to have all its fields set to the 'void' value and this is defined to be the 'void' value of the immutable object. Note that this 'void' value means something different than it does for a reference class. It does not mean that the object does not exist, but rather that all its fields have the 'void' value.
Void value of the basic classes:
| Class | Initial Value | Class | Initial Value |
| INT | 0 | CHAR | '\0' |
| FLT | 0.0 | FLTD | 0.0d |
| BOOL | false | | |
The initial values for the built-in immutable classes are defined above. These values will return true for the 'void' test.
8.1.4 Attribute access routines
Since an immutable object cannot change its value, what does assigning to an attribute mean? Sather's immutable classes define attribute assignment to create a copy of the original object, with the attribute modified. Thus the attribute declaration 'attr re:FLT ' of the CPX class has an implicit attribute setting routine with the signature:
which returns a copy of the original CPX object in which the attribute 're' has the new value 'new_re_value'. Contrast this with a reference class, in which the setting routine would have the signature
The syntax of the setting routines of immutable classes is a common source of confusion.
8.1.5 Points to note
- There must be no cycle of immutable types such that each type has an attribute whose type is in the cycle. In the following example, the class PAIR has a FIRST_PART that contains a PAIR - leading to an infinite loop and an infinite size structure.
| immutable class PAIR is
attr first:FIRST_PART;
attr second:SECOND_PART; ...
immutable class FIRST_PART is
attr begin:PAIR;... |
|
- Accessing an attribute of a void immutable object will always work. Accessing an attribute of a void reference object results in a fatal error
- The 'void' value for the basic classes are useful values - false is the 'void' value for the BOOL class, and 0 for the number classes.
8.2 Using Immutable Classes
Immutable classes behave differently from reference classes both in terms of their abstract behaviour (value semantics) and in terms of their implementation.
To begin with, immutable classes cannot suffer from aliasing problems, since they are immutable. You can get the same effect with reference classes by not providing any modifying operations in the interface - any operation that would modify the object, returns a new object instead. For example, take a look at the STR class
Immutable classes may have several efficiency advantages over reference classes in certain circumstances. Since they are usually stored on the stack, they have no heap management overhead and need not be garbage collected. They also don't use space to store a tag, and the absence of aliasing makes more C compiler optimizations possible. For a small class like CPX, all these factors combine to give a significant win over a reference class implementation. On the other hand, copying large immutable objects onto the stack can incur significant overhead. Unfortunately the efficiency of an immutable class appears directly tied to how smart the C compiler is; "gcc" is not very bright in this respect.
Note that when an immutable class is passed as an argument to a function which is expecting an abstract type, the compiler boxes it i.e. it is given a temporary reference class wrapper with a type-tag. Thus, immutable objects behaves exactly like an immutable reference objects in this situation.
Rules of Thumb
So, when should you use an immutable class? Here are a few rules of thumb.
- You want the class to have immutable semantics. You could still consider an immutable reference class.
- The class is small - the exact speed trade-offs have not been investigated, but immutable classes have so far been used when there are a fewer than a handful of attributes.
- There are going to be a large number of objects of that class. This goes along with the previous point. For instance, if you are going to have large arrays of complex numbers, then the space that would be required for an object pointer and an object tag may be considerable.
Closures
Routine and iter closures are similar to the 'function pointer' and 'closure' constructs of other languages. They bind a reference to a method together with zero or more argument values (possibly including self). The type of a closure begins with the keywords ROUT or ITER and followed by the modes and types of the underscore arguments, if any, enclosed in braces (e.g. 'ROUT{A, out B, inout C}', 'ITER{once A, out B, C}'). These are followed by a colon and the return type, if there is one (e.g. 'ROUT{INT}:INT', 'ITER{once INT}:FLT').
9.1 Creating and Calling Closures
9.1.1 Creating a closure
A closure is created by an expression that binds a routine or an iterator, along with some of its arguments. The outer part of the expression is 'bind(...)'. This surrounds a routine or iterator call in which any of the arguments or self may have been replaced by the underscore character '_'. Such unspecified arguments are unbound. Unbound arguments are specified when the closure is eventually called.
| a:ROUT{INT}:INT := bind(3.plus(_))
b:ITER:INT := bind(3.times!); |
|
Out and inout arguments must be specified in the closure type. If the routine has inout or out arguments
| swap(inout x, inout y:INT) is tmp::= x; x := y; y:=tmp; end; |
|
as show below, they are mentioned in the type of the closure:
The routine 'swap' swaps the values of the two arguments, 'x' and 'y'. 'r' is a closure for binding the 'swap' routine.
| r:ROUT{inout INT, inout INT} := bind(swap(_,_)); |
|
9.1.2 Calling a closure
Each routine closure defines a routine named 'call' and each iterator closure defines an iterator named 'call!'. These have argument and return types that correspond to the closure type specifiers. Invocations of these features behave like a call on the original routine or iterator with the arguments specified by a combination of the bound values and those provided to call or call!. The arguments to call and call! match the underscores positionally from left to right .
The previously defined closures are invoked as shown
| #OUT+ a.call(4); -- Prints out 7, where a is bind(3.plus(_)
sum:INT := 0;
loop sum := sum + b.call!; end;
#OUT+sum; -- Prints out 3 (0+1+2) |
|
In the following example, we define a bound routine that takes an INT as an argument and returns an INT.
| br:ROUT{INT}:INT := bind(1.plus(_));
#OUT+br.call(9); -- Prints out '10' |
|
The variable br is typed as a bound routine which takes an integer as argument and returns an integer. The routine 1.plus, which is of the appropriate type, is then assigned to br. The routine associated with br may then be invoked by the built in function call. Just as we would when calling the routine INT::plus(INT), we must supply the integer argument to the bound routine.
9.1.3 Binding overloaded routines
When binding a routine which is overloaded, there might be some ambiguity about which routine is meant to be bound
| class FLT is
plus(f:FLT):FLT -- add self and 'i' and return the result
plus(i:INT):FLT; -- add self and 'f' (after converting 'i' to FLT)
end; |
|
When binding the plus routine, it might not be obvious which routine is intended
In case of ambiguity, the right method must be determined by the context in which the binding takes place.
Binding in an assignment
If there is ambiguity about which method is to be bound, the type of the variable must be explicitly specified
| b:ROUT{FLT,FLT}:FLT := bind(_.plus(_)); -- Selects the first 'plus' |
|
Binding in a call
A method may also be bound at the time a call is made. The type of the closure is determined by the type of the argument in the call.
| reduce(a:ARRAY{FLT}, br:ROUT{FLT,FLT}:FLT):FLT is
res:FLT := 0.0;
loop el:FLT := a.elt!; res := br.call(res,el); end;
return res;
end; |
|
We can call the reduction function as follows:
| a:ARRAY{FLT} := |1.0,7.0,3.0|;
#OUT + reduce(a,bind(_.plus(_)));
-- Prints '11.0', the sum of the elements of 'a' |
|
The second argument to the function reduce expects a ROUT{FLT,FLT}:FLT and this type was used to select which plus routine should be bound. When there could be doubt about which routine is actually being bound, it is very good practice to specify the type explicitly
| r:ROUT{FLT,FLT}:FLT := bind(_.plus(_));
#OUT+reduce(a,r); |
|
9.1.4 Points to note
- out and inout arguments must be left unbound. This is a reasonable restriction, since such arguments must return a value to the calling context. If such an argument were bound, when the closure is invoked, variables that existed at the point of closure binding would be affected. Such variables might not even be alive at the point where the closure is actually invoked.
9.1.5 Binding some arguments
When a routine closure is created, it can preset some of the values of the arguments.
| class MAIN is
foo(a:INT, b:INT):INT is return(a+b+10) end;
main is
br1:ROUT{INT,INT}:INT := bind(foo(_,_));
br2:ROUT{INT}:INT := bind(foo(10,_));
#OUT+br1.call(4,3)+","+br2.call(9); -- Should print 17 and 29
end;
end; |
|
In the example above, br2 binds the first argument of foo to 10 and the second argument is left unbound. This second argument will have to be supplied by the caller of the bound routine. br1 binds neither argument and hence when it is called, it must supply both arguments.
Here we double every element of an array by applying a routine closure r to each element of an array.
| r :ROUT{INT}:INT := bind(2.times(_));
loop
a.set!(r.call(a.elt!))
end |
|
9.1.6 Leaving self unbound
bound routines are often used to apply a function to arbitrary objects of a particular class. For this usage, we need the self argument to be unbound. This illustrates how self may be left unbound. The type of self must be inferred from the type context (ROUT{INT}).
| r :ROUT{INT} := bind(_.plus(3));
#OUT + r.call(5); -- prints '8' |
|
In the following example we will make use of the plus routine from the INT class.
| ... from the INT class
plus(arg:INT):INT is ... definition of plus
main is
plusbr1:ROUT{INT,INT}:INT:=bind(_.plus(_)); -- self and arg unbound
br1res:INT := plusbr1.call(9,10); -- Returns 19
plusbr2:ROUT{INT}:INT := bind(3.plus(_)); -- Binding self only
br2res:INT := plusbr2.call(15); -- Returns 18
plusbr3:ROUT{INT}:INT := bind(_.plus(9)); -- Binding arg only
br3res:INT := plusbr3.call(11); -- Returns 20
#OUT+br1res+","+br2res+","+br3res; -- 19,18,20
end; |
|
In the above example, plusbr1 leaves both self and the argument to plus unbound. Note that we must specify the type of self when creating the bound routine, otherwise the compiler cannot know which class the routine belongs to (the type could also be an abstract type that defines that feature in its interface). plusbr2 binds self to 3, so that the only argument that need be supplied at call time is the argument to the plus. plusbr3 binds the argument of plus to 15, so that the only argument that need be supplied at call time is self for the routine.
9.2 Further Examples of Closures
Just as is the case with C function pointers, there will be programmers who find closures indispensible and others who will hardly ever touch them. Since Sather's closures are strongly typed, much of the insecurity associated with function pointers in C disappears.
9.2.1 Closures for Applicative Programming
Closures are useful when you want to write Lisp-like "apply" routines in a class which contains other data . Routines that use routine closures in this way may be found in the class ARRAY{T}. Some examples of which are shown below.
| every(test:ROUT{T}:BOOL):BOOL is
-- True if every element of self satisfies 'test'.
loop
e ::= elt!; -- Iterate through the array elements
if ~test.call(e) then return false end
-- If e fails the test, return false immediately
end;
return true
end; |
|
The following routine which takes a routine closure as an argument and uses it to select an element from a list
| select(e:ARRAY{INT}, r:ROUT{INT}:BOOL):INT is
-- Return the index of the first element in the array 'e' that
-- satisfies the predicate 'r'.
-- Return -1 if no element of 'e' satisfies the predicate.
loop i:INT := e.ind!;
if r.call(e[i]) then return i end;
end;
return -1;
end;
|
|
The selection routine may be used as shown below:
| a:ARRAY{INT} := |1,2,3,7|;
br:ROUT{INT}:BOOL := bind(_.is_eq(3));
#OUT + select(a,br); -- Prints the index of the first element of 'a'
-- that is equal to '3'. The index printed is '2' |
|
9.2.2 Menu Structures
Another common use of function pointers is in the construction of an abstraction for a set of choices. The MENU class shown below maintains a mapping between strings and routine closures associated with the strings.
| class MENU is
private attr menu_actions:MAP{STR,ROUT};
-- Hash table from strings to closures
private attr default_action:ROUT{STR};
create(default_act:ROUT{STR}):SAME is
res:SAME := new;
res.menu_actions := #MAP{STR,ROUT};
res.default_action := default_act;
return(res)
end;
add_item(name:STR, func:ROUT) is menu_actions[name] := func end;
-- Add a menu item to the hash table, indexed by 'name'
run is
loop
#OUT+">";
command: STR := IN::get_str; -- Gets the next line of input
if command = "done" then break!
elsif menu_actions.has_ind(command) then
menu_actions[command].call;
else
default_action.call(command);
end;
end;
end;
end; |
|
We use this opportunity to create a textual interface for the calculator described on page 80:
| class CALCULATOR is
private attr stack:A_STACK{INT};
private attr menu:MENU;
create:SAME is res ::= new; res.init; return res; end;
private init is -- Initialize the calculator attributes
stack := #;
menu := #MENU(bind(push(_)));
menu.add_menu_item("add",bind(add));
menu.add_menu_item("times",bind(times));
end;
run is menu.run; end;
....
|
|
The main routines of the calculator computation are:
| push(s:STR) is
-- Convert the value 's' into an INT and push it onto the stack
-- Do nothing if the string is not a valid integer
c: STR_CURSOR := s.cursor;
i: INT := c.int;
if c.has_error then #ERR+"Bad integer value:"+s;
else stack.push(i); end;
end;
add is -- Add the two top stack values and push/print the result
sum:INT := stack.pop+stack.pop;
#OUT+sum+"\n";
stack.push(sum);
end;
times is -- Multiply the top stack values and push/print the result
product:INT := stack.pop*stack.pop;
#OUT+product+"\n";
stack.push(product);
end;
end; -- class CALCULATOR |
|
This calculator can be started by a simple main routine
| class MAIN is main is c: CALCULATOR := #; c.run; end;end; |
|
:
After compiling the program, we can then run the resulting executable
| pts/1 samosa:~/Sather>a.out
>3
>4
>add
7
>10
>11
>times
110
>done
pts/1 samosa:~/Sather> |
|
9.2.3 Iterator closures
Exceptions
Exceptions are used to escape from method calls under unusual circumstances. For example, a robust numerical application may wish to provide an alternate means of solving a problem under unusual circumstances such as ill conditioning. Exceptions bypass the ordinary way of returning from methods and may be used to skip over multiple callers until a suitable handler is found.
10.1 Throwing and Catching Exceptions
There are two aspects to indicating errors using exceptions - how the error is indicated at the point where it occurs. This is usually referred to as throwing the exception. The other aspect of exceptions is how the error message is handled, which is referred to as catching the exception.
10.1.1 Throwing Exceptions with raise
Exceptions are explicitly raised by raise statements. The raise statement specifies an expression, which is evaluated to obtain the exception object.
| add_if_positive(i:INT) is
if i < 0 then
raise "Negative value:"+i+"\n";
end;
end; |
|
In the example above, the object happens to be a string that indicates the problem. In general, the exception object must provide enough information for the error handling mechanism. Since the error handling mechanism can discriminate between different objects of different types, it is standard practice to use the type of the exception object to indicate the type of the error that occurred.
10.1.2 Catching Exceptions with protect
Exceptions are passed to higher contexts until a handler is found and the exception is caught. Exceptions are caught using protect statements. The protect statement surrounds a piece of code, and provides an appropriate method of handling any exceptions that might occur when executing that piece of code.
| protect
foo;
when $STR then #ERR+"An error in foo!:"+exception.str;
when INT then #ERR+"INT error="+exception; -- 'exception' of type INT
else
-- Some other error handling
end; |
|
When there is an uncaught exception in a protect statement, the system finds the first type specifier listed in the 'when' lists which is a supertype of the exception object type. The statement list following this specifier is executed and then control passes to the statement following the protect statement.
In the protect clause, the exception raised may be referred to by the built in expression 'exception'[4], which refers to the exception object. The type of the exception object can be used to categorize the exception and to discriminate between exceptions when they are actually caught. In fact, the when clauses may be viewed as a typecase (see page 90) on the exception object.
Points to note
- No statements may follow a raise statement in a statement list because they can never be executed.
- If there is no else clause in a protect statement, and none of the types in the when branches matches the type of the exception object, then the exception is passed to the next higher protect statement
10.1.3 Usage to avoid
Exceptions can be significantly slower than ordinary routine calls, so they should be avoided except for truly exceptional (unexpected) cases. Using exceptions to implement normal control flow may be tempting, but should be avoided. For instance, in the STR_CURSOR class, we can make use of exceptions for parsing. It might be tempting to write code like the following
| test_bool:BOOL is
protect
current_state ::= save_state;
b ::= get_bool;
restore_state(current_state);
when STR_CURSOR_EX then return(false); end;
return(true);
end; |
|
The above code determines whether a boolean is present in the string by trying to read one and treating an error state as evidence that there is no boolean. While it is perfectly correct code, this is an example of what you should not do. The implementation of a function should not rely on exceptions for its normal functioning. Doing so is extremely inefficient and can result in an unnecessarily complicated flow of control.
10.1.4 Alternatives to Exceptions
The alternative to using exceptions is to use a sticky error flag in the class, as is done by IEEE exceptions and the current FILE classes. This has problems such as the fact that the outermost error is logged, not the most immediate one, and it is very easy to forget to test for the error. However, this method has a much lower overhead and is suitable in certain cases.
10.2 A more elaborate example
Consider the following routine, which tries to read a boolean value from a string:
| get_bool(file_name:STR):BOOL is
f:FILE := FILE::open_for_read(file_name);
if f.error then raise #FILE_OPEN_EXC(file_name); end;
s:STR := f.str; -- Read the file into a string
f.close; -- Close the file
res:BOOL;
bool ::= "";
i:INT := 0;
loop until!(~(s[i].is_alpha) or (s[i].is_space) or i >= s.size);
bool := bool + s[i]; i := i + 1;
end;
case bool
when "true","t","True","T","TRUE" then return true;
when "false","f","False","F","FALSE" then return false;
else
raise #PARSE_BAD_BOOL_EXC(s);
end;
end; |
|
In the above routine there are two possible errors - either the file could not be opened or it does not contain a valid boolean. The two cases can be distinguised at the point when the exception is caught
| protect
file_name:STR; ... set to a value
b:BOOL := get_bool(s);
when FILE_OPEN_EXC then #ERR+"Could not open:"+exception.file_name+"\n";
when PARSE_BAD_BOOL_EXC then
#ERR+"Error in reading boolean:"+exception.str+"\n";
end; |
|
The classes that implement these exceptions can be fairly simple
| class FILE_OPEN_EXC is
readonly attr str:STR:
create(file_name:STR):SAME is
res::=new; res.str := file_name; return res;
end;
end; |
|
The other exception class is very similar.
Safety Features
Methods definitions may include optional pre- and post-conditions. Together with 'assert' and these features allow the earnest programmer to annotate the intention of code. The Sather compiler provides facilities for turning on or off the runtime checking these safety features imply. Classes may also define a routine named 'invariant', which is a post condition that applies to all public methods.
These safety features are associated with the notion of programming contracts. The precondition of a method is the contract that the method requires the caller to fulfill. It is a statement of the condition of the world that the method needs to find, in order to work correctly. The postcondition is a contract that the method guarantees, if its precondition has been met. It is a statement of the state the method will leave the world in, when it is finished executing. These programming contracts are very important in the creation of robust, reusable code.
In addition to providing a level of checking, these safety features are also an invaluable form of documentation. Since preconditions and postconditions must actually execute, they can be trusted to be accurate and up-to-date, unlike method comments which may easily fall out of sync with the code.
11.1 Preconditions
A precondition states the assumptions that a method makes. It is the contract that the caller must fullfil in order for the routine to work properly. Preconditions frequently include checks that an argument is non-zero or non-void.
The optional 'pre' construct of method definitions contains a boolean expression which must evaluate to true whenever the method is called; it is a fatal error if it evaluates to false.The expression may refer to self and to the routine's arguments. For iterators, pre and post conditions are checked before and after every invocation of the iterator (not just the first or last time the iterator is called).
| class POSITIVE_INTERVAL is
readonly attr start, finish:INT;
create(start, finish:INT)
-- Ensure that the interval is positive on positive numbers
pre start > 0 and finish > 0 and finish-start >= 0
is
res ::= new;
res.start := start;
res.finish := finish;
return res;
end;
end; -- class POSITIVE_INTERVAL |
|
Note that it is usually not appropriate to place conditions on the internal state in the precondition. This is an inappropriate conduct, since it may be impossible for the caller to determine whether the conduct can be properly fulfilled.
| move_by(i:INT) pre start > 0 is ... |
|
The test on 'start' is actually verifying something about the internal state of the object, and has nothing to do with the caller of the routine. Tests such as the one above are more appropriately placed in assertions.
11.2 Postconditions
Post conditions state what a method guarantees to the caller. It is the method's end of the contract. Post conditions are also stated as an optional initial construct in a method.
The optional 'post' construct of method definitions contains a boolean expression which must evaluate to true whenever the method returns; it is a fatal error if it evaluates to false. The expression may refer to self and to the method's arguments.
| class VECTOR is
...
norm:FLT; -- norm of the vector
normalize post norm = 1.0 is ...
-- Normalize the vector. The norm of the result must be 1.0 |
|
It is frequently useful to refer to the values of the arguments before the call, as well as the result of the method call. A problem arises because the initial argument values are no longer known by the time the method terminates, since they may have been arbitrarily modified. Also, since the post condition is outside the scope of the method body, it cannot easily refer to values which are computed before the method executes. The solution to this problem consists of using result expressions which provide the return value of the method and initial expressions which are evaluated at the time the method is invoked.
11.2.1 initial expressions
initial expressions may only appear in the post expressions of methods.
| add(a:INT):INT post initial(a)>result is .. |
|
The argument to the initial expression must be an expression with a return value and must not itself contain initial expressions. When a routine is called or an iterator resumes, it evaluates each initial expression from left to right. When the postcondition is checked at the end, each initial expression returns its pre-computed value.
11.2.2 result expressions
Result expressions are essentially a way to refer to the return value of a method in a postcondition (the post condition is outside the scope of the routine and hence cannot access variables in the routine).
| sum:INT post result > 5 is . -- Means that the value return must be > 5 |
|
Result expressions may only appear within the postconditions of methods that have return values and may not appear within initial expressions. A result expression returns the value returned by the routine or yielded by the iterator. The type of a result expression is the return type of the method in which it appears (INT, in the above example).
11.2.3 Example
The above routine maintains an (always positive) running sum in 'sum'. Only positive numbers are added to the sum, and the result must always be bigger than the argument.
| class CALCULATOR is
readonly attr sum:INT; -- Always kept positive
add_positive(x:INT):INT pre x > 0 post result >= initial(x) is
return sum + x; end;
|
|
11.3 Assertions
Assertions are not part of the interface to a routine. Rather, they are an internal consistency check within a piece of code, to ensure that the computation is proceeding as expected.
11.3.1 assert statements
assert statements specify a boolean expression that must evaluate to true; otherwise it is a fatal error.
| private attr arr:ARRAY{INT};
...
sum_of_elts is
--
sum:INT := 0;
loop e ::= arr.elt!;
assert e > 0;
sum := sum + e;
end;
return sum;
end; |
|
In the above piece of code, we expect the class to only be storing postive values in the array 'arr' . To double check this, when adding the elements together, we check whether each element is positive.
11.4 Invariants
A class invariant is a condition that should never be violated in any object, after it has been created. Invariants have not proven to be as widely used as pre- and post- conditions, which are quite ubiquitous in Sather code.
11.4.1 The invariant routine
If a routine with the signature 'invariant:BOOL', appears in a class, it defines a class invariant. It is a fatal error for it to evaluate to false after any public method of the class returns, yields, or quits.
Consider a class with a list (we use the library class A_LIST) whose size must always be at least 1. Such a situtation could arise if the array usually contains the same sort of elements and we want to use the first element of the array as a prototypical element)
| class PROTO_LIST is
private attr l:A_LIST{FOO};
create(first_elt:FOO):SAME is
res ::= new;
res.l := #;
res.l.append(first_elt);
return res;
end;
invariant:BOOL is return l.size > 0 end;
delete_last:FOO is return l.delete_elt(l.size-1); end; |
|
If the 'delete_last' operation is called on the last element, then the assertion will be violated and an error will result.
| proto:FOO := #; -- Some FOO object
a:PROTO_LIST := #(FOO);
last :FOO := a.delete_last;
-- At runtime, an invariant violation will occur
-- for trying to remove the last element. |
|
The invariant is checked at the end of every public method. However, the invariant is not checked after a private routine. If we have the additional routines
| delete_and_add is f :FOO
res ::= internal_delete_last;
l.append(res);
return res;
end;
private internal_delete_last:FOO is
return l.delete_elt(l.size-1);
end; |
|
Now we can call 'delete_and_add'
| proto:FOO := #;
a:PROTO_LIST := #(FOO);
last:FOO := a.delete_and_add; -- does not violate the class invariant |
|
The private call to 'internal_delete_last' does violate the invariant, but it is not checked, since it is a private routine.
Built-in classes
This section provides a short description of classes that are a part of every Sather implementation and which may not be modified. The detailed semantics and precise interface are specified in the class library documentation.
12.1 Fundamental Classes
There are a handful of classes that are specially recognized by the compiler and are implicitly and explicitly used in most Sather code.
12.1.1 $OB
'$OB' is automatically a supertype of every type. Variables declared to be of this type may hold any object. It has no features.
12.1.2 Array support
Sather objects may have an array portion, which is specified by including either the primitive reference of value array
- 'AREF{T}' is a reference array class. Any reference class which includes it obtains an array of elements of type T in addition to any attributes it has defined. In such classes, new has a single integer argument that specifies the size of the array portion. It defines routines and iters named: 'asize', 'aget', 'aset', 'aclear', 'acopy', 'aelt!', 'aset!', and 'aind!'. Array indices start at zero.
- 'ARRAY{T}' includes from 'AREF' and defines general purpose array objects. They may be directly constructed by array creation expressions.
- 'AVAL{T}' is the immutable class analog of 'AREF'. Classes which include 'AVAL' must define asize as an integer constant which determines the size of the array portion.
12.2 Tuples
Tuples are not really a fundamental class, but are commonly used for a very fundamental purpose - multiple return values.
'TUP' names a set of parameterized immutable types called tuples, one for each number of parameters. Each has as many attributes as parameters and they are named 't1', 't2', etc. Each is declared by the type of the corresponding parameter (e.g. 'TUP{INT,FLT}' has attributes 't1:INT' and 't2:FLT'). It defines 'create' with an argument corresponding to each attribute.
12.3 The SYS Class
SYS defines a number of routines for accessing system information:
Operation in the SYS class
| Routine | Description |
| is_eq(ob1, ob2:$OB):BOOL | Tests two objects for equality. If the arguments are of different type, it returns 'false'. If both objects are immutable, this is a recursive test on the arguments' attributes. If they are reference types, it returns 'true' if the arguments are the same object. It is a fatal error to call with external, closure, or void reference arguments. |
| is_lt(ob1, ob2:$OB):BOOL | Defines an arbitrary total order on objects. This never returns true if 'is_eq' would return true with the same arguments. It is a fatal error to call with external, closure, or void reference arguments. |
| hash(ob:$OB):INT | Defines an arbitrary hash function. For reference arguments, this is a hash of the pointer; for immutable types, a recursive hash of all attributes. Hash values for two objects are guaranteed to be identical when 'is_eq' would return true, but the converse is not true. |
| type(ob:$OB):INT | Returns the concrete type of an object encoded as an 'INT'. |
| str_for_type(i:INT):STR | Returns a string representation associated with the integer. Useful for debugging in combination with 'type' above. |
| destroy(ob:$OB) | Explicitly deallocates an object. Sather is garbage collected and casual use of 'destroy' is discouraged. Sather implementations provide a way of detecting accesses to destroyed objects (a fatal error). |
12.4 Object Finalization: $FINALIZE
$FINALIZE defines the single routine finalize. Any class whose objects need to perform special operations before they are garbage collected should subtype from $FINALIZE. The finalize routine will be called once on such objects before the program terminates. This may happen at any time, even concurrently with other code, and no guarantee is made about the order of finalization of objects which refer to each other. Finalization will only occur once, even if new references are created to the object during finalization. Because few guarantees can be made about the environment in which finalization occurs, finalization is considered dangerous and should only be used in the rare cases that conventional coding will not suffice.
12.5 Basic Classes and Literal Forms
The basic Sather classes such as integers and booleans are not treated specially by the compiler. However, they do have language support in the form of convenient literal forms that permit easy specification of values. These literal forms all have a concrete type derived from the syntax; typing of literals is not dependent on context. Each of these basic classes also has a default void initial value.
| Type | Initial value | Description |
| BOOL | false | Immutable objects which represent boolean values. |
| CHAR | '\0' | Immutable objects which represent characters. The number of bits in a 'CHAR' object is less than or equal to the number in an 'INT' object. |
| STR | "" (void) | Reference objects which represent strings for characters. 'void' is a representation for the null string. |
| INT | 0 | Immutable objects which represent efficient integers. The size is defined by the implementation but must be at least 32 bits. Bit operations are supported in addition to numerical operations. |
| INTI | 0i | Reference objects which represent infinite precision integers. |
| FLT | 0.0 | Immutable objects which represent single precision floating point values as defined by the IEEE-754-1985 standard. |
| FLTD | 0.0d | Immutable objects for double precision floating point values. |
12.5.1 Booleans and the BOOL class
| Examples: | a:BOOL := true |
| | b ::= false; |
| | c:BOOL := a.and(b); |
| | if a.and(b).or(d) then |
| | end; |
BOOL objects represent boolean values (page 143). The two possible values are represented by the boolean literal expressions: 'true' and 'false'. Boolean objects support the standard logical operations. Note that these logical operations are evaluated in the standard way, and not short-circuited. The Sather expressions "and" and "or" provide a short circuit logical operations.
| if b.has_value and b.get_value > 3 then
-- The short circuit and will only evaluate b.get_value
-- if b.has_value is true
end; |
|
12.5.2 Characters and the CHAR class
| Examples: | c:CHAR := 'a' |
| | new_line:CHAR := '\n'; |
| | code_16:CHAR := '\016'; |
CHAR objects represent characters (page 143). Character literal expressions begin and end with single quote marks. These may enclose either any single ISO-Latin-1 printing character except single quote or backslash or an escape code starting with a backslash.
- '\a' is an alert such as a bell,
- '\b' is the backspace character,
- '\f' is the form feed character,
- '\n' is the newline character,
- '\r' is the carriage return character,
- '\t' is the horizontal tab character,
- '\v' is the vertical tab character,
- '\\' is the backslash character,
- '\'' is the single quote character
- '\"' is the double quote character.
A backslash followed by one or more octal digits represents the character whose octal representation is given. A backslash followed by any other character is that character. The mapping of escape codes to other characters is defined by the Sather implementation.
12.5.3 The string class, STR
| Examples: | s:STR := "a string literal" |
| | d:STR := "concat" "enation\015" |
| | -- d is "concatenation\015" |
STR objects represent strings. String literal expressions begin and end with double quote marks. A backslash starts an escape sequence as with character literals. All successive octal digits following a backslash are taken to define a single character. Individual string literals may not extend beyond a single line, but successive string literals are concated together. Thus, a break in a string literal can also be used to force the end of an octal encoded character. For example: "\0367" is a one character string, while "\03""67" is a three character string. Such segments may be separated by comments and whitespace.
12.5.4 Integers and the INT class
| Examples: | a:INT := 14; |
| | b:INT := -4532 |
| | c:INT := 39_8322_983_298 |
| | binary:INT := 0b101011; |
| | bin:INT := -0b_101010_1010 |
| | octal:ITN := 0o37323 |
| | hex_num:INT:= 0x_ea_75_67 |
INT objects represent machine integers. Integer literals can be represented in four bases: binary is base 2, octal is base 8, decimal is base 10 and hexadecimal is base 16. These are indicated by the prefixes: '0b', '0o', nothing, and '0x' respectively. Underscores may be used within integer literals to improve readability and are ignored. INT literals are only legal if they are in the representable range of the Sather implementation, which is at least 32 bits.
Underscores may be used to separate the digits of an integer to improve readability - this may be particularly useful for very long binary numbers.
12.5.5 Infinite precision integers and the INTI class
| Examples: | b:INTI := -4532i |
| | infinite_hex:INTI := 0o373254i |
Infinite precision integers are are implemetned by the INTI class and supported by a literal form which is essentially the same as that of integers, but with a trailing 'i'. All the standard arithmetic operations are defined on infinite precision integers.
12.5.6 Floating point numbers: the FLT and FLTD classes
| Examples: | f:FLT := 12.34 |
| | fd:FLTD := 3.498_239e-8d |
Syntax:
flt_literal_expression  [-] decimal_int . decimal_int [e [-] decimal_int] [ d ] [-] decimal_int . decimal_int [e [-] decimal_int] [ d ]
FLT and FLTD objects represent floating point numbers according to the single and double representations defined by the IEEE-754-1985 standard (see also page 143). A floating point literal is of type FLT unless suffixed by 'd' designating a FLTD literal. The optional 'e' portion is used to specify a power of 10 by which to multiply the decimal value. Underscores may be used within floating point literals to improve readability and are ignored. Literal values are only legal if they are within the range specified by the IEEE standard.
Sather does not do implicit type coercions (such as promoting an integer to floating point when used in a floating point context.) Types must instead be promoted explicitly by the programmer. This avoids a number of portability and precision issues (for example, when an integer can't be represented by the floating point representation.
The following two expressions are equivalent. In the first, the 'd' is a literal suffix denoting the type. In the second, '3.14' is the literal and '.fltd' is an explicit conversion.
| 3.14d -- A double precision literal
3.14.fltd -- Single, but converted |
|
12.6 Library Conventions
In addition to 'create', there are a number of other naming conventions:
- Classes which are related should reflect this in their names. For example, there are many examples in the library of an abstraction, classes implementing the abstraction, and code testing implementations of the abstraction. For example, in the standard library the set abstraction is named $SET, H_SET is a hash table implementation, and the test code is TEST_SET.
- Some classes implement an immutable, 'mathematical' abstraction (eg. integers), and others implement mutable "object" abstractions that can be modified in place (eg. arrays). For most objects, the mutable, object semantics are natural and efficient. However, for classes such as sets, the semantics may be different from those of the traditional mathematical set entities.
- Classes with immutable semantics are given their 'mathematical' names: STR, VEC, $SET. When separate abstractions exist to handle value and reference semantics, the method value will be provided in the reference version to provide an immutable snapshop of the reference class.
- Conversions from a type FOO to a type BAR occur in two ways: by defining an appropriate 'create(f:FOO):BAR' routine in BAR as seen above, or be defining a routine 'bar:BAR' in FOO. For example, in the standard library conversion of a FLT to a FLTD is done by calling the routine 'fltd:FLTD' defined in FLT.
- Methods which return a BOOL (called predicates), usually have the prefix 'is_'. For example, 'is_prime' tests integers for primality.
- Abstract classes that require a single method should be named after that method. For example, subtypes of $HASH define the method 'hash'.
- If there is a single iterator in a container class which returns all of the items, it should be named 'elt!'. If there is a single iterator which sets the items, it should be named 'set!'. In general, iterators should have singular ('elt!') rather than plural ('elts!') names if the choice is arbitrary.
12.6.1 Object Identity
Many languages provide built-in pointer and structural equality and comparison. To preserve encapsulation, in Sather these operations must go through the class interface like every method. The '=' symbol is syntactic sugar for a call to 'is_eq' (page 116). 'is_eq:BOOL' must be explicitly defined by the type of the left side for this syntax to be useful.
The SYS class (page 142) can be used to obtain equality based on pointer or structural notions of identity. This class also provides built-in mechanisms for comparison and hashing.
IS_EQ
Classes which define their own notion of equality should subtype from $IS_EQ. This class is a common parameter bound in container classes. In the standard library, we have
| abstract class $IS_EQ is
is_eq(e:$OB):BOOL;
end; |
|
Many classes define a notion of equality which is different than pointer equality. For example, two STR strings may be equal although, in general, strings are not unique.
| class STR < $IS_EQ is ...
is_eq(arg:$OB):BOOL is ... end;
...
end; -- class STR. |
|
Programmer defined hash functions and $HASH
Many container classes need to be able to compute hash values of their items. Just as with 'is_eq', classes may subtype from $HASH to indicate that they know how to compute their own hash value. $HASH is defined in the library to be
| abstract class $HASH is
hash:INT;
end; |
|
Objects that can be copied and $COPY
To preserve class encapsulation, Sather does not provide a built-in way to copy objects. By convention, objects are copied by a class-defined routine 'copy', and classes which provide this should subtype from $COPY. $COPY is defined in the standard library.
| .abstract class $COPY is
copy:SAME;
end; |
|
12.6.2 Nil and void
Reference class variables can be declared without being allocated. Unassigned reference or abstract type variables have the void value, indicating the non-existence of an object. However, for immutable types this unassigned value is not distinguished from other legitimate values; for example, the void of type INT is the value zero.
It is often algorithmically convenient to have a sentinel value which has a special interpretation. For example, hash tables often distinguish empty table entries without a separate bit indicating that an entry is empty. Because void is a legitimate value for immutable types, void can't be used as this sentinel value. For this reason, classes may define a 'nil' value to be used to represent the non-existence of an immutable object. Such classes subtype from $NIL and define the routines 'nil:SAME' and 'is_nil: BOOL'.
The 'nil' value is generally a rarely used or illegal value. For INT, it is the most negative representable integer. For floating point types, it is NaN. 'is_nil' is necessary because NaN is defined by IEEE to not be equal to itself.
| abstract class $NIL is
nil:SAME;
is_nil:BOOL;
end; -- anstract class $NIL |
|
[1] Frequently called the contravariant conformance rule to distinguish it from the more restrictive C++ rule of invariance and the unsafe Eiffel rule (of covariance in the argument types). Hence, the co- vs. contra variance debate just refers to the behavior of the argument types
[2] Efficiency in converting to FORTRAN was more important for mathematical entitites which will be used with existing mathematical libraries such as BLAS and LAPACK, most of which are in FORTRAN
[3] Earlier versions of Sather 1.0 defined separate routines for each of these operators.
[4] In fact, you can look at the tail half of the protect as a typecase on the exception object.
|